 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinkingVLA: Interleaved Vision and Language Reasoning for Robotic Manipulation
Jun 16, 2026Most Vision-Language-Action (VLA) models map observations directly to actions without explicit reasoning, limiting their capacity for reasoning-intensive long-horizon tasks. To address this, existing approaches adopt Chain-of-Thought (CoT) reasoning to enable subgoal decomposition and spatial anticipation. However, those methods lack a unified architecture for effective cross-modal reasoning and fail to explicitly include inverse reasoning ability based on the target state. We argue that manipulation planning naturally decomposes into prediction, anticipating the next visual state, and inverse dynamics, inferring the actions to reach it. Bridging both requires a unified autoregressive architecture that interleaves textual and visual reasoning in a single generation process. We propose \textbf{ThinkingVLA}, a generative model that realizes this decomposition within a unified Mixture-of-Transformers architecture. ThinkingVLA consists of a forward CoT that identifies the immediate subgoal and guides the visual forecasting; the predicted image then serves as the target state, grounding an inverse CoT that reasons about spatial relationships and action intent based on the predicted image; and the final action is generated conditioned on this full reasoning context. Extensive experiments on simulation and real-world benchmarks demonstrate that ThinkingVLA consistently outperforms state-of-the-art baselines, with particularly large gains on long-horizon manipulation tasks.
RepWAM: World Action Modeling with Representation Visual-Action Tokenizers
Jun 11, 2026This work presents RepWAM, a representation-centric world action model (WAM) built on representation visual-action tokenizers. Existing WAMs typically inherit reconstruction-oriented video tokenizers from pretrained video generation models. Although these tokenizers preserve visual fidelity, pixel reconstruction alone provides limited guidance for learning instruction-following dynamics that connect future prediction with robot control. To address this, we explore a semantic visual-action latent space for representation-centric world action modeling. Specifically, we train a representation visual-action tokenizer that maps visual inputs into aligned visual and latent action tokens. We then pretrain our WAM to jointly model future visual states and the latent actions that connect them under language instructions, followed by adaptation to real robot trajectories for closed-loop manipulation. Experiments on real-world manipulation tasks and simulation benchmarks show that RepWAM delivers strong performance across diverse manipulation settings, while ablations highlight the value of semantic visual-action tokenization over reconstruction-oriented alternatives. These results establish representation visual-action tokenization as a promising foundation for world action models and a step toward generalist robot policies. Code and weights will be available at https://github.com/wdrink/RepWAM.
ARM: An AutoRegressive Large Multimodal Model with Unified Discrete Representations
Jun 09, 2026This paper introduces ARM, a discrete representation-based AutoRegressive Model that unifies image understanding, generation, and editing within a next-token prediction framework. ARM is built on three efforts: first, we train a discrete semantic visual tokenizer that maps images into compact token sequences. Our tokenizer is supervised with multiple objectives that jointly promote semantic discriminability, language alignment and faithful reconstruction, thereby supporting diverse tasks in a shared latent space. With this, we train a 7B autoregressive model over large-scale text and image token sequences, seamlessly developing vision-language perception and generation capabilities. Finally, to further improve preference-aligned behavior for text-to-image generation and instruction-guided editing, ARM applies reinforcement learning (RL) to optimize task-level objectives such as visual quality, instruction adherence, and edit consistency. Surprisingly, the results show that RL not only substantially improves performance on the target tasks (e.g., raising WISE overall from 0.50 to 0.56, GEdit-Bench-EN G_O from 5.75 to 6.68), but also induces cross-task synergy between text-to-image generation and editing. Collectively, these findings highlight autoregressive modeling, when paired with strong representations and preference optimization, as a scalable foundation for multimodal intelligence. Code: https://github.com/wdrink/ARM.
IDEAL: In-DEpth ALignment Makes A Discrete Representation AutoEncoder
Jun 09, 2026Built on pretrained vision foundation models (VFMs), representation autoencoders (RAEs) have recently emerged as a promising approach for constructing semantically rich latent spaces for image generation. However, their reconstruction quality often remains suboptimal, largely because deep VFM representations do not preserve sufficient fine-grained visual detail. This limitation becomes even more severe after discretization, where missing low-level information is difficult to recover. In fact, we observe that shallow VFM features retain considerably richer local appearance and structural detail, which complements the high-level semantics carried by deep features used in existing RAEs. Motivated by this complementary property, we propose Ideal, an In-depth Alignment framework for discrete representation autoencoding. By jointly aligning quantized tokens with both shallow and deep VFM features, Ideal enables the resulting discrete visual tokens to preserve both visual fidelity and rich semantics. Extensive experiments demonstrate that Ideal yields superior reconstruction performance, achieving 0.61 rFID on ImageNet and outperforming the previous best method by 0.28. When used for autoregressive image generation, Ideal further produces a gFID of 1.89, establishing a new state of the art for autoregressive image generation.
