 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashVideo:Flowing Fidelity to Detail for Efficient High-Resolution Video Generation
Feb 07, 2025DiT diffusion models have achieved great success in text-to-video generation, leveraging their scalability in model capacity and data scale. High content and motion fidelity aligned with text prompts, however, often require large model parameters and a substantial number of function evaluations (NFEs). Realistic and visually appealing details are typically reflected in high resolution outputs, further amplifying computational demands especially for single stage DiT models. To address these challenges, we propose a novel two stage framework, FlashVideo, which strategically allocates model capacity and NFEs across stages to balance generation fidelity and quality. In the first stage, prompt fidelity is prioritized through a low resolution generation process utilizing large parameters and sufficient NFEs to enhance computational efficiency. The second stage establishes flow matching between low and high resolutions, effectively generating fine details with minimal NFEs. Quantitative and visual results demonstrate that FlashVideo achieves state-of-the-art high resolution video generation with superior computational efficiency. Additionally, the two-stage design enables users to preview the initial output before committing to full resolution generation, thereby significantly reducing computational costs and wait times as well as enhancing commercial viability .
OmniTokenizer: A Joint Image-Video Tokenizer for Visual Generation
Jun 13, 2024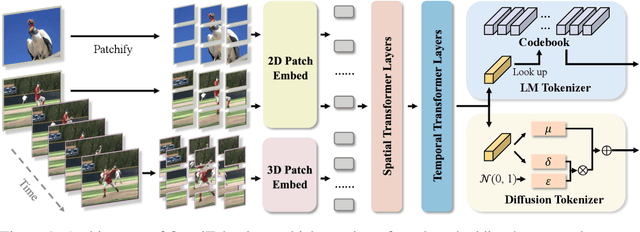
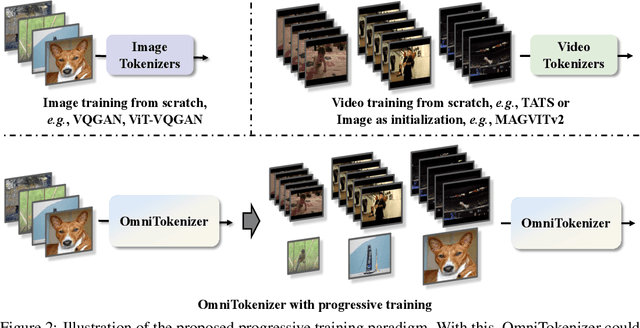
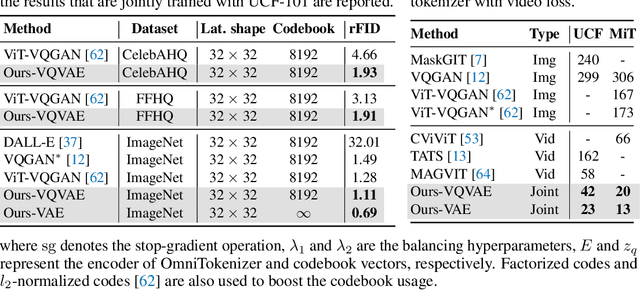
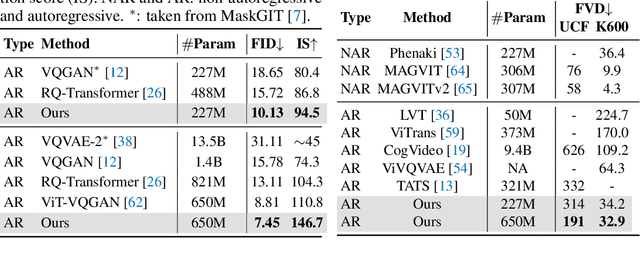
Tokenizer, serving as a translator to map the intricate visual data into a compact latent space, lies at the core of visual generative models. Based on the finding that existing tokenizers are tailored to image or video inputs, this paper presents OmniTokenizer, a transformer-based tokenizer for joint image and video tokenization. OmniTokenizer is designed with a spatial-temporal decoupled architecture, which integrates window and causal attention for spatial and temporal modeling. To exploit the complementary nature of image and video data, we further propose a progressive training strategy, where OmniTokenizer is first trained on image data on a fixed resolution to develop the spatial encoding capacity and then jointly trained on image and video data on multiple resolutions to learn the temporal dynamics. OmniTokenizer, for the first time, handles both image and video inputs within a unified framework and proves the possibility of realizing their synergy. Extensive experiments demonstrate that OmniTokenizer achieves state-of-the-art (SOTA) reconstruction performance on various image and video datasets, e.g., 1.11 reconstruction FID on ImageNet and 42 reconstruction FVD on UCF-101, beating the previous SOTA methods by 13% and 26%, respectively. Additionally, we also show that when integrated with OmniTokenizer, both language model-based approaches and diffusion models can realize advanced visual synthesis performance, underscoring the superiority and versatility of our method. Code is available at https://github.com/FoundationVision/OmniTokenizer.