 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistorted or Fabricated? A Survey on Hallucination in Video LLMs
Apr 14, 2026Despite significant progress in video-language modeling, hallucinations remain a persistent challenge in Video Large Language Models (Vid-LLMs), referring to outputs that appear plausible yet contradict the content of the input video. This survey presents a comprehensive analysis of hallucinations in Vid-LLMs and introduces a systematic taxonomy that categorizes them into two core types: dynamic distortion and content fabrication, each comprising two subtypes with representative cases. Building on this taxonomy, we review recent advances in the evaluation and mitigation of hallucinations, covering key benchmarks, metrics, and intervention strategies. We further analyze the root causes of dynamic distortion and content fabrication, which often result from limited capacity for temporal representation and insufficient visual grounding. These insights inform several promising directions for future work, including the development of motion-aware visual encoders and the integration of counterfactual learning techniques. This survey consolidates scattered progress to foster a systematic understanding of hallucinations in Vid-LLMs, laying the groundwork for building robust and reliable video-language systems. An up-to-date curated list of related works is maintained at https://github.com/hukcc/Awesome-Video-Hallucination .
Bridging Semantic and Kinematic Conditions with Diffusion-based Discrete Motion Tokenizer
Mar 19, 2026Prior motion generation largely follows two paradigms: continuous diffusion models that excel at kinematic control, and discrete token-based generators that are effective for semantic conditioning. To combine their strengths, we propose a three-stage framework comprising condition feature extraction (Perception), discrete token generation (Planning), and diffusion-based motion synthesis (Control). Central to this framework is MoTok, a diffusion-based discrete motion tokenizer that decouples semantic abstraction from fine-grained reconstruction by delegating motion recovery to a diffusion decoder, enabling compact single-layer tokens while preserving motion fidelity. For kinematic conditions, coarse constraints guide token generation during planning, while fine-grained constraints are enforced during control through diffusion-based optimization. This design prevents kinematic details from disrupting semantic token planning. On HumanML3D, our method significantly improves controllability and fidelity over MaskControl while using only one-sixth of the tokens, reducing trajectory error from 0.72 cm to 0.08 cm and FID from 0.083 to 0.029. Unlike prior methods that degrade under stronger kinematic constraints, ours improves fidelity, reducing FID from 0.033 to 0.014.
InfiniteDance: Scalable 3D Dance Generation Towards in-the-wild Generalization
Mar 10, 2026Although existing 3D dance generation methods perform well in controlled scenarios, they often struggle to generalize in the wild. When conditioned on unseen music, existing methods often produce unstructured or physically implausible dance, largely due to limited music-to-dance data and restricted model capacity. This work aims to push the frontier of generalizable 3D dance generation by scaling up both data and model design. (1) On the data side, we develop a fully automated pipeline that reconstructs high-fidelity 3D dance motions from monocular videos. To eliminate the physical artifacts prevalent in existing reconstruction methods, we introduce a Foot Restoration Diffusion Model (FRDM) guided by foot-contact and geometric constraints that enforce physical plausibility while preserving kinematic smoothness and expressiveness, resulting in a diverse, high-quality multimodal 3D dance dataset totaling 100.69 hours. (2) On model design, we propose Choreographic LLaMA (ChoreoLLaMA), a scalable LLaMA-based architecture. To enhance robustness under unfamiliar music conditions, we integrate a retrieval-augmented generation (RAG) module that injects reference dance as a prompt. Additionally, we design a slow/fast-cadence Mixture-of-Experts (MoE) module that enables ChoreoLLaMA to smoothly adapt motion rhythms across varying music tempos. Extensive experiments across diverse dance genres show that our approach surpasses existing methods in both qualitative and quantitative evaluations, marking a step toward scalable, real-world 3D dance generation. Code, models, and data will be released.
