 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Equivariance in State-of-the-Art Supervised Depth and Normal Predictors
Sep 28, 2023



Dense depth and surface normal predictors should possess the equivariant property to cropping-and-resizing -- cropping the input image should result in cropping the same output image. However, we find that state-of-the-art depth and normal predictors, despite having strong performances, surprisingly do not respect equivariance. The problem exists even when crop-and-resize data augmentation is employed during training. To remedy this, we propose an equivariant regularization technique, consisting of an averaging procedure and a self-consistency loss, to explicitly promote cropping-and-resizing equivariance in depth and normal networks. Our approach can be applied to both CNN and Transformer architectures, does not incur extra cost during testing, and notably improves the supervised and semi-supervised learning performance of dense predictors on Taskonomy tasks. Finally, finetuning with our loss on unlabeled images improves not only equivariance but also accuracy of state-of-the-art depth and normal predictors when evaluated on NYU-v2. GitHub link: https://github.com/mikuhatsune/equivariance
Do Pre-trained Models Benefit Equally in Continual Learning?
Oct 27, 2022



Existing work on continual learning (CL) is primarily devoted to developing algorithms for models trained from scratch. Despite their encouraging performance on contrived benchmarks, these algorithms show dramatic performance drops in real-world scenarios. Therefore, this paper advocates the systematic introduction of pre-training to CL, which is a general recipe for transferring knowledge to downstream tasks but is substantially missing in the CL community. Our investigation reveals the multifaceted complexity of exploiting pre-trained models for CL, along three different axes, pre-trained models, CL algorithms, and CL scenarios. Perhaps most intriguingly, improvements in CL algorithms from pre-training are very inconsistent an underperforming algorithm could become competitive and even state-of-the-art when all algorithms start from a pre-trained model. This indicates that the current paradigm, where all CL methods are compared in from-scratch training, is not well reflective of the true CL objective and desired progress. In addition, we make several other important observations, including that CL algorithms that exert less regularization benefit more from a pre-trained model; and that a stronger pre-trained model such as CLIP does not guarantee a better improvement. Based on these findings, we introduce a simple yet effective baseline that employs minimum regularization and leverages the more beneficial pre-trained model, coupled with a two-stage training pipeline. We recommend including this strong baseline in the future development of CL algorithms, due to its demonstrated state-of-the-art performance.
Is Self-Supervised Learning More Robust Than Supervised Learning?
Jun 10, 2022