OmniGen-AR: AutoRegressive Any-to-Image Generation
Jun 08, 2026Autoregressive (AR) models have demonstrated strong potential in visual generation, offering superior performance with simple architectures and optimization objectives. However, existing methods are typically limited to single-modality conditions, e.g., text, restricting their applicability in real-world scenarios that demand image synthesis from diverse controls. In this work, we present OmniGen-AR, a unified autoregressive framework for Any-to-Image generation. By discretizing various visual conditions through a shared visual tokenizer and text prompts with a text tokenizer, OmniGen-AR supports a broad spectrum of conditional inputs within a single model, including text (text-to-image generation), spatial signals (segmentation-to-image and depth-to-image), and visual context (image editing, frame prediction, and text-to-video generation). To mitigate the risk of information leakage from condition tokens to content tokens, we introduce Disentangled Causal Attention (DCA), which separates the full-sequence causal mask into condition causal attention and content causal attention. It serves as a training-time regularizer without affecting the standard next-token prediction during inference. With this design, OmniGen-AR achieves new state-of-the-art or at least competitive results across a range of benchmark, e.g., 0.63 on GenEval and 80.02 on VBench, demonstrating its effectiveness in flexible and high-fidelity visual generation.
DisCo: World Models with Discrete Camera Motion Control
Jun 06, 2026Controllable video world models target interactive world exploration, where models must faithfully execute explicit action commands while preserving visual quality and temporal coherence. However, most existing approaches rely on continuous camera trajectories as action conditions, which often lead to unreliable action following, especially under complex motion sequences. In this work, we identify action representation entanglement as a key bottleneck in controllable video generation, and show that continuous camera representations lead to high feature similarity across distinct motion patterns, degrading action controllability. Based on this insight, we propose DisCo, a controllable video world model that conditions generation on a compact set of discrete action primitives to improve action separability. We further introduce DisCoBench, a comprehensive benchmark for evaluating the ability of models in short-term, long-horizon, and highly dynamic exploration scenarios. Extensive experiments demonstrate that DisCo achieves significantly more reliable action following while preserving visual quality.
FluxMem: Adaptive Hierarchical Memory for Streaming Video Understanding
Mar 02, 2026This paper presents FluxMem, a training-free framework for efficient streaming video understanding. FluxMem adaptively compresses redundant visual memory through a hierarchical, two-stage design: (1) a Temporal Adjacency Selection (TAS) module removes redundant visual tokens across adjacent frames, and (2) a Spatial Domain Consolidation (SDC) module further merges spatially repetitive regions within each frame into compact representations. To adapt effectively to dynamic scenes, we introduce a self-adaptive token compression mechanism in both TAS and SDC, which automatically determines the compression rate based on intrinsic scene statistics rather than manual tuning. Extensive experiments demonstrate that FluxMem achieves new state-of-the-art results on existing online video benchmarks, reaching 76.4 on StreamingBench and 67.2 on OVO-Bench under real-time settings, while reducing latency by 69.9% and peak GPU memory by 34.5% on OVO-Bench. Furthermore, it maintains strong offline performance, achieving 73.1 on MLVU while using 65% fewer visual tokens.
VideoLoom: A Video Large Language Model for Joint Spatial-Temporal Understanding
Jan 12, 2026This paper presents VideoLoom, a unified Video Large Language Model (Video LLM) for joint spatial-temporal understanding. To facilitate the development of fine-grained spatial and temporal localization capabilities, we curate LoomData-8.7k, a human-centric video dataset with temporally grounded and spatially localized captions. With this, VideoLoom achieves state-of-the-art or highly competitive performance across a variety of spatial and temporal benchmarks (e.g., 63.1 J&F on ReVOS for referring video object segmentation, and 48.3 R1@0.7 on Charades-STA for temporal grounding). In addition, we introduce LoomBench, a novel benchmark consisting of temporal, spatial, and compositional video-question pairs, enabling a comprehensive evaluation of Video LLMs from diverse aspects. Collectively, these contributions offer a universal and effective suite for joint spatial-temporal video understanding, setting a new standard in multimodal intelligence.
