 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDAVE: A VLM Vision Encoder for Document Understanding and Web Agents
Dec 19, 2025While Vision-language models (VLMs) have demonstrated remarkable performance across multi-modal tasks, their choice of vision encoders presents a fundamental weakness: their low-level features lack the robust structural and spatial information essential for document understanding and web agents. To bridge this gap, we introduce DAVE, a vision encoder purpose-built for VLMs and tailored for these tasks. Our training pipeline is designed to leverage abundant unlabeled data to bypass the need for costly large-scale annotations for document and web images. We begin with a self-supervised pretraining stage on unlabeled images, followed by a supervised autoregressive pretraining stage, where the model learns tasks like parsing and localization from limited, high-quality data. Within the supervised stage, we adopt two strategies to improve our encoder's alignment with both general visual knowledge and diverse document and web agentic tasks: (i) We introduce a novel model-merging scheme, combining encoders trained with different text decoders to ensure broad compatibility with different web agentic architectures. (ii) We use ensemble training to fuse features from pretrained generalist encoders (e.g., SigLIP2) with our own document and web-specific representations. Extensive experiments on classic document tasks, VQAs, web localization, and agent-based benchmarks validate the effectiveness of our approach, establishing DAVE as a strong vision encoder for document and web applications.
Don't Waste It: Guiding Generative Recommenders with Structured Human Priors via Multi-head Decoding
Nov 16, 2025Optimizing recommender systems for objectives beyond accuracy, such as diversity, novelty, and personalization, is crucial for long-term user satisfaction. To this end, industrial practitioners have accumulated vast amounts of structured domain knowledge, which we term human priors (e.g., item taxonomies, temporal patterns). This knowledge is typically applied through post-hoc adjustments during ranking or post-ranking. However, this approach remains decoupled from the core model learning, which is particularly undesirable as the industry shifts to end-to-end generative recommendation foundation models. On the other hand, many methods targeting these beyond-accuracy objectives often require architecture-specific modifications and discard these valuable human priors by learning user intent in a fully unsupervised manner. Instead of discarding the human priors accumulated over years of practice, we introduce a backbone-agnostic framework that seamlessly integrates these human priors directly into the end-to-end training of generative recommenders. With lightweight, prior-conditioned adapter heads inspired by efficient LLM decoding strategies, our approach guides the model to disentangle user intent along human-understandable axes (e.g., interaction types, long- vs. short-term interests). We also introduce a hierarchical composition strategy for modeling complex interactions across different prior types. Extensive experiments on three large-scale datasets demonstrate that our method significantly enhances both accuracy and beyond-accuracy objectives. We also show that human priors allow the backbone model to more effectively leverage longer context lengths and larger model sizes.
CuRe: Cultural Gaps in the Long Tail of Text-to-Image Systems
Jun 09, 2025Popular text-to-image (T2I) systems are trained on web-scraped data, which is heavily Amero and Euro-centric, underrepresenting the cultures of the Global South. To analyze these biases, we introduce CuRe, a novel and scalable benchmarking and scoring suite for cultural representativeness that leverages the marginal utility of attribute specification to T2I systems as a proxy for human judgments. Our CuRe benchmark dataset has a novel categorical hierarchy built from the crowdsourced Wikimedia knowledge graph, with 300 cultural artifacts across 32 cultural subcategories grouped into six broad cultural axes (food, art, fashion, architecture, celebrations, and people). Our dataset's categorical hierarchy enables CuRe scorers to evaluate T2I systems by analyzing their response to increasing the informativeness of text conditioning, enabling fine-grained cultural comparisons. We empirically observe much stronger correlations of our class of scorers to human judgments of perceptual similarity, image-text alignment, and cultural diversity across image encoders (SigLIP 2, AIMV2 and DINOv2), vision-language models (OpenCLIP, SigLIP 2, Gemini 2.0 Flash) and state-of-the-art text-to-image systems, including three variants of Stable Diffusion (1.5, XL, 3.5 Large), FLUX.1 [dev], Ideogram 2.0, and DALL-E 3. The code and dataset is open-sourced and available at https://aniketrege.github.io/cure/.
