 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Blocks World: Moving Things Around in Pictures
Jun 25, 2025We describe Generative Blocks World to interact with the scene of a generated image by manipulating simple geometric abstractions. Our method represents scenes as assemblies of convex 3D primitives, and the same scene can be represented by different numbers of primitives, allowing an editor to move either whole structures or small details. Once the scene geometry has been edited, the image is generated by a flow-based method which is conditioned on depth and a texture hint. Our texture hint takes into account the modified 3D primitives, exceeding texture-consistency provided by existing key-value caching techniques. These texture hints (a) allow accurate object and camera moves and (b) largely preserve the identity of objects depicted. Quantitative and qualitative experiments demonstrate that our approach outperforms prior works in visual fidelity, editability, and compositional generalization.
Zero-Shot Low Light Image Enhancement with Diffusion Prior
Dec 18, 2024



Balancing aesthetic quality with fidelity when enhancing images from challenging, degraded sources is a core objective in computational photography. In this paper, we address low light image enhancement (LLIE), a task in which dark images often contain limited visible information. Diffusion models, known for their powerful image enhancement capacities, are a natural choice for this problem. However, their deep generative priors can also lead to hallucinations, introducing non-existent elements or substantially altering the visual semantics of the original scene. In this work, we introduce a novel zero-shot method for controlling and refining the generative behavior of diffusion models for dark-to-light image conversion tasks. Our method demonstrates superior performance over existing state-of-the-art methods in the task of low-light image enhancement, as evidenced by both quantitative metrics and qualitative analysis.
Shadows Don't Lie and Lines Can't Bend! Generative Models don't know Projective Geometryfor now
Nov 28, 2023



Generative models can produce impressively realistic images. This paper demonstrates that generated images have geometric features different from those of real images. We build a set of collections of generated images, prequalified to fool simple, signal-based classifiers into believing they are real. We then show that prequalified generated images can be identified reliably by classifiers that only look at geometric properties. We use three such classifiers. All three classifiers are denied access to image pixels, and look only at derived geometric features. The first classifier looks at the perspective field of the image, the second looks at lines detected in the image, and the third looks at relations between detected objects and shadows. Our procedure detects generated images more reliably than SOTA local signal based detectors, for images from a number of distinct generators. Saliency maps suggest that the classifiers can identify geometric problems reliably. We conclude that current generators cannot reliably reproduce geometric properties of real images.
StyleGAN knows Normal, Depth, Albedo, and More
Jun 01, 2023Intrinsic images, in the original sense, are image-like maps of scene properties like depth, normal, albedo or shading. This paper demonstrates that StyleGAN can easily be induced to produce intrinsic images. The procedure is straightforward. We show that, if StyleGAN produces $G({w})$ from latents ${w}$, then for each type of intrinsic image, there is a fixed offset ${d}_c$ so that $G({w}+{d}_c)$ is that type of intrinsic image for $G({w})$. Here ${d}_c$ is {\em independent of ${w}$}. The StyleGAN we used was pretrained by others, so this property is not some accident of our training regime. We show that there are image transformations StyleGAN will {\em not} produce in this fashion, so StyleGAN is not a generic image regression engine. It is conceptually exciting that an image generator should ``know'' and represent intrinsic images. There may also be practical advantages to using a generative model to produce intrinsic images. The intrinsic images obtained from StyleGAN compare well both qualitatively and quantitatively with those obtained by using SOTA image regression techniques; but StyleGAN's intrinsic images are robust to relighting effects, unlike SOTA methods.
Make It So: Steering StyleGAN for Any Image Inversion and Editing
Apr 27, 2023StyleGAN's disentangled style representation enables powerful image editing by manipulating the latent variables, but accurately mapping real-world images to their latent variables (GAN inversion) remains a challenge. Existing GAN inversion methods struggle to maintain editing directions and produce realistic results. To address these limitations, we propose Make It So, a novel GAN inversion method that operates in the $\mathcal{Z}$ (noise) space rather than the typical $\mathcal{W}$ (latent style) space. Make It So preserves editing capabilities, even for out-of-domain images. This is a crucial property that was overlooked in prior methods. Our quantitative evaluations demonstrate that Make It So outperforms the state-of-the-art method PTI~\cite{roich2021pivotal} by a factor of five in inversion accuracy and achieves ten times better edit quality for complex indoor scenes.