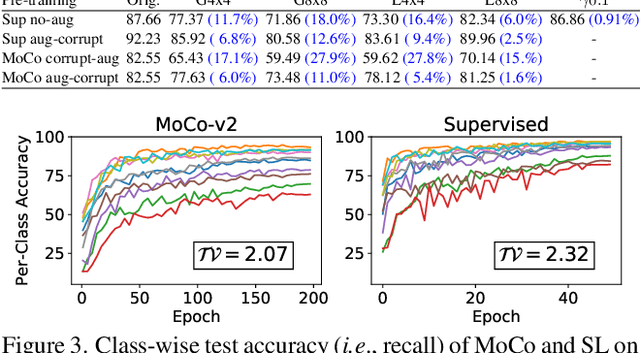

Self-supervised contrastive learning is a powerful tool to learn visual representation without labels. Prior work has primarily focused on evaluating the recognition accuracy of various pre-training algorithms, but has overlooked other behavioral aspects. In addition to accuracy, distributional robustness plays a critical role in the reliability of machine learning models. We design and conduct a series of robustness tests to quantify the behavioral differences between contrastive learning and supervised learning to downstream or pre-training data distribution changes. These tests leverage data corruptions at multiple levels, ranging from pixel-level gamma distortion to patch-level shuffling and to dataset-level distribution shift. Our tests unveil intriguing robustness behaviors of contrastive and supervised learning. On the one hand, under downstream corruptions, we generally observe that contrastive learning is surprisingly more robust than supervised learning. On the other hand, under pre-training corruptions, we find contrastive learning vulnerable to patch shuffling and pixel intensity change, yet less sensitive to dataset-level distribution change. We attempt to explain these results through the role of data augmentation and feature space properties. Our insight has implications in improving the downstream robustness of supervised learning.
SIRfyN: Single Image Relighting from your Neighbors
Dec 08, 2021
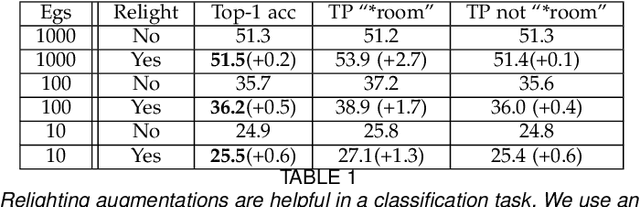
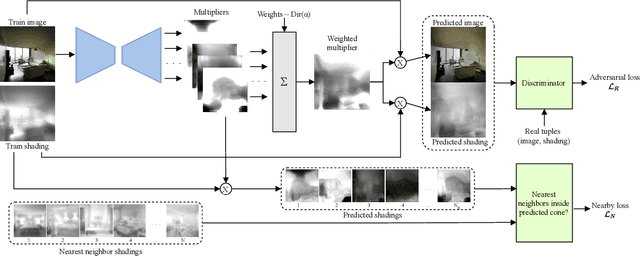
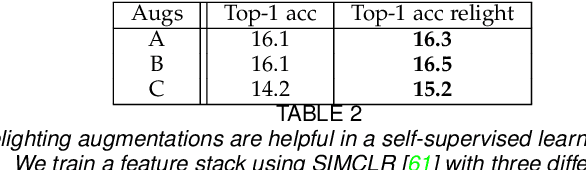
We show how to relight a scene, depicted in a single image, such that (a) the overall shading has changed and (b) the resulting image looks like a natural image of that scene. Applications for such a procedure include generating training data and building authoring environments. Naive methods for doing this fail. One reason is that shading and albedo are quite strongly related; for example, sharp boundaries in shading tend to appear at depth discontinuities, which usually apparent in albedo. The same scene can be lit in different ways, and established theory shows the different lightings form a cone (the illumination cone). Novel theory shows that one can use similar scenes to estimate the different lightings that apply to a given scene, with bounded expected error. Our method exploits this theory to estimate a representation of the available lighting fields in the form of imputed generators of the illumination cone. Our procedure does not require expensive "inverse graphics" datasets, and sees no ground truth data of any kind. Qualitative evaluation suggests the method can erase and restore soft indoor shadows, and can "steer" light around a scene. We offer a summary quantitative evaluation of the method with a novel application of the FID. An extension of the FID allows per-generated-image evaluation. Furthermore, we offer qualitative evaluation with a user study, and show that our method produces images that can successfully be used for data augmentation.
Pixel Contrastive-Consistent Semi-Supervised Semantic Segmentation
Aug 20, 2021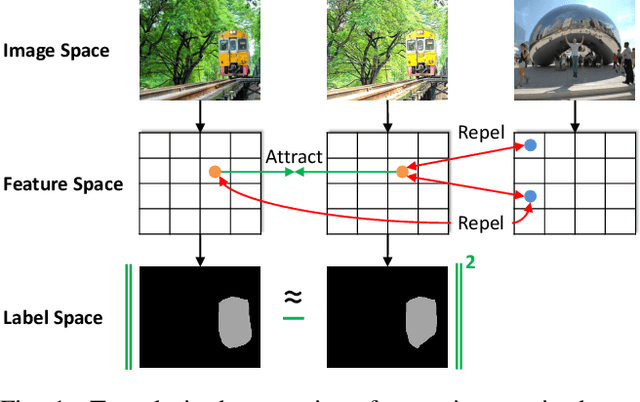
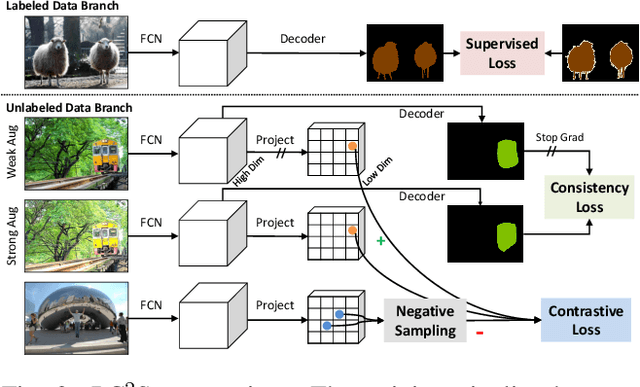
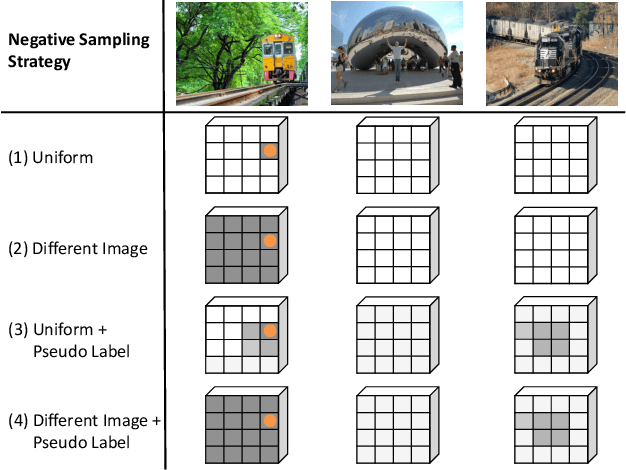

