 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Multi-Object Tracking with Path Consistency
Apr 08, 2024In this paper, we propose a novel concept of path consistency to learn robust object matching without using manual object identity supervision. Our key idea is that, to track a object through frames, we can obtain multiple different association results from a model by varying the frames it can observe, i.e., skipping frames in observation. As the differences in observations do not alter the identities of objects, the obtained association results should be consistent. Based on this rationale, we generate multiple observation paths, each specifying a different set of frames to be skipped, and formulate the Path Consistency Loss that enforces the association results are consistent across different observation paths. We use the proposed loss to train our object matching model with only self-supervision. By extensive experiments on three tracking datasets (MOT17, PersonPath22, KITTI), we demonstrate that our method outperforms existing unsupervised methods with consistent margins on various evaluation metrics, and even achieves performance close to supervised methods.
SkeleTR: Towrads Skeleton-based Action Recognition in the Wild
Sep 20, 2023



We present SkeleTR, a new framework for skeleton-based action recognition. In contrast to prior work, which focuses mainly on controlled environments, we target more general scenarios that typically involve a variable number of people and various forms of interaction between people. SkeleTR works with a two-stage paradigm. It first models the intra-person skeleton dynamics for each skeleton sequence with graph convolutions, and then uses stacked Transformer encoders to capture person interactions that are important for action recognition in general scenarios. To mitigate the negative impact of inaccurate skeleton associations, SkeleTR takes relative short skeleton sequences as input and increases the number of sequences. As a unified solution, SkeleTR can be directly applied to multiple skeleton-based action tasks, including video-level action classification, instance-level action detection, and group-level activity recognition. It also enables transfer learning and joint training across different action tasks and datasets, which result in performance improvement. When evaluated on various skeleton-based action recognition benchmarks, SkeleTR achieves the state-of-the-art performance.
Object-Centric Multiple Object Tracking
Sep 05, 2023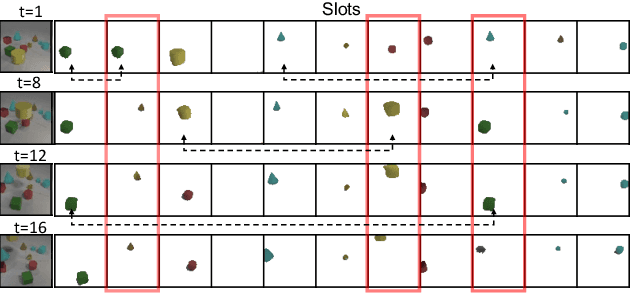
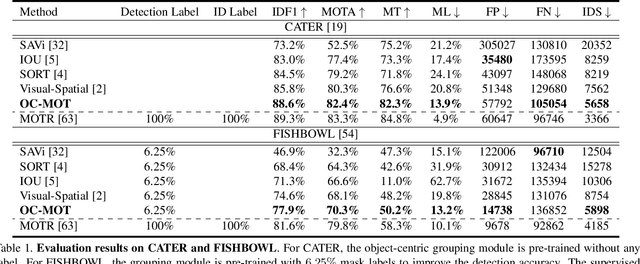
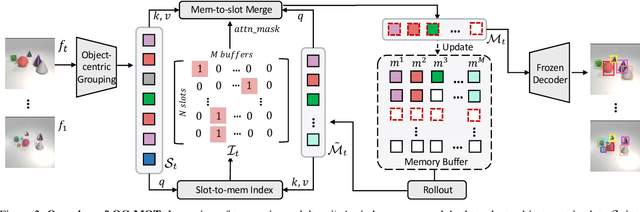
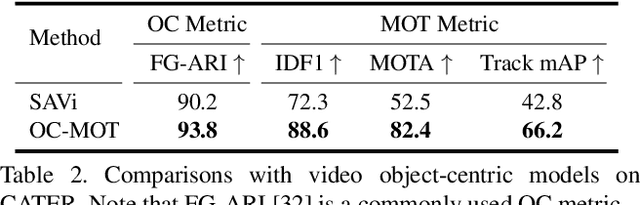
Unsupervised object-centric learning methods allow the partitioning of scenes into entities without additional localization information and are excellent candidates for reducing the annotation burden of multiple-object tracking (MOT) pipelines. Unfortunately, they lack two key properties: objects are often split into parts and are not consistently tracked over time. In fact, state-of-the-art models achieve pixel-level accuracy and temporal consistency by relying on supervised object detection with additional ID labels for the association through time. This paper proposes a video object-centric model for MOT. It consists of an index-merge module that adapts the object-centric slots into detection outputs and an object memory module that builds complete object prototypes to handle occlusions. Benefited from object-centric learning, we only require sparse detection labels (0%-6.25%) for object localization and feature binding. Relying on our self-supervised Expectation-Maximization-inspired loss for object association, our approach requires no ID labels. Our experiments significantly narrow the gap between the existing object-centric model and the fully supervised state-of-the-art and outperform several unsupervised trackers.