UniTalk: Towards Universal Active Speaker Detection in Real World Scenarios
May 28, 2025We present UniTalk, a novel dataset specifically designed for the task of active speaker detection, emphasizing challenging scenarios to enhance model generalization. Unlike previously established benchmarks such as AVA, which predominantly features old movies and thus exhibits significant domain gaps, UniTalk focuses explicitly on diverse and difficult real-world conditions. These include underrepresented languages, noisy backgrounds, and crowded scenes - such as multiple visible speakers speaking concurrently or in overlapping turns. It contains over 44.5 hours of video with frame-level active speaker annotations across 48,693 speaking identities, and spans a broad range of video types that reflect real-world conditions. Through rigorous evaluation, we show that state-of-the-art models, while achieving nearly perfect scores on AVA, fail to reach saturation on UniTalk, suggesting that the ASD task remains far from solved under realistic conditions. Nevertheless, models trained on UniTalk demonstrate stronger generalization to modern "in-the-wild" datasets like Talkies and ASW, as well as to AVA. UniTalk thus establishes a new benchmark for active speaker detection, providing researchers with a valuable resource for developing and evaluating versatile and resilient models. Dataset: https://huggingface.co/datasets/plnguyen2908/UniTalk-ASD Code: https://github.com/plnguyen2908/UniTalk-ASD-code
LASER: Lip Landmark Assisted Speaker Detection for Robustness
Jan 21, 2025Active Speaker Detection (ASD) aims to identify speaking individuals in complex visual scenes. While humans can easily detect speech by matching lip movements to audio, current ASD models struggle to establish this correspondence, often misclassifying non-speaking instances when audio and lip movements are unsynchronized. To address this limitation, we propose Lip landmark Assisted Speaker dEtection for Robustness (LASER). Unlike models that rely solely on facial frames, LASER explicitly focuses on lip movements by integrating lip landmarks in training. Specifically, given a face track, LASER extracts frame-level visual features and the 2D coordinates of lip landmarks using a lightweight detector. These coordinates are encoded into dense feature maps, providing spatial and structural information on lip positions. Recognizing that landmark detectors may sometimes fail under challenging conditions (e.g., low resolution, occlusions, extreme angles), we incorporate an auxiliary consistency loss to align predictions from both lip-aware and face-only features, ensuring reliable performance even when lip data is absent. Extensive experiments across multiple datasets show that LASER outperforms state-of-the-art models, especially in scenarios with desynchronized audio and visuals, demonstrating robust performance in real-world video contexts. Code is available at \url{https://github.com/plnguyen2908/LASER_ASD}.
Diversify, Don't Fine-Tune: Scaling Up Visual Recognition Training with Synthetic Images
Dec 04, 2023

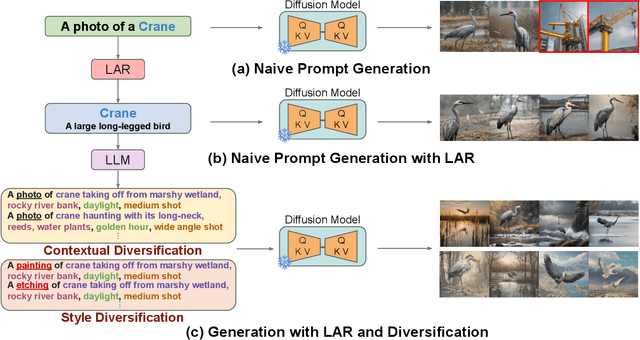

Recent advances in generative deep learning have enabled the creation of high-quality synthetic images in text-to-image generation. Prior work shows that fine-tuning a pretrained diffusion model on ImageNet and generating synthetic training images from the finetuned model can enhance an ImageNet classifier's performance. However, performance degrades as synthetic images outnumber real ones. In this paper, we explore whether generative fine-tuning is essential for this improvement and whether it is possible to further scale up training using more synthetic data. We present a new framework leveraging off-the-shelf generative models to generate synthetic training images, addressing multiple challenges: class name ambiguity, lack of diversity in naive prompts, and domain shifts. Specifically, we leverage large language models (LLMs) and CLIP to resolve class name ambiguity. To diversify images, we propose contextualized diversification (CD) and stylized diversification (SD) methods, also prompted by LLMs. Finally, to mitigate domain shifts, we leverage domain adaptation techniques with auxiliary batch normalization for synthetic images. Our framework consistently enhances recognition model performance with more synthetic data, up to 6x of original ImageNet size showcasing the potential of synthetic data for improved recognition models and strong out-of-domain generalization.
