 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Multi-Object Tracking with Path Consistency
Apr 08, 2024In this paper, we propose a novel concept of path consistency to learn robust object matching without using manual object identity supervision. Our key idea is that, to track a object through frames, we can obtain multiple different association results from a model by varying the frames it can observe, i.e., skipping frames in observation. As the differences in observations do not alter the identities of objects, the obtained association results should be consistent. Based on this rationale, we generate multiple observation paths, each specifying a different set of frames to be skipped, and formulate the Path Consistency Loss that enforces the association results are consistent across different observation paths. We use the proposed loss to train our object matching model with only self-supervision. By extensive experiments on three tracking datasets (MOT17, PersonPath22, KITTI), we demonstrate that our method outperforms existing unsupervised methods with consistent margins on various evaluation metrics, and even achieves performance close to supervised methods.
Hyperbolic Learning with Synthetic Captions for Open-World Detection
Apr 07, 2024



Open-world detection poses significant challenges, as it requires the detection of any object using either object class labels or free-form texts. Existing related works often use large-scale manual annotated caption datasets for training, which are extremely expensive to collect. Instead, we propose to transfer knowledge from vision-language models (VLMs) to enrich the open-vocabulary descriptions automatically. Specifically, we bootstrap dense synthetic captions using pre-trained VLMs to provide rich descriptions on different regions in images, and incorporate these captions to train a novel detector that generalizes to novel concepts. To mitigate the noise caused by hallucination in synthetic captions, we also propose a novel hyperbolic vision-language learning approach to impose a hierarchy between visual and caption embeddings. We call our detector ``HyperLearner''. We conduct extensive experiments on a wide variety of open-world detection benchmarks (COCO, LVIS, Object Detection in the Wild, RefCOCO) and our results show that our model consistently outperforms existing state-of-the-art methods, such as GLIP, GLIPv2 and Grounding DINO, when using the same backbone.
Denoising and Selecting Pseudo-Heatmaps for Semi-Supervised Human Pose Estimation
Sep 29, 2023We propose a new semi-supervised learning design for human pose estimation that revisits the popular dual-student framework and enhances it two ways. First, we introduce a denoising scheme to generate reliable pseudo-heatmaps as targets for learning from unlabeled data. This uses multi-view augmentations and a threshold-and-refine procedure to produce a pool of pseudo-heatmaps. Second, we select the learning targets from these pseudo-heatmaps guided by the estimated cross-student uncertainty. We evaluate our proposed method on multiple evaluation setups on the COCO benchmark. Our results show that our model outperforms previous state-of-the-art semi-supervised pose estimators, especially in extreme low-data regime. For example with only 0.5K labeled images our method is capable of surpassing the best competitor by 7.22 mAP (+25% absolute improvement). We also demonstrate that our model can learn effectively from unlabeled data in the wild to further boost its generalization and performance.
Challenges of Zero-Shot Recognition with Vision-Language Models: Granularity and Correctness
Jun 28, 2023



This paper investigates the challenges of applying vision-language models (VLMs) to zero-shot visual recognition tasks in an open-world setting, with a focus on contrastive vision-language models such as CLIP. We first examine the performance of VLMs on concepts of different granularity levels. We propose a way to fairly evaluate the performance discrepancy under two experimental setups and find that VLMs are better at recognizing fine-grained concepts. Furthermore, we find that the similarity scores from VLMs do not strictly reflect the correctness of the textual inputs given visual input. We propose an evaluation protocol to test our hypothesis that the scores can be biased towards more informative descriptions, and the nature of the similarity score between embedding makes it challenging for VLMs to recognize the correctness between similar but wrong descriptions. Our study highlights the challenges of using VLMs in open-world settings and suggests directions for future research to improve their zero-shot capabilities.
ScaleDet: A Scalable Multi-Dataset Object Detector
Jun 08, 2023