We present a novel semi-supervised semantic segmentation method which jointly achieves two desiderata of segmentation model regularities: the label-space consistency property between image augmentations and the feature-space contrastive property among different pixels. We leverage the pixel-level L2 loss and the pixel contrastive loss for the two purposes respectively. To address the computational efficiency issue and the false negative noise issue involved in the pixel contrastive loss, we further introduce and investigate several negative sampling techniques. Extensive experiments demonstrate the state-of-the-art performance of our method (PC2Seg) with the DeepLab-v3+ architecture, in several challenging semi-supervised settings derived from the VOC, Cityscapes, and COCO datasets.
Coordinate-wise Control Variates for Deep Policy Gradients
Aug 11, 2021

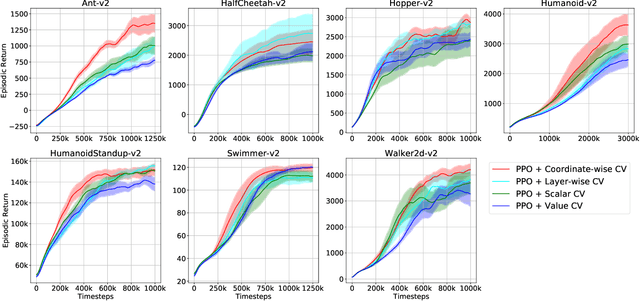

The control variates (CV) method is widely used in policy gradient estimation to reduce the variance of the gradient estimators in practice. A control variate is applied by subtracting a baseline function from the state-action value estimates. Then the variance-reduced policy gradient presumably leads to higher learning efficiency. Recent research on control variates with deep neural net policies mainly focuses on scalar-valued baseline functions. The effect of vector-valued baselines is under-explored. This paper investigates variance reduction with coordinate-wise and layer-wise control variates constructed from vector-valued baselines for neural net policies. We present experimental evidence suggesting that lower variance can be obtained with such baselines than with the conventional scalar-valued baseline. We demonstrate how to equip the popular Proximal Policy Optimization (PPO) algorithm with these new control variates. We show that the resulting algorithm with proper regularization can achieve higher sample efficiency than scalar control variates in continuous control benchmarks.
DAP: Detection-Aware Pre-training with Weak Supervision
Mar 30, 2021