Enriching StyleGAN with Illumination Physics
May 20, 2022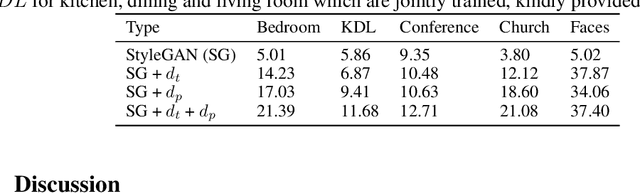
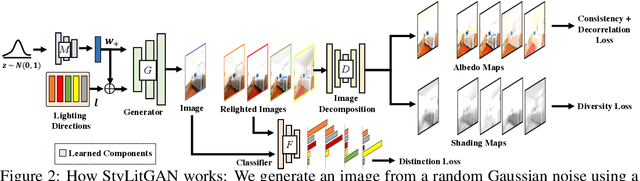


StyleGAN generates novel images of a scene from latent codes which are impressively disentangled. But StyleGAN generates images that are "like" its training set. This paper shows how to use simple physical properties of images to enrich StyleGAN's generation capacity. We use an intrinsic image method to decompose an image, then search the latent space of a pretrained StyleGAN to find novel directions that fix one component (say, albedo) and vary another (say, shading). Therefore, we can change the lighting of a complex scene without changing the scene layout, object colors, and shapes. Or we can change the colors of objects without changing shading intensity or their scene layout. Our experiments suggest the proposed method, StyLitGAN, can add and remove luminaires in the scene and generate images with realistic lighting effects -- cast shadows, soft shadows, inter-reflections, glossy effects -- requiring no labeled paired relighting data or any other geometric supervision. Qualitative evaluation confirms that our generated images are realistic and that we can change or fix components at will. Quantitative evaluation shows that pre-trained StyleGAN could not produce the images StyLitGAN produces; we can automatically generate realistic out-of-distribution images, and so can significantly enrich the range of images StyleGAN can produce.
SIRfyN: Single Image Relighting from your Neighbors
Dec 08, 2021
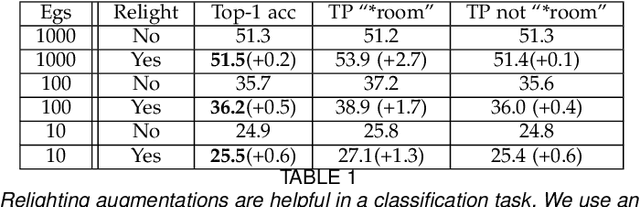
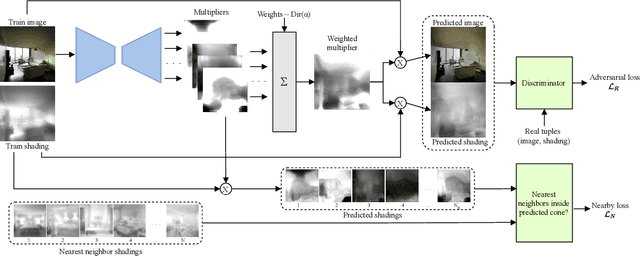
We show how to relight a scene, depicted in a single image, such that (a) the overall shading has changed and (b) the resulting image looks like a natural image of that scene. Applications for such a procedure include generating training data and building authoring environments. Naive methods for doing this fail. One reason is that shading and albedo are quite strongly related; for example, sharp boundaries in shading tend to appear at depth discontinuities, which usually apparent in albedo. The same scene can be lit in different ways, and established theory shows the different lightings form a cone (the illumination cone). Novel theory shows that one can use similar scenes to estimate the different lightings that apply to a given scene, with bounded expected error. Our method exploits this theory to estimate a representation of the available lighting fields in the form of imputed generators of the illumination cone. Our procedure does not require expensive "inverse graphics" datasets, and sees no ground truth data of any kind. Qualitative evaluation suggests the method can erase and restore soft indoor shadows, and can "steer" light around a scene. We offer a summary quantitative evaluation of the method with a novel application of the FID. An extension of the FID allows per-generated-image evaluation. Furthermore, we offer qualitative evaluation with a user study, and show that our method produces images that can successfully be used for data augmentation.
