 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoth Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Dec 19, 2025Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.
REMOTE: A Unified Multimodal Relation Extraction Framework with Multilevel Optimal Transport and Mixture-of-Experts
Sep 05, 2025
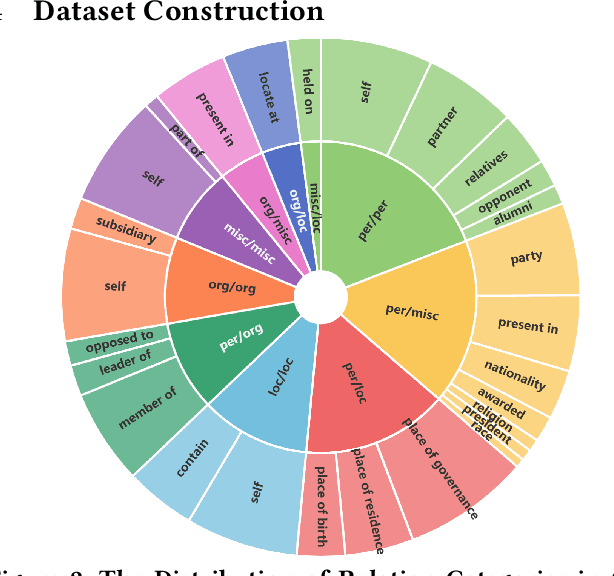
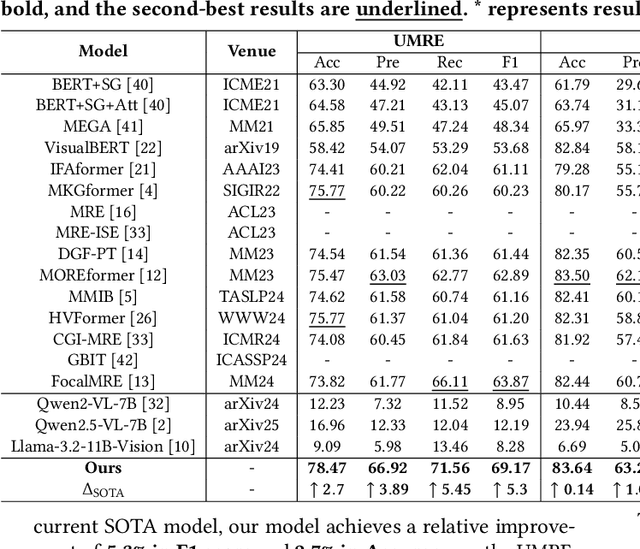
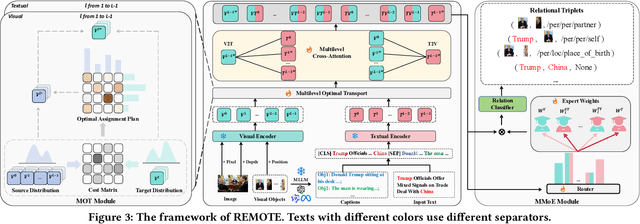
Multimodal relation extraction (MRE) is a crucial task in the fields of Knowledge Graph and Multimedia, playing a pivotal role in multimodal knowledge graph construction. However, existing methods are typically limited to extracting a single type of relational triplet, which restricts their ability to extract triplets beyond the specified types. Directly combining these methods fails to capture dynamic cross-modal interactions and introduces significant computational redundancy. Therefore, we propose a novel \textit{unified multimodal Relation Extraction framework with Multilevel Optimal Transport and mixture-of-Experts}, termed REMOTE, which can simultaneously extract intra-modal and inter-modal relations between textual entities and visual objects. To dynamically select optimal interaction features for different types of relational triplets, we introduce mixture-of-experts mechanism, ensuring the most relevant modality information is utilized. Additionally, considering that the inherent property of multilayer sequential encoding in existing encoders often leads to the loss of low-level information, we adopt a multilevel optimal transport fusion module to preserve low-level features while maintaining multilayer encoding, yielding more expressive representations. Correspondingly, we also create a Unified Multimodal Relation Extraction (UMRE) dataset to evaluate the effectiveness of our framework, encompassing diverse cases where the head and tail entities can originate from either text or image. Extensive experiments show that REMOTE effectively extracts various types of relational triplets and achieves state-of-the-art performanc on almost all metrics across two other public MRE datasets. We release our resources at https://github.com/Nikol-coder/REMOTE.
Multimodal Forecasting of Sparse Intraoperative Hypotension Events Powered by Language Model
May 28, 2025Intraoperative hypotension (IOH) frequently occurs under general anesthesia and is strongly linked to adverse outcomes such as myocardial injury and increased mortality. Despite its significance, IOH prediction is hindered by event sparsity and the challenge of integrating static and dynamic data across diverse patients. In this paper, we propose \textbf{IOHFuseLM}, a multimodal language model framework. To accurately identify and differentiate sparse hypotensive events, we leverage a two-stage training strategy. The first stage involves domain adaptive pretraining on IOH physiological time series augmented through diffusion methods, thereby enhancing the model sensitivity to patterns associated with hypotension. Subsequently, task fine-tuning is performed on the original clinical dataset to further enhance the ability to distinguish normotensive from hypotensive states. To enable multimodal fusion for each patient, we align structured clinical descriptions with the corresponding physiological time series at the token level. Such alignment enables the model to capture individualized temporal patterns alongside their corresponding clinical semantics. In addition, we convert static patient attributes into structured text to enrich personalized information. Experimental evaluations on two intraoperative datasets demonstrate that IOHFuseLM outperforms established baselines in accurately identifying IOH events, highlighting its applicability in clinical decision support scenarios. Our code is publicly available to promote reproducibility at https://github.com/zjt-gpu/IOHFuseLM.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
PixelFlow: Pixel-Space Generative Models with Flow
Apr 10, 2025



