 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Spatial Intelligence with Multimodal Foundation Models
Nov 17, 2025
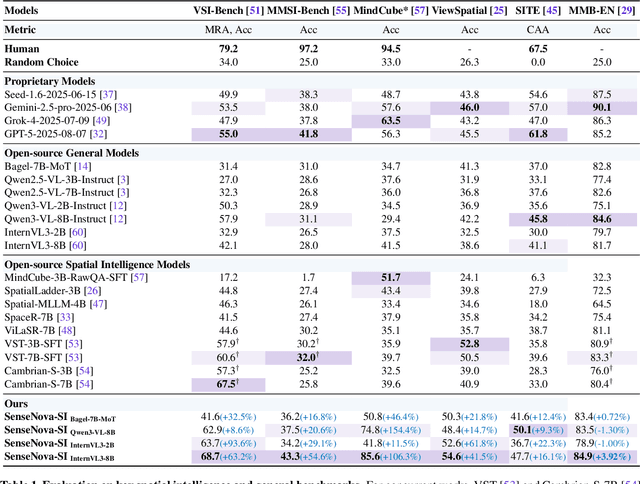


Despite remarkable progress, multimodal foundation models still exhibit surprising deficiencies in spatial intelligence. In this work, we explore scaling up multimodal foundation models to cultivate spatial intelligence within the SenseNova-SI family, built upon established multimodal foundations including visual understanding models (i.e., Qwen3-VL and InternVL3) and unified understanding and generation models (i.e., Bagel). We take a principled approach to constructing high-performing and robust spatial intelligence by systematically curating SenseNova-SI-8M: eight million diverse data samples under a rigorous taxonomy of spatial capabilities. SenseNova-SI demonstrates unprecedented performance across a broad range of spatial intelligence benchmarks: 68.7% on VSI-Bench, 43.3% on MMSI, 85.6% on MindCube, 54.6% on ViewSpatial, and 50.1% on SITE, while maintaining strong general multimodal understanding (e.g., 84.9% on MMBench-En). More importantly, we analyze the impact of data scaling, discuss early signs of emergent generalization capabilities enabled by diverse data training, analyze the risk of overfitting and language shortcuts, present a preliminary study on spatial chain-of-thought reasoning, and validate the potential downstream application. SenseNova-SI is an ongoing project, and this report will be updated continuously. All newly trained multimodal foundation models are publicly released to facilitate further research in this direction.
SMPLest-X: Ultimate Scaling for Expressive Human Pose and Shape Estimation
Jan 16, 2025Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods focus on training innovative architectural designs on confined datasets. In this work, we investigate the impact of scaling up EHPS towards a family of generalist foundation models. 1) For data scaling, we perform a systematic investigation on 40 EHPS datasets, encompassing a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. Ultimately, we achieve diminishing returns at 10M training instances from diverse data sources. 2) For model scaling, we take advantage of vision transformers (up to ViT-Huge as the backbone) to study the scaling law of model sizes in EHPS. To exclude the influence of algorithmic design, we base our experiments on two minimalist architectures: SMPLer-X, which consists of an intermediate step for hand and face localization, and SMPLest-X, an even simpler version that reduces the network to its bare essentials and highlights significant advances in the capture of articulated hands. With big data and the large model, the foundation models exhibit strong performance across diverse test benchmarks and excellent transferability to even unseen environments. Moreover, our finetuning strategy turns the generalist into specialist models, allowing them to achieve further performance boosts. Notably, our foundation models consistently deliver state-of-the-art results on seven benchmarks such as AGORA, UBody, EgoBody, and our proposed SynHand dataset for comprehensive hand evaluation. (Code is available at: https://github.com/wqyin/SMPLest-X).