Denoising and Selecting Pseudo-Heatmaps for Semi-Supervised Human Pose Estimation
Sep 29, 2023We propose a new semi-supervised learning design for human pose estimation that revisits the popular dual-student framework and enhances it two ways. First, we introduce a denoising scheme to generate reliable pseudo-heatmaps as targets for learning from unlabeled data. This uses multi-view augmentations and a threshold-and-refine procedure to produce a pool of pseudo-heatmaps. Second, we select the learning targets from these pseudo-heatmaps guided by the estimated cross-student uncertainty. We evaluate our proposed method on multiple evaluation setups on the COCO benchmark. Our results show that our model outperforms previous state-of-the-art semi-supervised pose estimators, especially in extreme low-data regime. For example with only 0.5K labeled images our method is capable of surpassing the best competitor by 7.22 mAP (+25% absolute improvement). We also demonstrate that our model can learn effectively from unlabeled data in the wild to further boost its generalization and performance.
InPL: Pseudo-labeling the Inliers First for Imbalanced Semi-supervised Learning
Mar 13, 2023


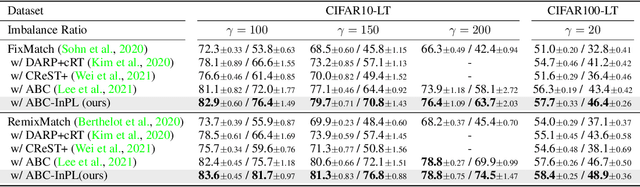
Recent state-of-the-art methods in imbalanced semi-supervised learning (SSL) rely on confidence-based pseudo-labeling with consistency regularization. To obtain high-quality pseudo-labels, a high confidence threshold is typically adopted. However, it has been shown that softmax-based confidence scores in deep networks can be arbitrarily high for samples far from the training data, and thus, the pseudo-labels for even high-confidence unlabeled samples may still be unreliable. In this work, we present a new perspective of pseudo-labeling for imbalanced SSL. Without relying on model confidence, we propose to measure whether an unlabeled sample is likely to be ``in-distribution''; i.e., close to the current training data. To decide whether an unlabeled sample is ``in-distribution'' or ``out-of-distribution'', we adopt the energy score from out-of-distribution detection literature. As training progresses and more unlabeled samples become in-distribution and contribute to training, the combined labeled and pseudo-labeled data can better approximate the true class distribution to improve the model. Experiments demonstrate that our energy-based pseudo-labeling method, \textbf{InPL}, albeit conceptually simple, significantly outperforms confidence-based methods on imbalanced SSL benchmarks. For example, it produces around 3\% absolute accuracy improvement on CIFAR10-LT. When combined with state-of-the-art long-tailed SSL methods, further improvements are attained. In particular, in one of the most challenging scenarios, InPL achieves a 6.9\% accuracy improvement over the best competitor.
EnergyMatch: Energy-based Pseudo-Labeling for Semi-Supervised Learning
Jun 13, 2022

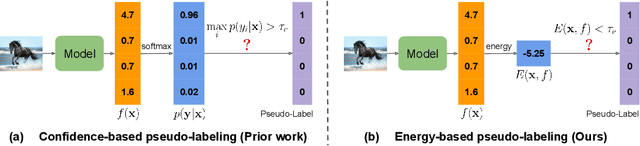
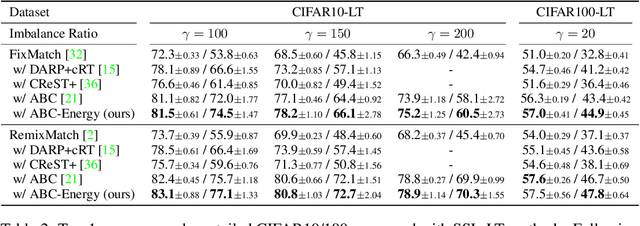
Recent state-of-the-art methods in semi-supervised learning (SSL) combine consistency regularization with confidence-based pseudo-labeling. To obtain high-quality pseudo-labels, a high confidence threshold is typically adopted. However, it has been shown that softmax-based confidence scores in deep networks can be arbitrarily high for samples far from the training data, and thus, the pseudo-labels for even high-confidence unlabeled samples may still be unreliable. In this work, we present a new perspective of pseudo-labeling: instead of relying on model confidence, we instead measure whether an unlabeled sample is likely to be "in-distribution"; i.e., close to the current training data. To classify whether an unlabeled sample is "in-distribution" or "out-of-distribution", we adopt the energy score from out-of-distribution detection literature. As training progresses and more unlabeled samples become in-distribution and contribute to training, the combined labeled and pseudo-labeled data can better approximate the true distribution to improve the model. Experiments demonstrate that our energy-based pseudo-labeling method, albeit conceptually simple, significantly outperforms confidence-based methods on imbalanced SSL benchmarks, and achieves competitive performance on class-balanced data. For example, it produces a 4-6% absolute accuracy improvement on CIFAR10-LT when the imbalance ratio is higher than 50. When combined with state-of-the-art long-tailed SSL methods, further improvements are attained.