We present PixelFlow, a family of image generation models that operate directly in the raw pixel space, in contrast to the predominant latent-space models. This approach simplifies the image generation process by eliminating the need for a pre-trained Variational Autoencoder (VAE) and enabling the whole model end-to-end trainable. Through efficient cascade flow modeling, PixelFlow achieves affordable computation cost in pixel space. It achieves an FID of 1.98 on 256$\times$256 ImageNet class-conditional image generation benchmark. The qualitative text-to-image results demonstrate that PixelFlow excels in image quality, artistry, and semantic control. We hope this new paradigm will inspire and open up new opportunities for next-generation visual generation models. Code and models are available at https://github.com/ShoufaChen/PixelFlow.
Goku: Flow Based Video Generative Foundation Models
Feb 10, 2025



This paper introduces Goku, a state-of-the-art family of joint image-and-video generation models leveraging rectified flow Transformers to achieve industry-leading performance. We detail the foundational elements enabling high-quality visual generation, including the data curation pipeline, model architecture design, flow formulation, and advanced infrastructure for efficient and robust large-scale training. The Goku models demonstrate superior performance in both qualitative and quantitative evaluations, setting new benchmarks across major tasks. Specifically, Goku achieves 0.76 on GenEval and 83.65 on DPG-Bench for text-to-image generation, and 84.85 on VBench for text-to-video tasks. We believe that this work provides valuable insights and practical advancements for the research community in developing joint image-and-video generation models.
FlashVideo:Flowing Fidelity to Detail for Efficient High-Resolution Video Generation
Feb 07, 2025DiT diffusion models have achieved great success in text-to-video generation, leveraging their scalability in model capacity and data scale. High content and motion fidelity aligned with text prompts, however, often require large model parameters and a substantial number of function evaluations (NFEs). Realistic and visually appealing details are typically reflected in high resolution outputs, further amplifying computational demands especially for single stage DiT models. To address these challenges, we propose a novel two stage framework, FlashVideo, which strategically allocates model capacity and NFEs across stages to balance generation fidelity and quality. In the first stage, prompt fidelity is prioritized through a low resolution generation process utilizing large parameters and sufficient NFEs to enhance computational efficiency. The second stage establishes flow matching between low and high resolutions, effectively generating fine details with minimal NFEs. Quantitative and visual results demonstrate that FlashVideo achieves state-of-the-art high resolution video generation with superior computational efficiency. Additionally, the two-stage design enables users to preview the initial output before committing to full resolution generation, thereby significantly reducing computational costs and wait times as well as enhancing commercial viability .
Prompt-A-Video: Prompt Your Video Diffusion Model via Preference-Aligned LLM
Dec 19, 2024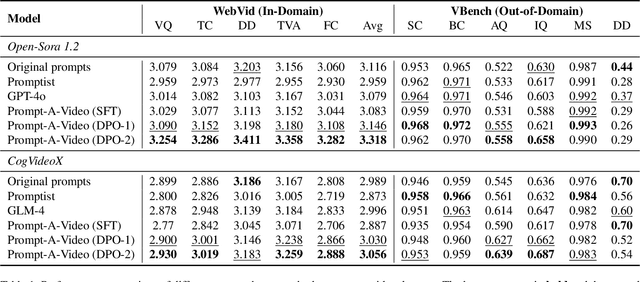

