 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage-Guided Music Recommendation for Video via Prompt Analogies
Jun 15, 2023



We propose a method to recommend music for an input video while allowing a user to guide music selection with free-form natural language. A key challenge of this problem setting is that existing music video datasets provide the needed (video, music) training pairs, but lack text descriptions of the music. This work addresses this challenge with the following three contributions. First, we propose a text-synthesis approach that relies on an analogy-based prompting procedure to generate natural language music descriptions from a large-scale language model (BLOOM-176B) given pre-trained music tagger outputs and a small number of human text descriptions. Second, we use these synthesized music descriptions to train a new trimodal model, which fuses text and video input representations to query music samples. For training, we introduce a text dropout regularization mechanism which we show is critical to model performance. Our model design allows for the retrieved music audio to agree with the two input modalities by matching visual style depicted in the video and musical genre, mood, or instrumentation described in the natural language query. Third, to evaluate our approach, we collect a testing dataset for our problem by annotating a subset of 4k clips from the YT8M-MusicVideo dataset with natural language music descriptions which we make publicly available. We show that our approach can match or exceed the performance of prior methods on video-to-music retrieval while significantly improving retrieval accuracy when using text guidance.
StyleGAN knows Normal, Depth, Albedo, and More
Jun 01, 2023Intrinsic images, in the original sense, are image-like maps of scene properties like depth, normal, albedo or shading. This paper demonstrates that StyleGAN can easily be induced to produce intrinsic images. The procedure is straightforward. We show that, if StyleGAN produces $G({w})$ from latents ${w}$, then for each type of intrinsic image, there is a fixed offset ${d}_c$ so that $G({w}+{d}_c)$ is that type of intrinsic image for $G({w})$. Here ${d}_c$ is {\em independent of ${w}$}. The StyleGAN we used was pretrained by others, so this property is not some accident of our training regime. We show that there are image transformations StyleGAN will {\em not} produce in this fashion, so StyleGAN is not a generic image regression engine. It is conceptually exciting that an image generator should ``know'' and represent intrinsic images. There may also be practical advantages to using a generative model to produce intrinsic images. The intrinsic images obtained from StyleGAN compare well both qualitatively and quantitatively with those obtained by using SOTA image regression techniques; but StyleGAN's intrinsic images are robust to relighting effects, unlike SOTA methods.
Robust Online Video Instance Segmentation with Track Queries
Nov 16, 2022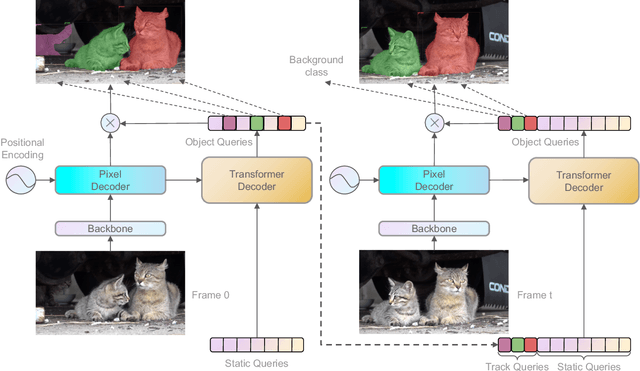
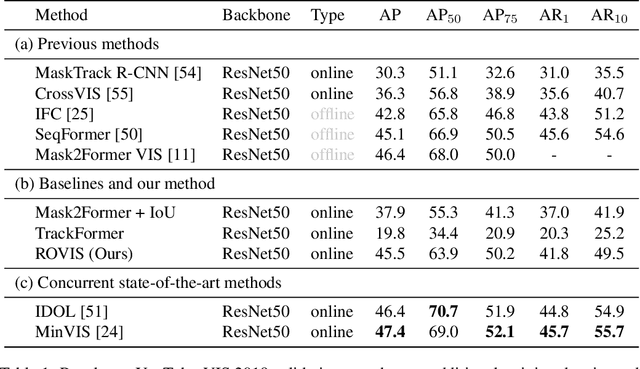

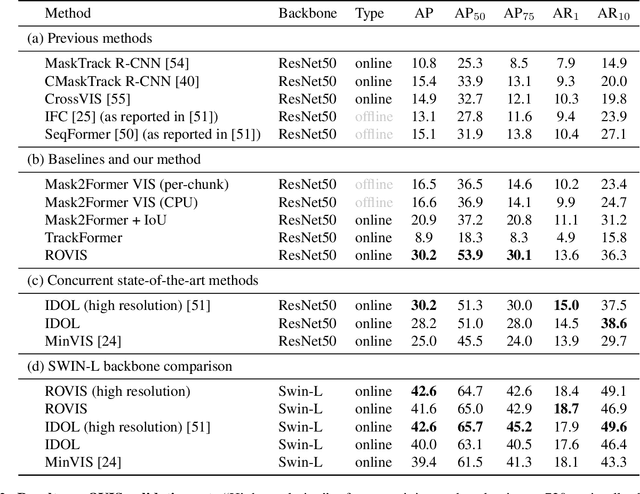
Recently, transformer-based methods have achieved impressive results on Video Instance Segmentation (VIS). However, most of these top-performing methods run in an offline manner by processing the entire video clip at once to predict instance mask volumes. This makes them incapable of handling the long videos that appear in challenging new video instance segmentation datasets like UVO and OVIS. We propose a fully online transformer-based video instance segmentation model that performs comparably to top offline methods on the YouTube-VIS 2019 benchmark and considerably outperforms them on UVO and OVIS. This method, called Robust Online Video Segmentation (ROVIS), augments the Mask2Former image instance segmentation model with track queries, a lightweight mechanism for carrying track information from frame to frame, originally introduced by the TrackFormer method for multi-object tracking. We show that, when combined with a strong enough image segmentation architecture, track queries can exhibit impressive accuracy while not being constrained to short videos.