Group R-CNN for Weakly Semi-supervised Object Detection with Points
May 12, 2022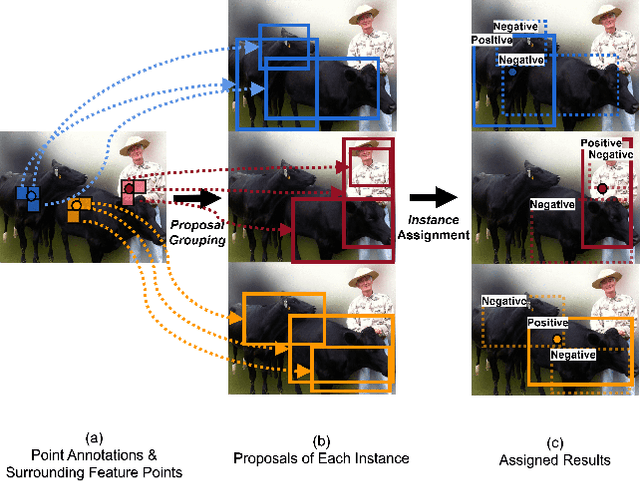
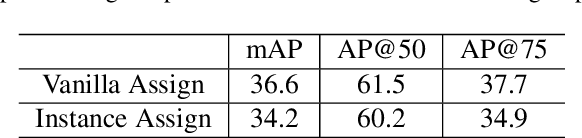
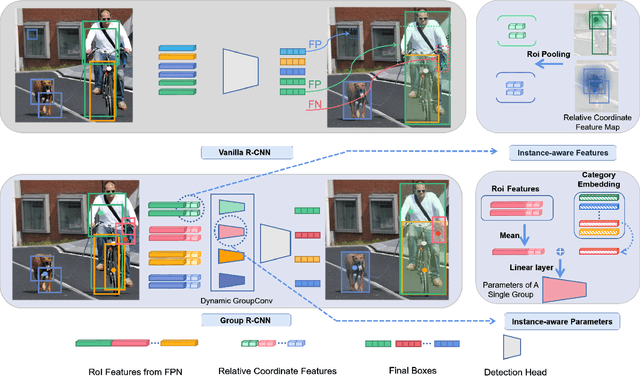
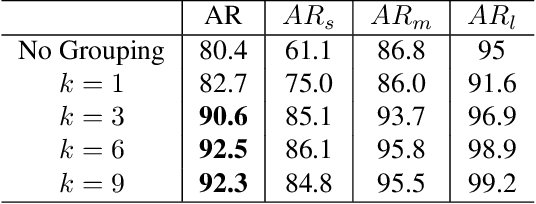
We study the problem of weakly semi-supervised object detection with points (WSSOD-P), where the training data is combined by a small set of fully annotated images with bounding boxes and a large set of weakly-labeled images with only a single point annotated for each instance. The core of this task is to train a point-to-box regressor on well-labeled images that can be used to predict credible bounding boxes for each point annotation. We challenge the prior belief that existing CNN-based detectors are not compatible with this task. Based on the classic R-CNN architecture, we propose an effective point-to-box regressor: Group R-CNN. Group R-CNN first uses instance-level proposal grouping to generate a group of proposals for each point annotation and thus can obtain a high recall rate. To better distinguish different instances and improve precision, we propose instance-level proposal assignment to replace the vanilla assignment strategy adopted in the original R-CNN methods. As naive instance-level assignment brings converging difficulty, we propose instance-aware representation learning which consists of instance-aware feature enhancement and instance-aware parameter generation to overcome this issue. Comprehensive experiments on the MS-COCO benchmark demonstrate the effectiveness of our method. Specifically, Group R-CNN significantly outperforms the prior method Point DETR by 3.9 mAP with 5% well-labeled images, which is the most challenging scenario. The source code can be found at https://github.com/jshilong/GroupRCNN