Disco4D: Disentangled 4D Human Generation and Animation from a Single Image
Sep 25, 2024

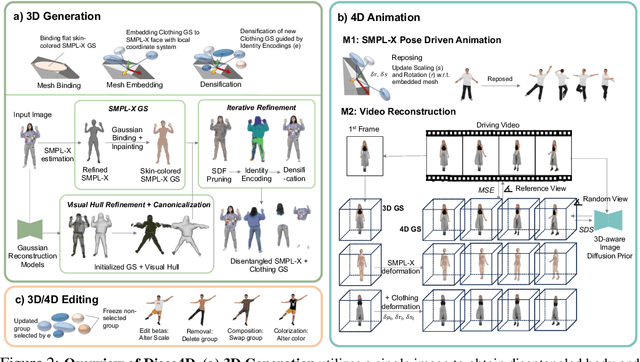

We present \textbf{Disco4D}, a novel Gaussian Splatting framework for 4D human generation and animation from a single image. Different from existing methods, Disco4D distinctively disentangles clothings (with Gaussian models) from the human body (with SMPL-X model), significantly enhancing the generation details and flexibility. It has the following technical innovations. \textbf{1)} Disco4D learns to efficiently fit the clothing Gaussians over the SMPL-X Gaussians. \textbf{2)} It adopts diffusion models to enhance the 3D generation process, \textit{e.g.}, modeling occluded parts not visible in the input image. \textbf{3)} It learns an identity encoding for each clothing Gaussian to facilitate the separation and extraction of clothing assets. Furthermore, Disco4D naturally supports 4D human animation with vivid dynamics. Extensive experiments demonstrate the superiority of Disco4D on 4D human generation and animation tasks. Our visualizations can be found in \url{https://disco-4d.github.io/}.
SMPLer-X: Scaling Up Expressive Human Pose and Shape Estimation
Sep 29, 2023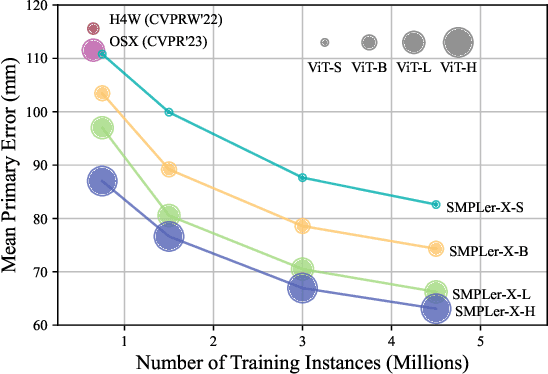
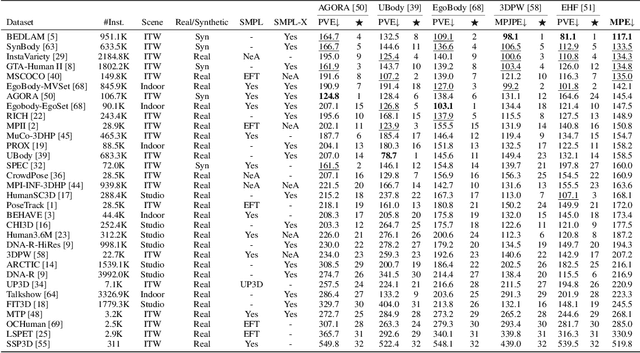
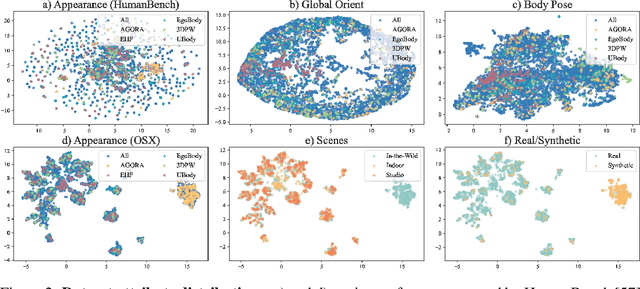
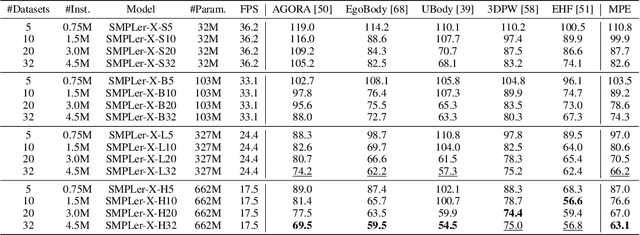
Expressive human pose and shape estimation (EHPS) unifies body, hands, and face motion capture with numerous applications. Despite encouraging progress, current state-of-the-art methods still depend largely on confined training datasets. In this work, we investigate scaling up EHPS towards the first generalist foundation model (dubbed SMPLer-X), with up to ViT-Huge as the backbone and training with up to 4.5M instances from diverse data sources. With big data and the large model, SMPLer-X exhibits strong performance across diverse test benchmarks and excellent transferability to even unseen environments. 1) For the data scaling, we perform a systematic investigation on 32 EHPS datasets, encompassing a wide range of scenarios that a model trained on any single dataset cannot handle. More importantly, capitalizing on insights obtained from the extensive benchmarking process, we optimize our training scheme and select datasets that lead to a significant leap in EHPS capabilities. 