Transfer of Representations to Video Label Propagation: Implementation Factors Matter
Mar 10, 2022
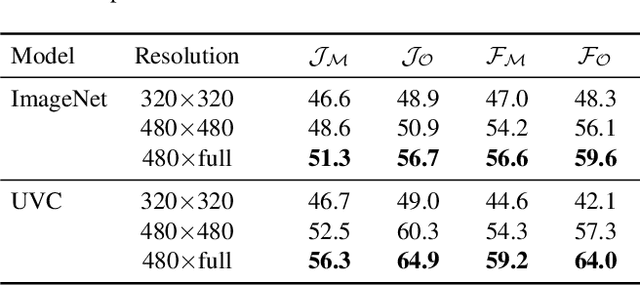
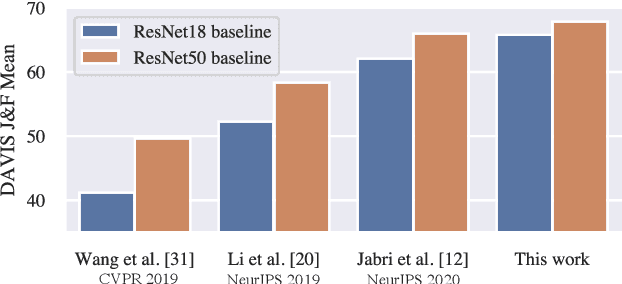
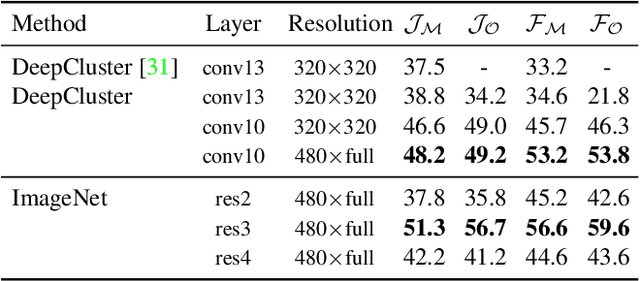
This work studies feature representations for dense label propagation in video, with a focus on recently proposed methods that learn video correspondence using self-supervised signals such as colorization or temporal cycle consistency. In the literature, these methods have been evaluated with an array of inconsistent settings, making it difficult to discern trends or compare performance fairly. Starting with a unified formulation of the label propagation algorithm that encompasses most existing variations, we systematically study the impact of important implementation factors in feature extraction and label propagation. Along the way, we report the accuracies of properly tuned supervised and unsupervised still image baselines, which are higher than those found in previous works. We also demonstrate that augmenting video-based correspondence cues with still-image-based ones can further improve performance. We then attempt a fair comparison of recent video-based methods on the DAVIS benchmark, showing convergence of best methods to performance levels near our strong ImageNet baseline, despite the usage of a variety of specialized video-based losses and training particulars. Additional comparisons on JHMDB and VIP datasets confirm the similar performance of current methods. We hope that this study will help to improve evaluation practices and better inform future research directions in temporal correspondence.
