 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Generalization from Embedding Dimension and Distributional Convergence
Jan 30, 2026Deep neural networks often generalize well despite heavy over-parameterization, challenging classical parameter-based analyses. We study generalization from a representation-centric perspective and analyze how the geometry of learned embeddings controls predictive performance for a fixed trained model. We show that population risk can be bounded by two factors: (i) the intrinsic dimension of the embedding distribution, which determines the convergence rate of empirical embedding distribution to the population distribution in Wasserstein distance, and (ii) the sensitivity of the downstream mapping from embeddings to predictions, characterized by Lipschitz constants. Together, these yield an embedding-dependent error bound that does not rely on parameter counts or hypothesis class complexity. At the final embedding layer, architectural sensitivity vanishes and the bound is dominated by embedding dimension, explaining its strong empirical correlation with generalization performance. Experiments across architectures and datasets validate the theory and demonstrate the utility of embedding-based diagnostics.
Local Intrinsic Dimension of Representations Predicts Alignment and Generalization in AI Models and Human Brain
Jan 30, 2026Recent work has found that neural networks with stronger generalization tend to exhibit higher representational alignment with one another across architectures and training paradigms. In this work, we show that models with stronger generalization also align more strongly with human neural activity. Moreover, generalization performance, model--model alignment, and model--brain alignment are all significantly correlated with each other. We further show that these relationships can be explained by a single geometric property of learned representations: the local intrinsic dimension of embeddings. Lower local dimension is consistently associated with stronger model--model alignment, stronger model--brain alignment, and better generalization, whereas global dimension measures fail to capture these effects. Finally, we find that increasing model capacity and training data scale systematically reduces local intrinsic dimension, providing a geometric account of the benefits of scaling. Together, our results identify local intrinsic dimension as a unifying descriptor of representational convergence in artificial and biological systems.
PALM-Bench: A Comprehensive Benchmark for Personalized Audio-Language Models
Jan 07, 2026Large Audio-Language Models (LALMs) have demonstrated strong performance in audio understanding and generation. Yet, our extensive benchmarking reveals that their behavior is largely generic (e.g., summarizing spoken content) and fails to adequately support personalized question answering (e.g., summarizing what my best friend says). In contrast, human conditions their interpretation and decision-making on each individual's personal context. To bridge this gap, we formalize the task of Personalized LALMs (PALM) for recognizing personal concepts and reasoning within personal context. Moreover, we create the first benchmark (PALM-Bench) to foster the methodological advances in PALM and enable structured evaluation on several tasks across multi-speaker scenarios. Our extensive experiments on representative open-source LALMs, show that existing training-free prompting and supervised fine-tuning strategies, while yield improvements, remains limited in modeling personalized knowledge and transferring them across tasks robustly. Data and code will be released.
EverybodyDance: Bipartite Graph-Based Identity Correspondence for Multi-Character Animation
Dec 18, 2025
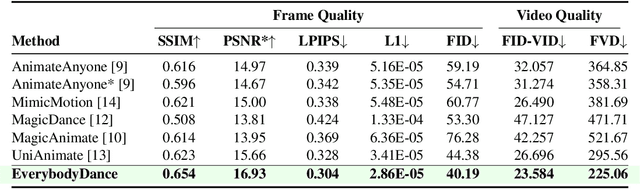

Consistent pose-driven character animation has achieved remarkable progress in single-character scenarios. However, extending these advances to multi-character settings is non-trivial, especially when position swap is involved. Beyond mere scaling, the core challenge lies in enforcing correct Identity Correspondence (IC) between characters in reference and generated frames. To address this, we introduce EverybodyDance, a systematic solution targeting IC correctness in multi-character animation. EverybodyDance is built around the Identity Matching Graph (IMG), which models characters in the generated and reference frames as two node sets in a weighted complete bipartite graph. Edge weights, computed via our proposed Mask-Query Attention (MQA), quantify the affinity between each pair of characters. Our key insight is to formalize IC correctness as a graph structural metric and to optimize it during training. We also propose a series of targeted strategies tailored for multi-character animation, including identity-embedded guidance, a multi-scale matching strategy, and pre-classified sampling, which work synergistically. Finally, to evaluate IC performance, we curate the Identity Correspondence Evaluation benchmark, dedicated to multi-character IC correctness. Extensive experiments demonstrate that EverybodyDance substantially outperforms state-of-the-art baselines in both IC and visual fidelity.
Scaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
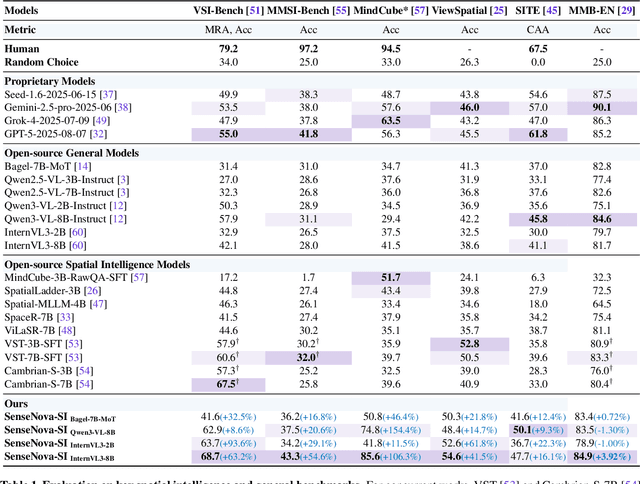


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
SRSplat: Feed-Forward Super-Resolution Gaussian Splatting from Sparse Multi-View Images
Nov 15, 2025Feed-forward 3D reconstruction from sparse, low-resolution (LR) images is a crucial capability for real-world applications, such as autonomous driving and embodied AI. However, existing methods often fail to recover fine texture details. This limitation stems from the inherent lack of high-frequency information in LR inputs. To address this, we propose \textbf{SRSplat}, a feed-forward framework that reconstructs high-resolution 3D scenes from only a few LR views. Our main insight is to compensate for the deficiency of texture information by jointly leveraging external high-quality reference images and internal texture cues. We first construct a scene-specific reference gallery, generated for each scene using Multimodal Large Language Models (MLLMs) and diffusion models. To integrate this external information, we introduce the \textit{Reference-Guided Feature Enhancement (RGFE)} module, which aligns and fuses features from the LR input images and their reference twin image. Subsequently, we train a decoder to predict the Gaussian primitives using the multi-view fused feature obtained from \textit{RGFE}. To further refine predicted Gaussian primitives, we introduce \textit{Texture-Aware Density Control (TADC)}, which adaptively adjusts Gaussian density based on the internal texture richness of the LR inputs. Extensive experiments demonstrate that our SRSplat outperforms existing methods on various datasets, including RealEstate10K, ACID, and DTU, and exhibits strong cross-dataset and cross-resolution generalization capabilities.
SPAN: Benchmarking and Improving Cross-Calendar Temporal Reasoning of Large Language Models
Nov 13, 2025We introduce SPAN, a cross-calendar temporal reasoning benchmark, which requires LLMs to perform intra-calendar temporal reasoning and inter-calendar temporal conversion. SPAN features ten cross-calendar temporal reasoning directions, two reasoning types, and two question formats across six calendars. To enable time-variant and contamination-free evaluation, we propose a template-driven protocol for dynamic instance generation that enables assessment on a user-specified Gregorian date. We conduct extensive experiments on both open- and closed-source state-of-the-art (SOTA) LLMs over a range of dates spanning 100 years from 1960 to 2060. Our evaluations show that these LLMs achieve an average accuracy of only 34.5%, with none exceeding 80%, indicating that this task remains challenging. Through in-depth analysis of reasoning types, question formats, and temporal reasoning directions, we identify two key obstacles for LLMs: Future-Date Degradation and Calendar Asymmetry Bias. To strengthen LLMs' cross-calendar temporal reasoning capability, we further develop an LLM-powered Time Agent that leverages tool-augmented code generation. Empirical results show that Time Agent achieves an average accuracy of 95.31%, outperforming several competitive baselines, highlighting the potential of tool-augmented code generation to advance cross-calendar temporal reasoning. We hope this work will inspire further efforts toward more temporally and culturally adaptive LLMs.
The Quest for Generalizable Motion Generation: Data, Model, and Evaluation
Oct 30, 2025Despite recent advances in 3D human motion generation (MoGen) on standard benchmarks, existing models still face a fundamental bottleneck in their generalization capability. In contrast, adjacent generative fields, most notably video generation (ViGen), have demonstrated remarkable generalization in modeling human behaviors, highlighting transferable insights that MoGen can leverage. Motivated by this observation, we present a comprehensive framework that systematically transfers knowledge from ViGen to MoGen across three key pillars: data, modeling, and evaluation. First, we introduce ViMoGen-228K, a large-scale dataset comprising 228,000 high-quality motion samples that integrates high-fidelity optical MoCap data with semantically annotated motions from web videos and synthesized samples generated by state-of-the-art ViGen models. The dataset includes both text-motion pairs and text-video-motion triplets, substantially expanding semantic diversity. Second, we propose ViMoGen, a flow-matching-based diffusion transformer that unifies priors from MoCap data and ViGen models through gated multimodal conditioning. To enhance efficiency, we further develop ViMoGen-light, a distilled variant that eliminates video generation dependencies while preserving strong generalization. Finally, we present MBench, a hierarchical benchmark designed for fine-grained evaluation across motion quality, prompt fidelity, and generalization ability. Extensive experiments show that our framework significantly outperforms existing approaches in both automatic and human evaluations. The code, data, and benchmark will be made publicly available.