MEGA: Multimodal Alignment Aggregation and Distillation For Cinematic Video Segmentation
Aug 22, 2023



Previous research has studied the task of segmenting cinematic videos into scenes and into narrative acts. However, these studies have overlooked the essential task of multimodal alignment and fusion for effectively and efficiently processing long-form videos (>60min). In this paper, we introduce Multimodal alignmEnt aGgregation and distillAtion (MEGA) for cinematic long-video segmentation. MEGA tackles the challenge by leveraging multiple media modalities. The method coarsely aligns inputs of variable lengths and different modalities with alignment positional encoding. To maintain temporal synchronization while reducing computation, we further introduce an enhanced bottleneck fusion layer which uses temporal alignment. Additionally, MEGA employs a novel contrastive loss to synchronize and transfer labels across modalities, enabling act segmentation from labeled synopsis sentences on video shots. Our experimental results show that MEGA outperforms state-of-the-art methods on MovieNet dataset for scene segmentation (with an Average Precision improvement of +1.19%) and on TRIPOD dataset for act segmentation (with a Total Agreement improvement of +5.51%)
Large Scale Real-World Multi-Person Tracking
Nov 03, 2022This paper presents a new large scale multi-person tracking dataset -- \texttt{PersonPath22}, which is over an order of magnitude larger than currently available high quality multi-object tracking datasets such as MOT17, HiEve, and MOT20 datasets. The lack of large scale training and test data for this task has limited the community's ability to understand the performance of their tracking systems on a wide range of scenarios and conditions such as variations in person density, actions being performed, weather, and time of day. \texttt{PersonPath22} dataset was specifically sourced to provide a wide variety of these conditions and our annotations include rich meta-data such that the performance of a tracker can be evaluated along these different dimensions. The lack of training data has also limited the ability to perform end-to-end training of tracking systems. As such, the highest performing tracking systems all rely on strong detectors trained on external image datasets. We hope that the release of this dataset will enable new lines of research that take advantage of large scale video based training data.
An In-depth Study of Stochastic Backpropagation
Sep 30, 2022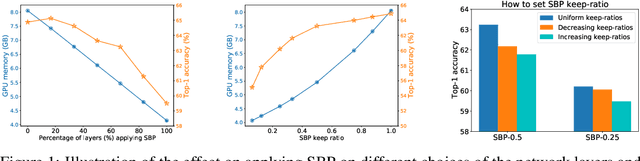
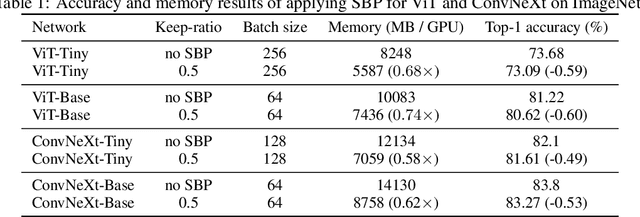
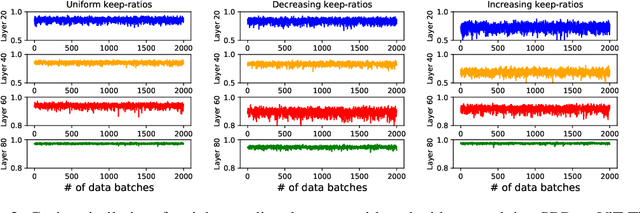
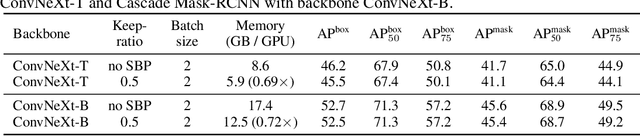
In this paper, we provide an in-depth study of Stochastic Backpropagation (SBP) when training deep neural networks for standard image classification and object detection tasks. During backward propagation, SBP calculates the gradients by only using a subset of feature maps to save the GPU memory and computational cost. We interpret SBP as an efficient way to implement stochastic gradient decent by performing backpropagation dropout, which leads to considerable memory saving and training process speedup, with a minimal impact on the overall model accuracy. We offer some good practices to apply SBP in training image recognition models, which can be adopted in learning a wide range of deep neural networks. Experiments on image classification and object detection show that SBP can save up to 40% of GPU memory with less than 1% accuracy degradation.