Multi-dataset training provides a viable solution for exploiting heterogeneous large-scale datasets without extra annotation cost. In this work, we propose a scalable multi-dataset detector (ScaleDet) that can scale up its generalization across datasets when increasing the number of training datasets. Unlike existing multi-dataset learners that mostly rely on manual relabelling efforts or sophisticated optimizations to unify labels across datasets, we introduce a simple yet scalable formulation to derive a unified semantic label space for multi-dataset training. ScaleDet is trained by visual-textual alignment to learn the label assignment with label semantic similarities across datasets. Once trained, ScaleDet can generalize well on any given upstream and downstream datasets with seen and unseen classes. We conduct extensive experiments using LVIS, COCO, Objects365, OpenImages as upstream datasets, and 13 datasets from Object Detection in the Wild (ODinW) as downstream datasets. Our results show that ScaleDet achieves compelling strong model performance with an mAP of 50.7 on LVIS, 58.8 on COCO, 46.8 on Objects365, 76.2 on OpenImages, and 71.8 on ODinW, surpassing state-of-the-art detectors with the same backbone.
Distilling Knowledge from Self-Supervised Teacher by Embedding Graph Alignment
Nov 23, 2022



Recent advances have indicated the strengths of self-supervised pre-training for improving representation learning on downstream tasks. Existing works often utilize self-supervised pre-trained models by fine-tuning on downstream tasks. However, fine-tuning does not generalize to the case when one needs to build a customized model architecture different from the self-supervised model. In this work, we formulate a new knowledge distillation framework to transfer the knowledge from self-supervised pre-trained models to any other student network by a novel approach named Embedding Graph Alignment. Specifically, inspired by the spirit of instance discrimination in self-supervised learning, we model the instance-instance relations by a graph formulation in the feature embedding space and distill the self-supervised teacher knowledge to a student network by aligning the teacher graph and the student graph. Our distillation scheme can be flexibly applied to transfer the self-supervised knowledge to enhance representation learning on various student networks. We demonstrate that our model outperforms multiple representative knowledge distillation methods on three benchmark datasets, including CIFAR100, STL10, and TinyImageNet. Code is here: https://github.com/yccm/EGA.
Cross-Modal Fusion Distillation for Fine-Grained Sketch-Based Image Retrieval
Oct 19, 2022
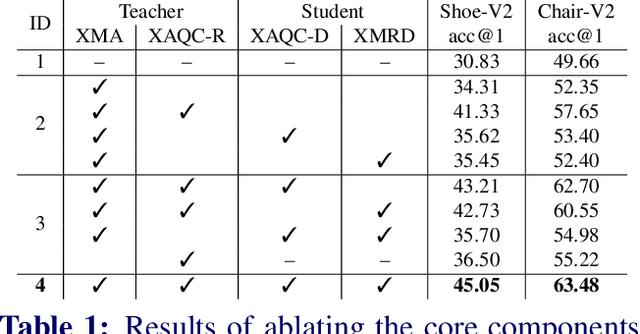

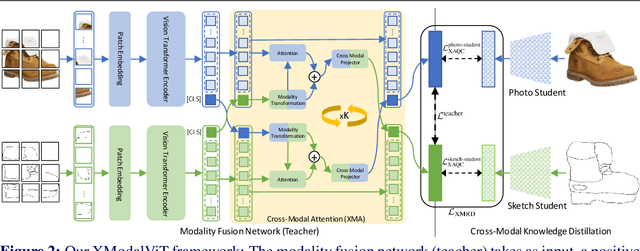
Representation learning for sketch-based image retrieval has mostly been tackled by learning embeddings that discard modality-specific information. As instances from different modalities can often provide complementary information describing the underlying concept, we propose a cross-attention framework for Vision Transformers (XModalViT) that fuses modality-specific information instead of discarding them. Our framework first maps paired datapoints from the individual photo and sketch modalities to fused representations that unify information from both modalities. We then decouple the input space of the aforementioned modality fusion network into independent encoders of the individual modalities via contrastive and relational cross-modal knowledge distillation. Such encoders can then be applied to downstream tasks like cross-modal retrieval. We demonstrate the expressive capacity of the learned representations by performing a wide range of experiments and achieving state-of-the-art results on three fine-grained sketch-based image retrieval benchmarks: Shoe-V2, Chair-V2 and Sketchy. Implementation is available at https://github.com/abhrac/xmodal-vit.
Semi-Supervised and Unsupervised Deep Visual Learning: A Survey
Aug 24, 2022