2) For the model scaling, we take advantage of vision transformers to study the scaling law of model sizes in EHPS. Moreover, our finetuning strategy turn SMPLer-X into specialist models, allowing them to achieve further performance boosts. Notably, our foundation model SMPLer-X consistently delivers state-of-the-art results on seven benchmarks such as AGORA (107.2 mm NMVE), UBody (57.4 mm PVE), EgoBody (63.6 mm PVE), and EHF (62.3 mm PVE without finetuning).
Benchmarking and Analyzing 3D Human Pose and Shape Estimation Beyond Algorithms
Sep 21, 2022

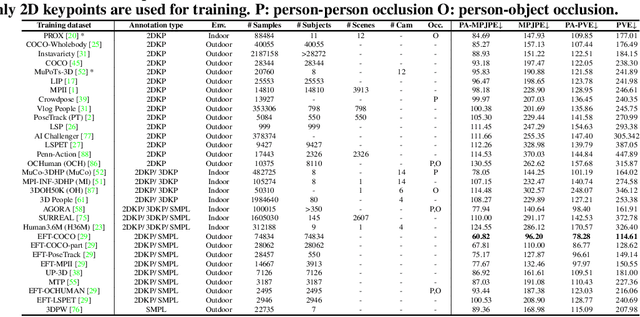
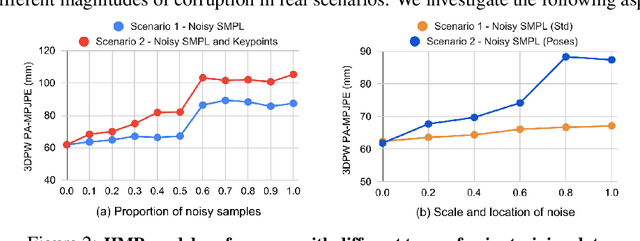
3D human pose and shape estimation (a.k.a. "human mesh recovery") has achieved substantial progress. Researchers mainly focus on the development of novel algorithms, while less attention has been paid to other critical factors involved. This could lead to less optimal baselines, hindering the fair and faithful evaluations of newly designed methodologies. To address this problem, this work presents the first comprehensive benchmarking study from three under-explored perspectives beyond algorithms. 1) Datasets. An analysis on 31 datasets reveals the distinct impacts of data samples: datasets featuring critical attributes (i.e. diverse poses, shapes, camera characteristics, backbone features) are more effective. Strategical selection and combination of high-quality datasets can yield a significant boost to the model performance. 2) Backbones. Experiments with 10 backbones, ranging from CNNs to transformers, show the knowledge learnt from a proximity task is readily transferable to human mesh recovery. 3) Training strategies. Proper augmentation techniques and loss designs are crucial. With the above findings, we achieve a PA-MPJPE of 47.3 mm on the 3DPW test set with a relatively simple model. More importantly, we provide strong baselines for fair comparisons of algorithms, and recommendations for building effective training configurations in the future. Codebase is available at http://github.com/smplbody/hmr-benchmarks