Intrinsic Image Decomposition using Paradigms
Nov 20, 2020
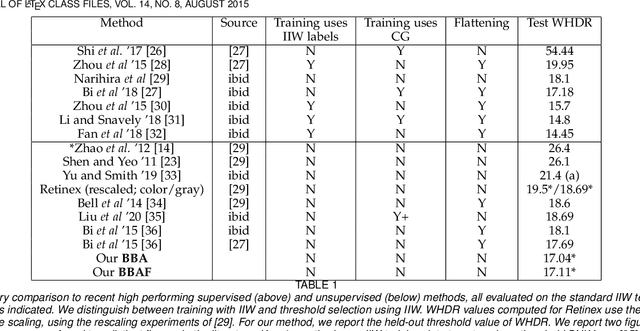


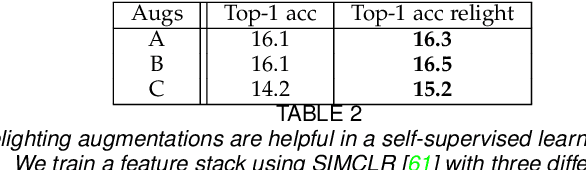
Intrinsic image decomposition is the classical task of mapping image to albedo. The WHDR dataset allows methods to be evaluated by comparing predictions to human judgements ("lighter", "same as", "darker"). The best modern intrinsic image methods learn a map from image to albedo using rendered models and human judgements. This is convenient for practical methods, but cannot explain how a visual agent without geometric, surface and illumination models and a renderer could learn to recover intrinsic images. This paper describes a method that learns intrinsic image decomposition without seeing WHDR annotations, rendered data, or ground truth data. The method relies on paradigms - fake albedos and fake shading fields - together with a novel smoothing procedure that ensures good behavior at short scales on real images. Long scale error is controlled by averaging. Our method achieves WHDR scores competitive with those of strong recent methods allowed to see training WHDR annotations, rendered data, and ground truth data. Because our method is unsupervised, we can compute estimates of the test/train variance of WHDR scores; these are quite large, and it is unsafe to rely small differences in reported WHDR.
Diverse and Controllable Image Captioning with Part-of-Speech Guidance
May 31, 2018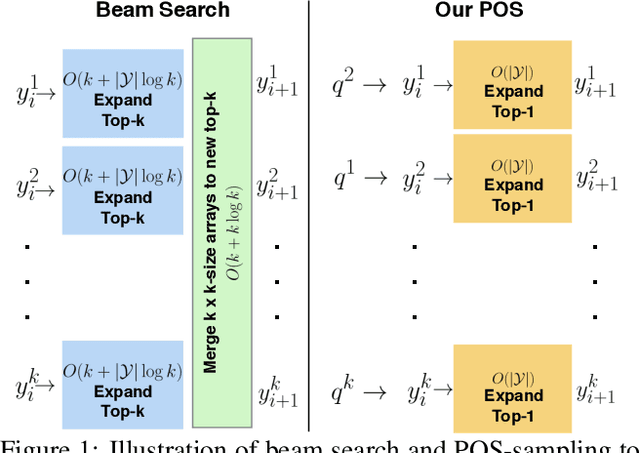
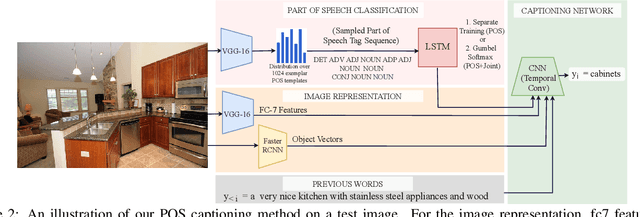
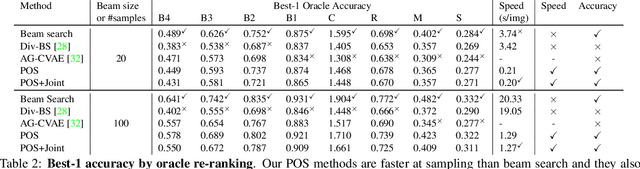
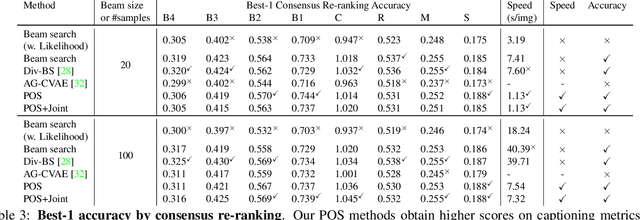
Automatically describing an image is an important capability for virtual assistants. Significant progress has been achieved in recent years on this task of image captioning. However, classical prediction techniques based on maximum likelihood trained LSTM nets don't embrace the inherent ambiguity of image captioning. To address this concern, recent variational auto-encoder and generative adversarial network based methods produce a set of captions by sampling from an abstract