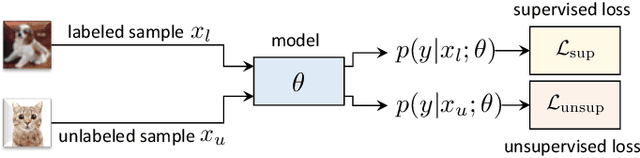

State-of-the-art deep learning models are often trained with a large amount of costly labeled training data. However, requiring exhaustive manual annotations may degrade the model's generalizability in the limited-label regime. Semi-supervised learning and unsupervised learning offer promising paradigms to learn from an abundance of unlabeled visual data. Recent progress in these paradigms has indicated the strong benefits of leveraging unlabeled data to improve model generalization and provide better model initialization. In this survey, we review the recent advanced deep learning algorithms on semi-supervised learning (SSL) and unsupervised learning (UL) for visual recognition from a unified perspective. To offer a holistic understanding of the state-of-the-art in these areas, we propose a unified taxonomy. We categorize existing representative SSL and UL with comprehensive and insightful analysis to highlight their design rationales in different learning scenarios and applications in different computer vision tasks. Lastly, we discuss the emerging trends and open challenges in SSL and UL to shed light on future critical research directions.
BayesCap: Bayesian Identity Cap for Calibrated Uncertainty in Frozen Neural Networks
Jul 14, 2022
High-quality calibrated uncertainty estimates are crucial for numerous real-world applications, especially for deep learning-based deployed ML systems. While Bayesian deep learning techniques allow uncertainty estimation, training them with large-scale datasets is an expensive process that does not always yield models competitive with non-Bayesian counterparts. Moreover, many of the high-performing deep learning models that are already trained and deployed are non-Bayesian in nature and do not provide uncertainty estimates. To address these issues, we propose BayesCap that learns a Bayesian identity mapping for the frozen model, allowing uncertainty estimation. BayesCap is a memory-efficient method that can be trained on a small fraction of the original dataset, enhancing pretrained non-Bayesian computer vision models by providing calibrated uncertainty estimates for the predictions without (i) hampering the performance of the model and (ii) the need for expensive retraining the model from scratch. The proposed method is agnostic to various architectures and tasks. We show the efficacy of our method on a wide variety of tasks with a diverse set of architectures, including image super-resolution, deblurring, inpainting, and crucial application such as medical image translation. Moreover, we apply the derived uncertainty estimates to detect out-of-distribution samples in critical scenarios like depth estimation in autonomous driving. Code is available at https://github.com/ExplainableML/BayesCap.
Attention Consistency on Visual Corruptions for Single-Source Domain Generalization
Apr 27, 2022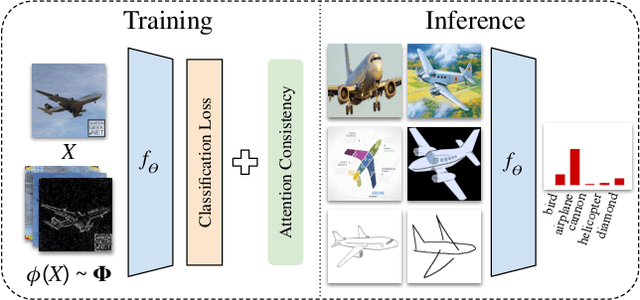
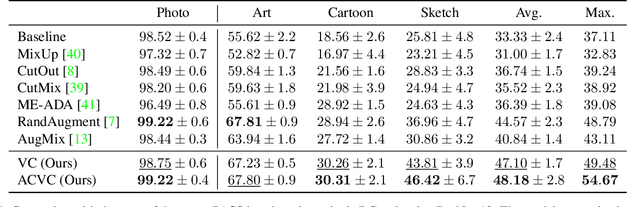


Generalizing visual recognition models trained on a single distribution to unseen input distributions (i.e. domains) requires making them robust to superfluous correlations in the training set. In this work, we achieve this goal by altering the training images to simulate new domains and imposing consistent visual attention across the different views of the same sample. We discover that the first objective can be simply and effectively met through visual corruptions. Specifically, we alter the content of the training images using the nineteen corruptions of the ImageNet-C benchmark and three additional transformations based on Fourier transform. Since these corruptions preserve object locations, we propose an attention consistency loss to ensure that class activation maps across original and corrupted versions of the same training sample are aligned. We name our model Attention Consistency on Visual Corruptions (ACVC). We show that ACVC consistently achieves the state of the art on three single-source domain generalization benchmarks, PACS, COCO, and the large-scale DomainNet.