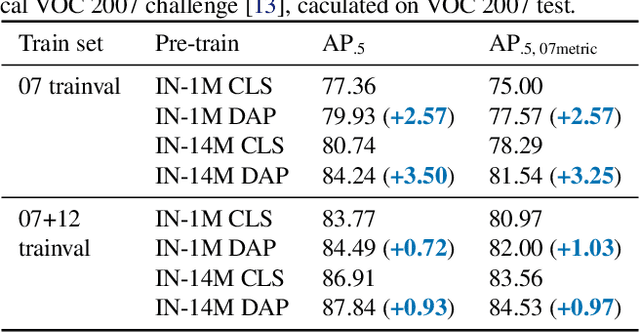
This paper presents a detection-aware pre-training (DAP) approach, which leverages only weakly-labeled classification-style datasets (e.g., ImageNet) for pre-training, but is specifically tailored to benefit object detection tasks. In contrast to the widely used image classification-based pre-training (e.g., on ImageNet), which does not include any location-related training tasks, we transform a classification dataset into a detection dataset through a weakly supervised object localization method based on Class Activation Maps to directly pre-train a detector, making the pre-trained model location-aware and capable of predicting bounding boxes. We show that DAP can outperform the traditional classification pre-training in terms of both sample efficiency and convergence speed in downstream detection tasks including VOC and COCO. In particular, DAP boosts the detection accuracy by a large margin when the number of examples in the downstream task is small.
Shaping Deep Feature Space towards Gaussian Mixture for Visual Classification
Nov 18, 2020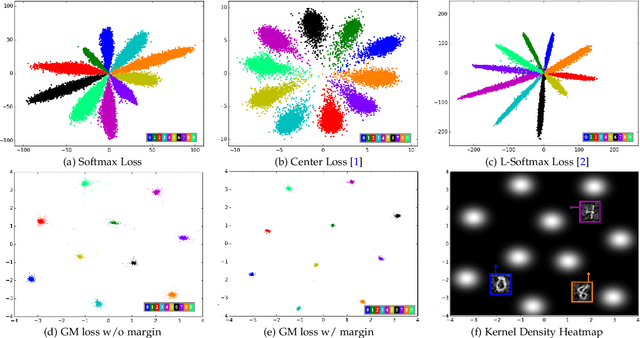
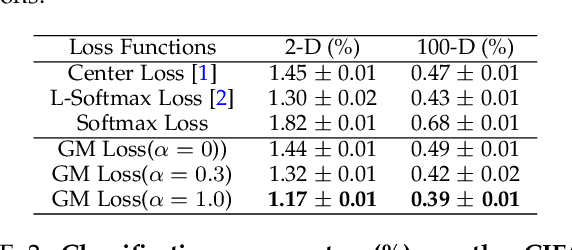
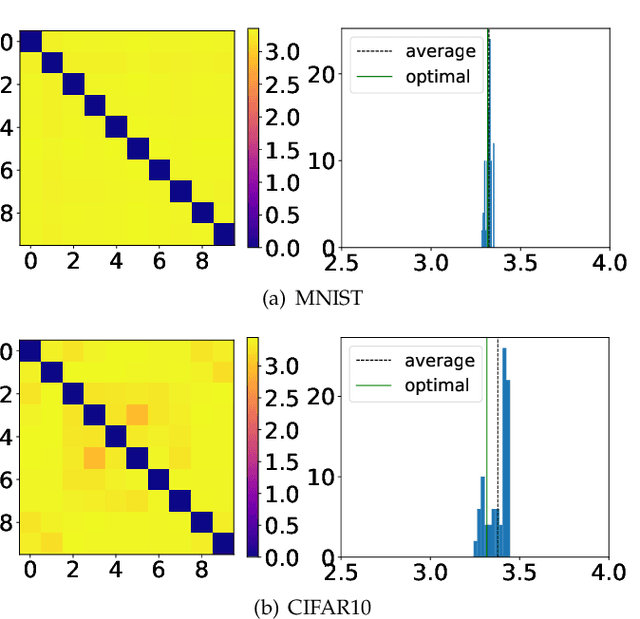
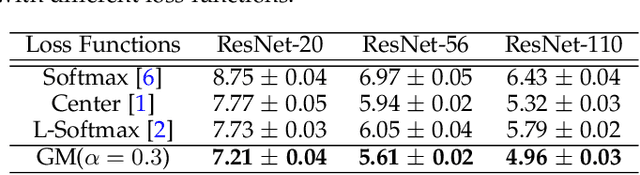
The softmax cross-entropy loss function has been widely used to train deep models for various tasks. In this work, we propose a Gaussian mixture (GM) loss function for deep neural networks for visual classification. Unlike the softmax cross-entropy loss, our method explicitly shapes the deep feature space towards a Gaussian Mixture distribution. With a classification margin and a likelihood regularization, the GM loss facilitates both high classification performance and accurate modeling of the feature distribution. The GM loss can be readily used to distinguish abnormal inputs, such as the adversarial examples, based on the discrepancy between feature distributions of the inputs and the training set. Furthermore, theoretical analysis shows that a symmetric feature space can be achieved by using the GM loss, which enables the models to perform robustly against adversarial attacks. The proposed model can be implemented easily and efficiently without using extra trainable parameters. Extensive evaluations demonstrate that the proposed method performs favorably not only on image classification but also on robust detection of adversarial examples generated by strong attacks under different threat models.
Efficient Competitive Self-Play Policy Optimization
Sep 13, 2020