Has GPT-5 Achieved Spatial Intelligence? An Empirical Study
Aug 18, 2025Multi-modal models have achieved remarkable progress in recent years. Nevertheless, they continue to exhibit notable limitations in spatial understanding and reasoning, which are fundamental capabilities to achieving artificial general intelligence. With the recent release of GPT-5, allegedly the most powerful AI model to date, it is timely to examine where the leading models stand on the path toward spatial intelligence. First, we propose a comprehensive taxonomy of spatial tasks that unifies existing benchmarks and discuss the challenges in ensuring fair evaluation. We then evaluate state-of-the-art proprietary and open-source models on eight key benchmarks, at a cost exceeding one billion total tokens. Our empirical study reveals that (1) GPT-5 demonstrates unprecedented strength in spatial intelligence, yet (2) still falls short of human performance across a broad spectrum of tasks. Moreover, we (3) identify the more challenging spatial intelligence problems for multi-modal models, and (4) proprietary models do not exhibit a decisive advantage when facing the most difficult problems. In addition, we conduct a qualitative evaluation across a diverse set of scenarios that are intuitive for humans yet fail even the most advanced multi-modal models.
PyVision: Agentic Vision with Dynamic Tooling
Jul 10, 2025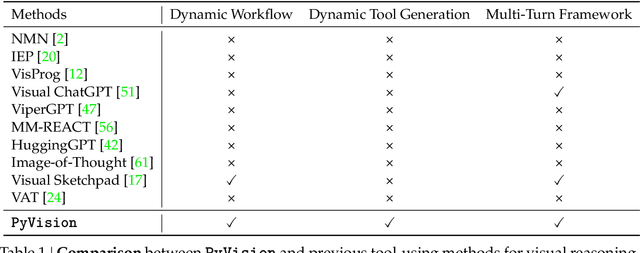
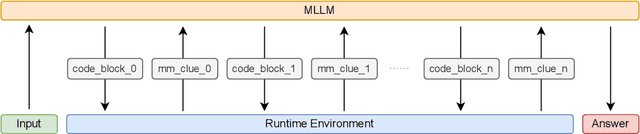
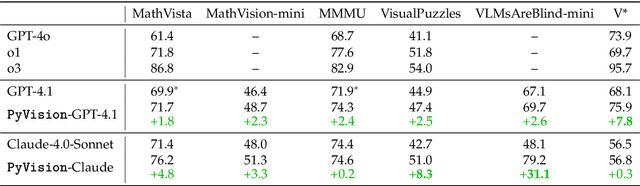
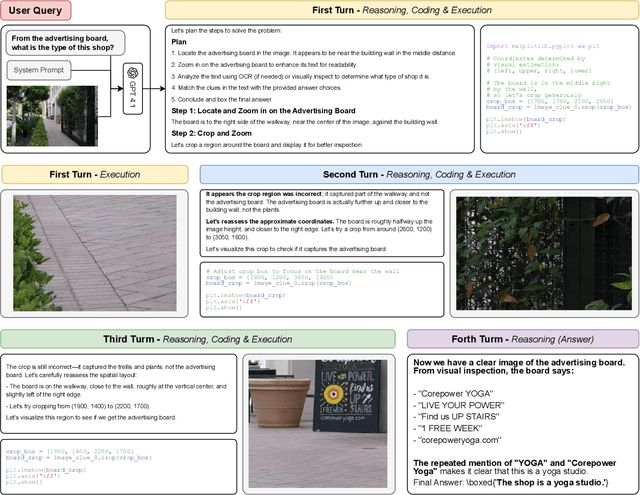
LLMs are increasingly deployed as agents, systems capable of planning, reasoning, and dynamically calling external tools. However, in visual reasoning, prior approaches largely remain limited by predefined workflows and static toolsets. In this report, we present PyVision, an interactive, multi-turn framework that enables MLLMs to autonomously generate, execute, and refine Python-based tools tailored to the task at hand, unlocking flexible and interpretable problem-solving. We develop a taxonomy of the tools created by PyVision and analyze their usage across a diverse set of benchmarks. Quantitatively, PyVision achieves consistent performance gains, boosting GPT-4.1 by +7.8% on V* and Claude-4.0-Sonnet by +31.1% on VLMsAreBlind-mini. These results point to a broader shift: dynamic tooling allows models not just to use tools, but to invent them, advancing toward more agentic visual reasoning.