Transfer of Representations to Video Label Propagation: Implementation Factors Matter
Mar 10, 2022
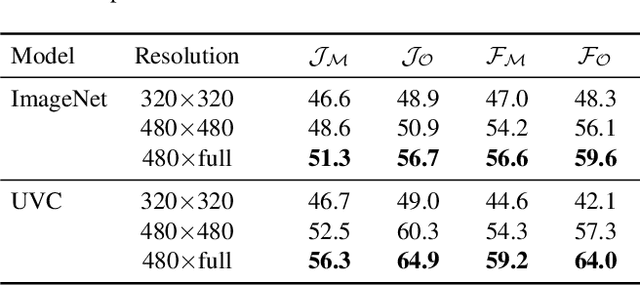
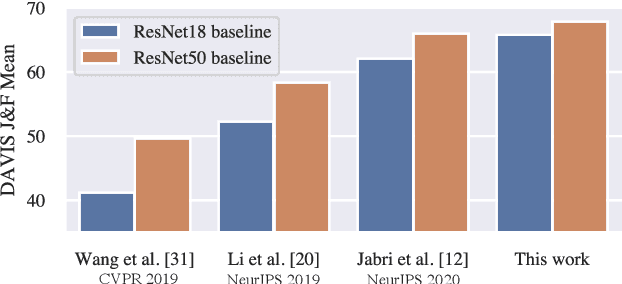
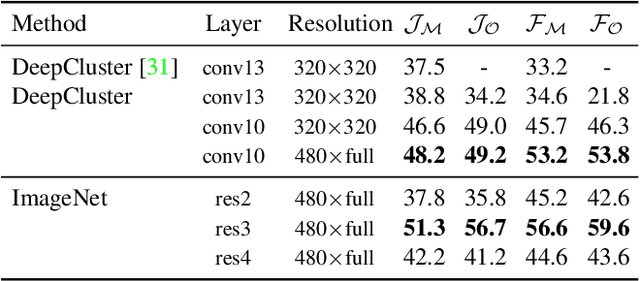
This work studies feature representations for dense label propagation in video, with a focus on recently proposed methods that learn video correspondence using self-supervised signals such as colorization or temporal cycle consistency. In the literature, these methods have been evaluated with an array of inconsistent settings, making it difficult to discern trends or compare performance fairly. Starting with a unified formulation of the label propagation algorithm that encompasses most existing variations, we systematically study the impact of important implementation factors in feature extraction and label propagation. Along the way, we report the accuracies of properly tuned supervised and unsupervised still image baselines, which are higher than those found in previous works. We also demonstrate that augmenting video-based correspondence cues with still-image-based ones can further improve performance. We then attempt a fair comparison of recent video-based methods on the DAVIS benchmark, showing convergence of best methods to performance levels near our strong ImageNet baseline, despite the usage of a variety of specialized video-based losses and training particulars. Additional comparisons on JHMDB and VIP datasets confirm the similar performance of current methods. We hope that this study will help to improve evaluation practices and better inform future research directions in temporal correspondence.