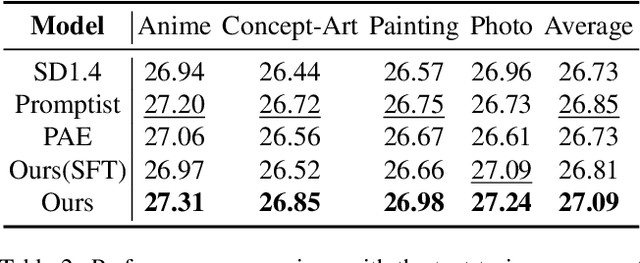

Text-to-video models have made remarkable advancements through optimization on high-quality text-video pairs, where the textual prompts play a pivotal role in determining quality of output videos. However, achieving the desired output often entails multiple revisions and iterative inference to refine user-provided prompts. Current automatic methods for refining prompts encounter challenges such as Modality-Inconsistency, Cost-Discrepancy, and Model-Unaware when applied to text-to-video diffusion models. To address these problem, we introduce an LLM-based prompt adaptation framework, termed as Prompt-A-Video, which excels in crafting Video-Centric, Labor-Free and Preference-Aligned prompts tailored to specific video diffusion model. Our approach involves a meticulously crafted two-stage optimization and alignment system. Initially, we conduct a reward-guided prompt evolution pipeline to automatically create optimal prompts pool and leverage them for supervised fine-tuning (SFT) of the LLM. Then multi-dimensional rewards are employed to generate pairwise data for the SFT model, followed by the direct preference optimization (DPO) algorithm to further facilitate preference alignment. Through extensive experimentation and comparative analyses, we validate the effectiveness of Prompt-A-Video across diverse generation models, highlighting its potential to push the boundaries of video generation.
IDA-VLM: Towards Movie Understanding via ID-Aware Large Vision-Language Model
Jul 10, 2024



The rapid advancement of Large Vision-Language models (LVLMs) has demonstrated a spectrum of emergent capabilities. Nevertheless, current models only focus on the visual content of a single scenario, while their ability to associate instances across different scenes has not yet been explored, which is essential for understanding complex visual content, such as movies with multiple characters and intricate plots. Towards movie understanding, a critical initial step for LVLMs is to unleash the potential of character identities memory and recognition across multiple visual scenarios. To achieve the goal, we propose visual instruction tuning with ID reference and develop an ID-Aware Large Vision-Language Model, IDA-VLM. Furthermore, our research introduces a novel benchmark MM-ID, to examine LVLMs on instance IDs memory and recognition across four dimensions: matching, location, question-answering, and captioning. Our findings highlight the limitations of existing LVLMs in recognizing and associating instance identities with ID reference. This paper paves the way for future artificial intelligence systems to possess multi-identity visual inputs, thereby facilitating the comprehension of complex visual narratives like movies.
Zero-shot Image Editing with Reference Imitation
Jun 11, 2024



Image editing serves as a practical yet challenging task considering the diverse demands from users, where one of the hardest parts is to precisely describe how the edited image should look like. In this work, we present a new form of editing, termed imitative editing, to help users exercise their creativity more conveniently. Concretely, to edit an image region of interest, users are free to directly draw inspiration from some in-the-wild references (e.g., some relative pictures come across online), without having to cope with the fit between the reference and the source. Such a design requires the system to automatically figure out what to expect from the reference to perform the editing. For this purpose, we propose a generative training framework, dubbed MimicBrush, which randomly selects two frames from a video clip, masks some regions of one frame, and learns to recover the masked regions using the information from the other frame. That way, our model, developed from a diffusion prior, is able to capture the semantic correspondence between separate images in a self-supervised manner. We experimentally show the effectiveness of our method under various test cases as well as its superiority over existing alternatives. We also construct a benchmark to facilitate further research.