NECromancer: Breathing Life into Skeletons via BVH Animation
Feb 06, 2026Motion tokenization is a key component of generalizable motion models, yet most existing approaches are restricted to species-specific skeletons, limiting their applicability across diverse morphologies. We propose NECromancer (NEC), a universal motion tokenizer that operates directly on arbitrary BVH skeletons. NEC consists of three components: (1) an Ontology-aware Skeletal Graph Encoder (OwO) that encodes structural priors from BVH files, including joint semantics, rest-pose offsets, and skeletal topology, into skeletal embeddings; (2) a Topology-Agnostic Tokenizer (TAT) that compresses motion sequences into a universal, topology-invariant discrete representation; and (3) the Unified BVH Universe (UvU), a large-scale dataset aggregating BVH motions across heterogeneous skeletons. Experiments show that NEC achieves high-fidelity reconstruction under substantial compression and effectively disentangles motion from skeletal structure. The resulting token space supports cross-species motion transfer, composition, denoising, generation with token-based models, and text-motion retrieval, establishing a unified framework for motion analysis and synthesis across diverse morphologies. Demo page: https://animotionlab.github.io/NECromancer/
DiMo: Discrete Diffusion Modeling for Motion Generation and Understanding
Feb 04, 2026Prior masked modeling motion generation methods predominantly study text-to-motion. We present DiMo, a discrete diffusion-style framework, which extends masked modeling to bidirectional text--motion understanding and generation. Unlike GPT-style autoregressive approaches that tokenize motion and decode sequentially, DiMo performs iterative masked token refinement, unifying Text-to-Motion (T2M), Motion-to-Text (M2T), and text-free Motion-to-Motion (M2M) within a single model. This decoding paradigm naturally enables a quality-latency trade-off at inference via the number of refinement steps.We further improve motion token fidelity with residual vector quantization (RVQ) and enhance alignment and controllability with Group Relative Policy Optimization (GRPO). Experiments on HumanML3D and KIT-ML show strong motion quality and competitive bidirectional understanding under a unified framework. In addition, we demonstrate model ability in text-free motion completion, text-guided motion prediction and motion caption correction without architectural change.Additional qualitative results are available on our project page: https://animotionlab.github.io/DiMo/.
Rethinking Fine-Tuning: Unlocking Hidden Capabilities in Vision-Language Models
Dec 28, 2025Explorations in fine-tuning Vision-Language Models (VLMs), such as Low-Rank Adaptation (LoRA) from Parameter Efficient Fine-Tuning (PEFT), have made impressive progress. However, most approaches rely on explicit weight updates, overlooking the extensive representational structures already encoded in pre-trained models that remain underutilized. Recent works have demonstrated that Mask Fine-Tuning (MFT) can be a powerful and efficient post-training paradigm for language models. Instead of updating weights, MFT assigns learnable gating scores to each weight, allowing the model to reorganize its internal subnetworks for downstream task adaptation. In this paper, we rethink fine-tuning for VLMs from a structural reparameterization perspective grounded in MFT. We apply MFT to the language and projector components of VLMs with different language backbones and compare against strong PEFT baselines. Experiments show that MFT consistently surpasses LoRA variants and even full fine-tuning, achieving high performance without altering the frozen backbone. Our findings reveal that effective adaptation can emerge not only from updating weights but also from reestablishing connections among the model's existing knowledge. Code available at: https://github.com/Ming-K9/MFT-VLM
SWiT-4D: Sliding-Window Transformer for Lossless and Parameter-Free Temporal 4D Generation
Dec 11, 2025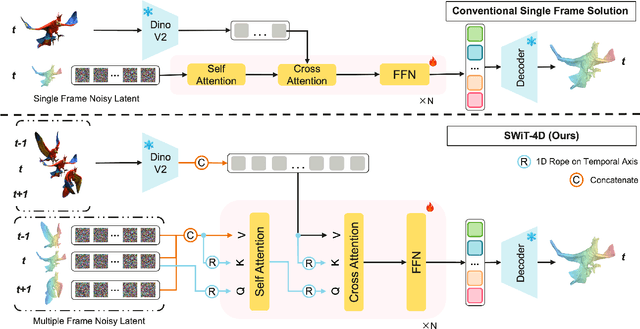
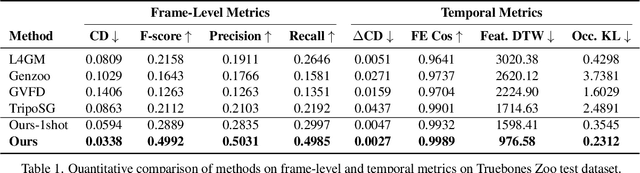
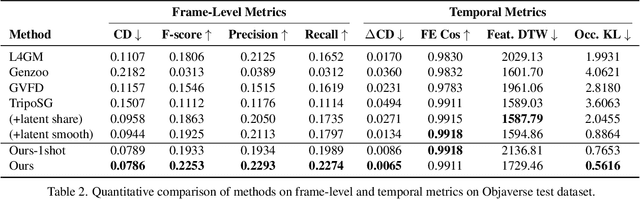

Despite significant progress in 4D content generation, the conversion of monocular videos into high-quality animated 3D assets with explicit 4D meshes remains considerably challenging. The scarcity of large-scale, naturally captured 4D mesh datasets further limits the ability to train generalizable video-to-4D models from scratch in a purely data-driven manner. Meanwhile, advances in image-to-3D generation, supported by extensive datasets, offer powerful prior models that can be leveraged. To better utilize these priors while minimizing reliance on 4D supervision, we introduce SWiT-4D, a Sliding-Window Transformer for lossless, parameter-free temporal 4D mesh generation. SWiT-4D integrates seamlessly with any Diffusion Transformer (DiT)-based image-to-3D generator, adding spatial-temporal modeling