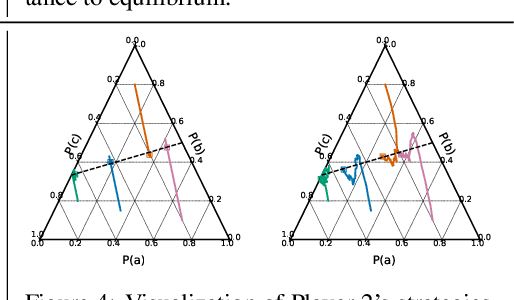
Reinforcement learning from self-play has recently reported many successes. Self-play, where the agents compete with themselves, is often used to generate training data for iterative policy improvement. In previous work, heuristic rules are designed to choose an opponent for the current learner. Typical rules include choosing the latest agent, the best agent, or a random historical agent. However, these rules may be inefficient in practice and sometimes do not guarantee convergence even in the simplest matrix games. In this paper, we propose a new algorithmic framework for competitive self-play reinforcement learning in two-player zero-sum games. We recognize the fact that the Nash equilibrium coincides with the saddle point of the stochastic payoff function, which motivates us to borrow ideas from classical saddle point optimization literature. Our method trains several agents simultaneously, and intelligently takes each other as opponent based on simple adversarial rules derived from a principled perturbation-based saddle optimization method. We prove theoretically that our algorithm converges to an approximate equilibrium with high probability in convex-concave games under standard assumptions. Beyond the theory, we further show the empirical superiority of our method over baseline methods relying on the aforementioned opponent-selection heuristics in matrix games, grid-world soccer, Gomoku, and simulated robot sumo, with neural net policy function approximators.
Boosting Weakly Supervised Object Detection with Progressive Knowledge Transfer
Jul 15, 2020

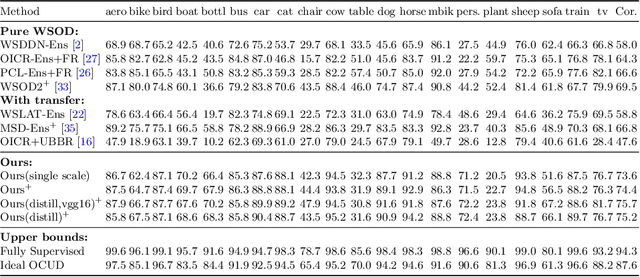

In this paper, we propose an effective knowledge transfer framework to boost the weakly supervised object detection accuracy with the help of an external fully-annotated source dataset, whose categories may not overlap with the target domain. This setting is of great practical value due to the existence of many off-the-shelf detection datasets. To more effectively utilize the source dataset, we propose to iteratively transfer the knowledge from the source domain by a one-class universal detector and learn the target-domain detector. The box-level pseudo ground truths mined by the target-domain detector in each iteration effectively improve the one-class universal detector. Therefore, the knowledge in the source dataset is more thoroughly exploited and leveraged. Extensive experiments are conducted with Pascal VOC 2007 as the target weakly-annotated dataset and COCO/ImageNet as the source fully-annotated dataset. With the proposed solution, we achieved an mAP of $59.7\%$ detection performance on the VOC test set and an mAP of $60.2\%$ after retraining a fully supervised Faster RCNN with the mined pseudo ground truths. This is significantly better than any previously known results in related literature and sets a new state-of-the-art of weakly supervised object detection under the knowledge transfer setting. Code: \url{https://github.com/mikuhatsune/wsod_transfer}.