TempoMaster: Efficient Long Video Generation via Next-Frame-Rate Prediction
Nov 16, 2025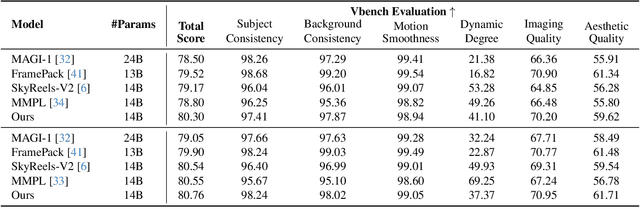
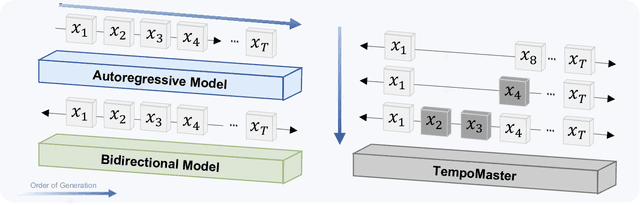
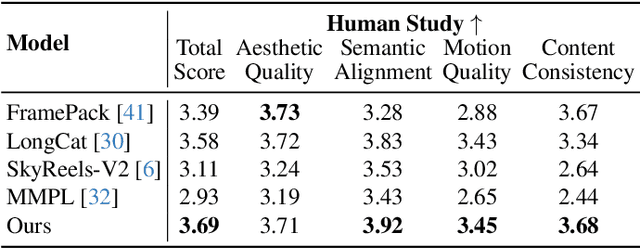
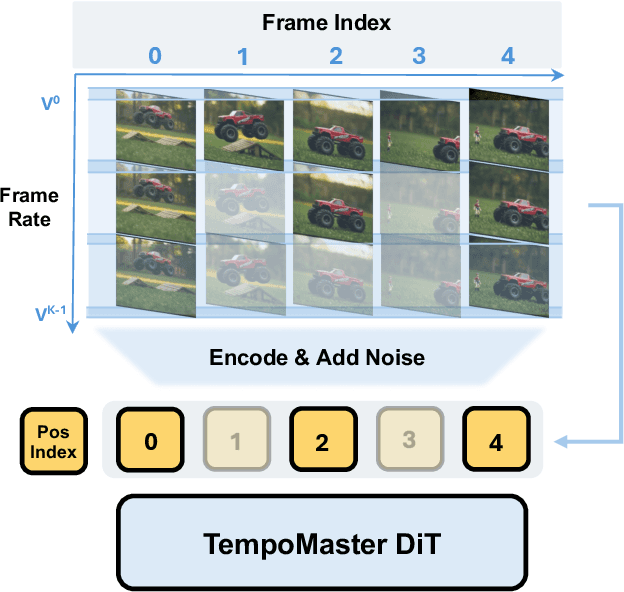
We present TempoMaster, a novel framework that formulates long video generation as next-frame-rate prediction. Specifically, we first generate a low-frame-rate clip that serves as a coarse blueprint of the entire video sequence, and then progressively increase the frame rate to refine visual details and motion continuity. During generation, TempoMaster employs bidirectional attention within each frame-rate level while performing autoregression across frame rates, thus achieving long-range temporal coherence while enabling efficient and parallel synthesis. Extensive experiments demonstrate that TempoMaster establishes a new state-of-the-art in long video generation, excelling in both visual and temporal quality.
Rethinking Discrete Tokens: Treating Them as Conditions for Continuous Autoregressive Image Synthesis
Jul 02, 2025Recent advances in large language models (LLMs) have spurred interests in encoding images as discrete tokens and leveraging autoregressive (AR) frameworks for visual generation. However, the quantization process in AR-based visual generation models inherently introduces information loss that degrades image fidelity. To mitigate this limitation, recent studies have explored to autoregressively predict continuous tokens. Unlike discrete tokens that reside in a structured and bounded space, continuous representations exist in an unbounded, high-dimensional space, making density estimation more challenging and increasing the risk of generating out-of-distribution artifacts. Based on the above findings, this work introduces DisCon (Discrete-Conditioned Continuous Autoregressive Model), a novel framework that reinterprets discrete tokens as conditional signals rather than generation targets. By modeling the conditional probability of continuous representations conditioned on discrete tokens, DisCon circumvents the optimization challenges of continuous token modeling while avoiding the information loss caused by quantization. DisCon achieves a gFID score of 1.38 on ImageNet 256$\times$256 generation, outperforming state-of-the-art autoregressive approaches by a clear margin.