Multi-Object Tracking with Hallucinated and Unlabeled Videos
Aug 19, 2021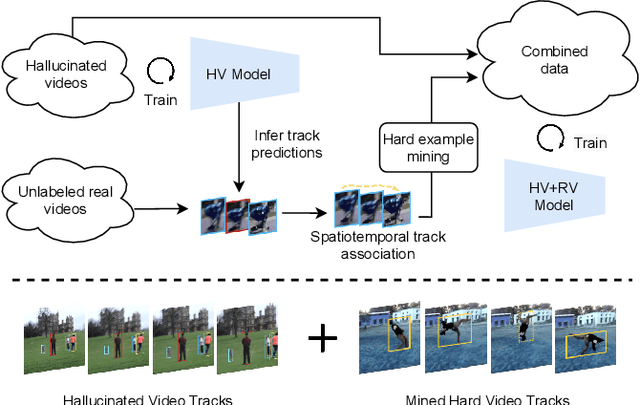
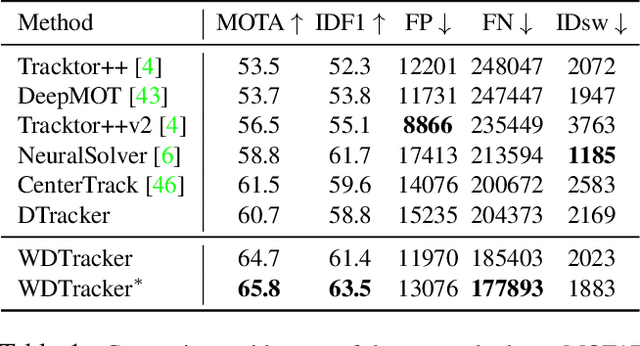


In this paper, we explore learning end-to-end deep neural trackers without tracking annotations. This is important as large-scale training data is essential for training deep neural trackers while tracking annotations are expensive to acquire. In place of tracking annotations, we first hallucinate videos from images with bounding box annotations using zoom-in/out motion transformations to obtain free tracking labels. We add video simulation augmentations to create a diverse tracking dataset, albeit with simple motion. Next, to tackle harder tracking cases, we mine hard examples across an unlabeled pool of real videos with a tracker trained on our hallucinated video data. For hard example mining, we propose an optimization-based connecting process to first identify and then rectify hard examples from the pool of unlabeled videos. Finally, we train our tracker jointly on hallucinated data and mined hard video examples. Our weakly supervised tracker achieves state-of-the-art performance on the MOT17 and TAO-person datasets. On MOT17, we further demonstrate that the combination of our self-generated data and the existing manually-annotated data leads to additional improvements.
SiamMOT: Siamese Multi-Object Tracking
May 25, 2021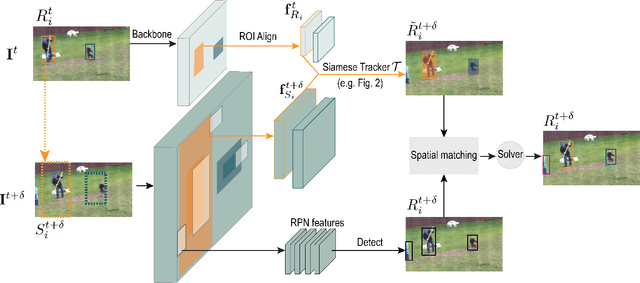

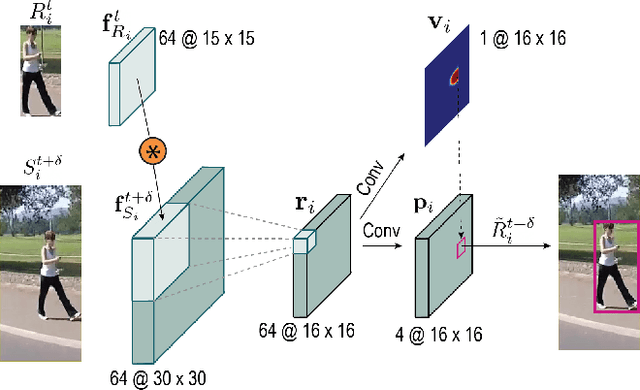
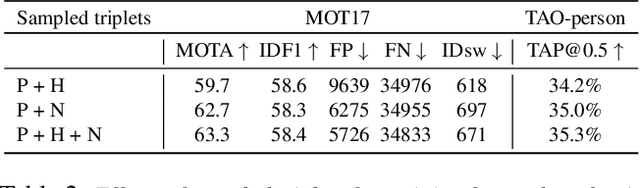
In this paper, we focus on improving online multi-object tracking (MOT). In particular, we introduce a region-based Siamese Multi-Object Tracking network, which we name SiamMOT. SiamMOT includes a motion model that estimates the instance's movement between two frames such that detected instances are associated. To explore how the motion modelling affects its tracking capability, we present two variants of Siamese tracker, one that implicitly models motion and one that models it explicitly. We carry out extensive quantitative experiments on three different MOT datasets: MOT17, TAO-person and Caltech Roadside Pedestrians, showing the importance of motion modelling for MOT and the ability of SiamMOT to substantially outperform the state-of-the-art. Finally, SiamMOT also outperforms the winners of ACM MM'20 HiEve Grand Challenge on HiEve dataset. Moreover, SiamMOT is efficient, and it runs at 17 FPS for 720P videos on a single modern GPU. Codes are available in \url{https://github.com/amazon-research/siam-mot}.