Multi-Object Tracking with Hallucinated and Unlabeled Videos
Aug 19, 2021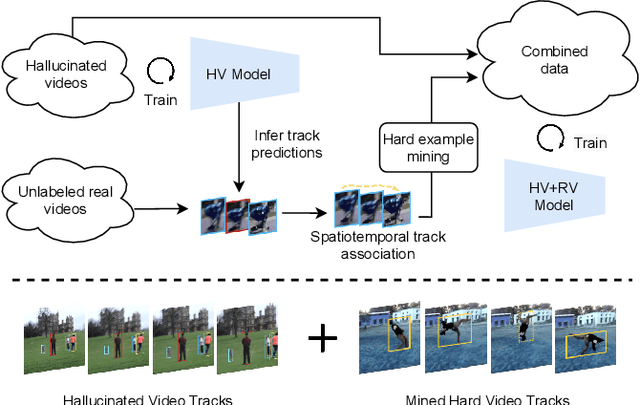
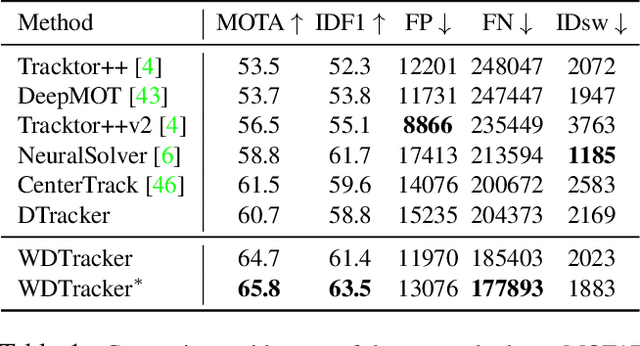


In this paper, we explore learning end-to-end deep neural trackers without tracking annotations. This is important as large-scale training data is essential for training deep neural trackers while tracking annotations are expensive to acquire. In place of tracking annotations, we first hallucinate videos from images with bounding box annotations using zoom-in/out motion transformations to obtain free tracking labels. We add video simulation augmentations to create a diverse tracking dataset, albeit with simple motion. Next, to tackle harder tracking cases, we mine hard examples across an unlabeled pool of real videos with a tracker trained on our hallucinated video data. For hard example mining, we propose an optimization-based connecting process to first identify and then rectify hard examples from the pool of unlabeled videos. Finally, we train our tracker jointly on hallucinated data and mined hard video examples. Our weakly supervised tracker achieves state-of-the-art performance on the MOT17 and TAO-person datasets. On MOT17, we further demonstrate that the combination of our self-generated data and the existing manually-annotated data leads to additional improvements.
Dressing in Order: Recurrent Person Image Generation for Pose Transfer, Virtual Try-on and Outfit Editing
Apr 14, 2021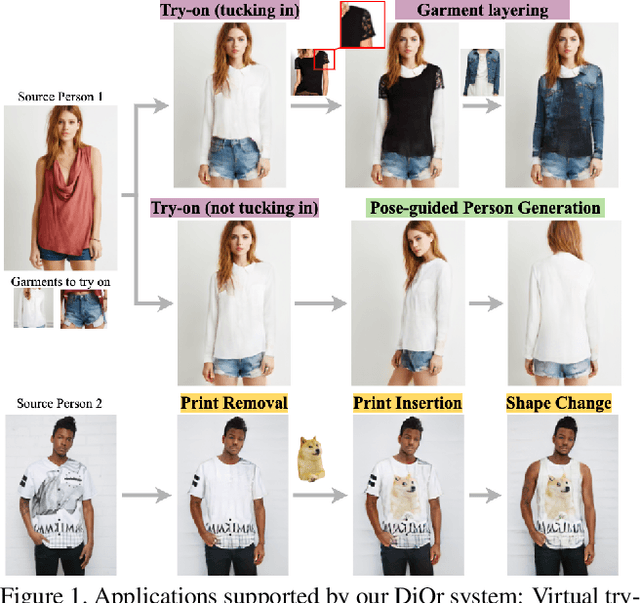
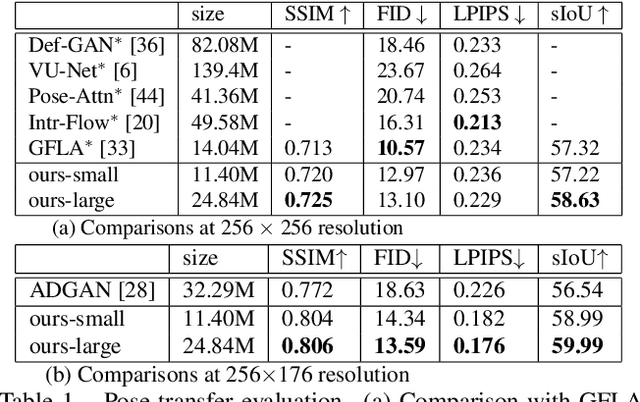


This paper proposes a flexible person generation framework called Dressing in Order (DiOr), which supports 2D pose transfer, virtual try-on, and several fashion editing tasks. Key to DiOr is a novel recurrent generation pipeline to sequentially put garments on a person, so that trying on the same garments in different orders will result in different looks. Our system can produce dressing effects not achievable by existing work, including different interactions of garments (e.g., wearing a top tucked into the bottom or over it), as well as layering of multiple garments of the same type (e.g., jacket over shirt over t-shirt). DiOr explicitly encodes the shape and texture of each garment, enabling these elements to be edited separately. Joint training on pose transfer and inpainting helps with detail preservation and coherence of generated garments. Extensive evaluations show that DiOr outperforms other recent methods like ADGAN in terms of output quality, and handles a wide range of editing functions for which there is no direct supervision.