across video frames while preserving the original single-image forward process, enabling 4D mesh reconstruction from videos of arbitrary length. To recover global translation, we further introduce an optimization-based trajectory module tailored for static-camera monocular videos. SWiT-4D demonstrates strong data efficiency: with only a single short (<10s) video for fine-tuning, it achieves high-fidelity geometry and stable temporal consistency, indicating practical deployability under extremely limited 4D supervision. Comprehensive experiments on both in-domain zoo-test sets and challenging out-of-domain benchmarks (C4D, Objaverse, and in-the-wild videos) show that SWiT-4D consistently outperforms existing baselines in temporal smoothness. Project page: https://animotionlab.github.io/SWIT4D/
MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos
Dec 11, 2025Motion capture now underpins content creation far beyond digital humans, yet most existing pipelines remain species- or template-specific. We formalize this gap as Category-Agnostic Motion Capture (CAMoCap): given a monocular video and an arbitrary rigged 3D asset as a prompt, the goal is to reconstruct a rotation-based animation such as BVH that directly drives the specific asset. We present MoCapAnything, a reference-guided, factorized framework that first predicts 3D joint trajectories and then recovers asset-specific rotations via constraint-aware inverse kinematics. The system contains three learnable modules and a lightweight IK stage: (1) a Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh, and rendered images; (2) a Video Feature Extractor that computes dense visual descriptors and reconstructs a coarse 4D deforming mesh to bridge the gap between video and joint space; and (3) a Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories. We also curate Truebones Zoo with 1038 motion clips, each providing a standardized skeleton-mesh-render triad. Experiments on both in-domain benchmarks and in-the-wild videos show that MoCapAnything delivers high-quality skeletal animations and exhibits meaningful cross-species retargeting across heterogeneous rigs, enabling scalable, prompt-driven 3D motion capture for arbitrary assets. Project page: https://animotionlab.github.io/MoCapAnything/
Landmark Guided Visual Feature Extractor for Visual Speech Recognition with Limited Resource
Aug 10, 2025Visual speech recognition is a technique to identify spoken content in silent speech videos, which has raised significant attention in recent years. Advancements in data-driven deep learning methods have significantly improved both the speed and accuracy of recognition. However, these deep learning methods can be effected by visual disturbances, such as lightning conditions, skin texture and other user-specific features. Data-driven approaches could reduce the performance degradation caused by these visual disturbances using models pretrained on large-scale datasets. But these methods often require large amounts of training data and computational resources, making them costly. To reduce the influence of user-specific features and enhance performance with limited data, this paper proposed a landmark guided visual feature extractor. Facial landmarks are used as auxiliary information to aid in training the visual feature extractor. A spatio-temporal multi-graph convolutional network is designed to fully exploit the spatial locations and spatio-temporal features of facial landmarks. Additionally, a multi-level lip dynamic fusion framework is introduced to combine the spatio-temporal features of the landmarks with the visual features extracted from the raw video frames. Experimental results show that this approach performs well with limited data and also improves the model's accuracy on unseen speakers.
Semantics-Aware Human Motion Generation from Audio Instructions
May 29, 2025Recent advances in interactive technologies have highlighted the prominence of audio signals for semantic encoding. This paper explores a new task, where audio signals are used as conditioning inputs to generate motions that align with the semantics of the audio. Unlike text-based interactions, audio provides a more natural and intuitive communication method. However, existing methods typically focus on matching motions with music or speech rhythms, which often results in a weak connection between the semantics of the audio and generated motions. We propose an end-to-end framework using a masked generative transformer, enhanced by a memory-retrieval attention module to handle sparse and lengthy audio inputs. Additionally, we enrich existing datasets by converting descriptions into conversational style and generating corresponding audio with varied speaker identities. Experiments demonstrate the effectiveness and efficiency of the proposed framework, demonstrating that audio instructions can convey semantics similar to text while providing more practical and user-friendly interactions.