VidTr: Video Transformer Without Convolutions
Apr 23, 2021
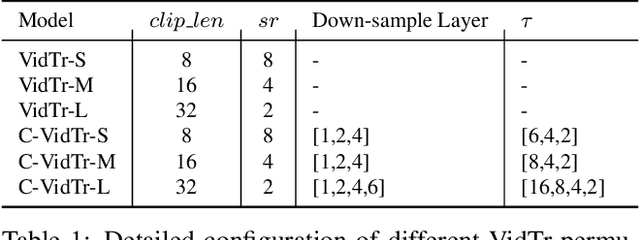
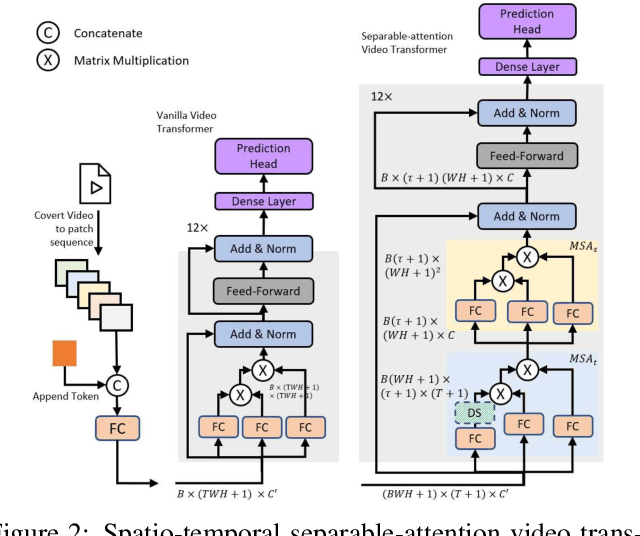
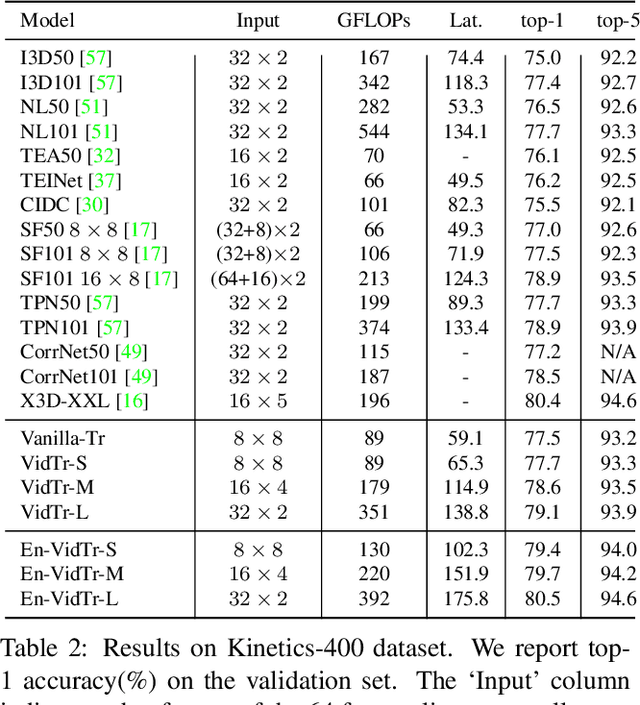
We introduce Video Transformer (VidTr) with separable-attention for video classification. Comparing with commonly used 3D networks, VidTr is able to aggregate spatio-temporal information via stacked attentions and provide better performance with higher efficiency. We first introduce the vanilla video transformer and show that transformer module is able to perform spatio-temporal modeling from raw pixels, but with heavy memory usage. We then present VidTr which reduces the memory cost by 3.3$\times$ while keeping the same performance. To further compact the model, we propose the standard deviation based topK pooling attention, which reduces the computation by dropping non-informative features. VidTr achieves state-of-the-art performance on five commonly used dataset with lower computational requirement, showing both the efficiency and effectiveness of our design. Finally, error analysis and visualization show that VidTr is especially good at predicting actions that require long-term temporal reasoning. The code and pre-trained weights will be released.