latent space. But, this latent space has limited interpretability and therefore, a control mechanism for captioning remains an open problem. This paper proposes a captioning technique conditioned on part-of-speech. Our method provides human interpretable control in form of part-of-speech. Importantly, part-of-speech is a language prior, and conditioning on it provides: (i) more diversity as evaluated by counting n-grams and the novel sentences generated, (ii) achieves high accuracy for the diverse captions on standard captioning metrics.
Quantitative Evaluation of Style Transfer
Mar 31, 2018

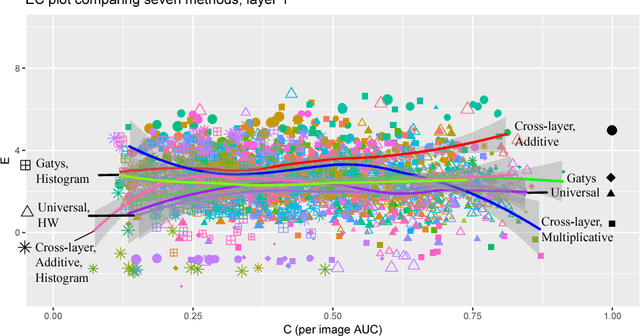
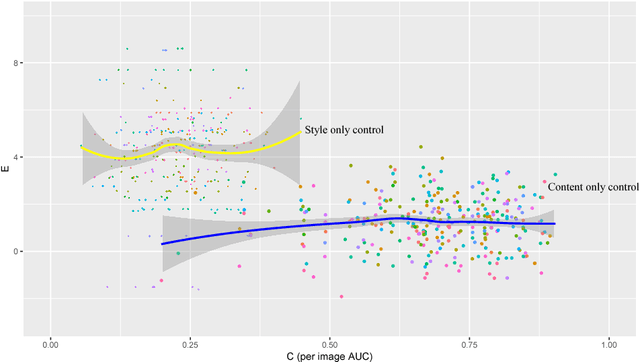
Style transfer methods produce a transferred image which is a rendering of a content image in the manner of a style image. There is a rich literature of variant methods. However, evaluation procedures are qualitative, mostly involving user studies. We describe a novel quantitative evaluation procedure. One plots effectiveness (a measure of the extent to which the style was transferred) against coherence (a measure of the extent to which the transferred image decomposes into objects in the same way that the content image does) to obtain an EC plot. We construct EC plots comparing a number of recent style transfer methods. Most methods control within-layer gram matrices, but we also investigate a method that controls cross-layer gram matrices. These EC plots reveal a number of intriguing properties of recent style transfer methods. The style used has a strong effect on the outcome, for all methods. Using large style weights does not necessarily improve effectiveness, and can produce worse results. Cross-layer gram matrices easily beat all other methods, but some styles remain difficult for all methods. Ensemble methods show real promise. It is likely that, for current methods, each style requires a different choice of weights to obtain the best results, so that automated weight setting methods are desirable. Finally, we show evidence comparing our EC evaluations to human evaluations.