 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge Motion Model for Unified Multi-Modal Motion Generation
Paper and Code
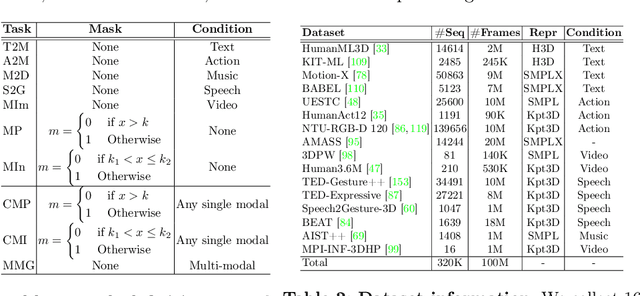
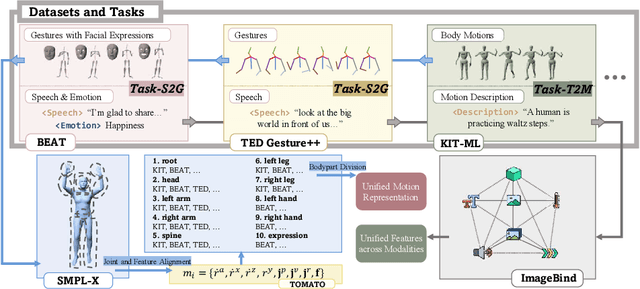
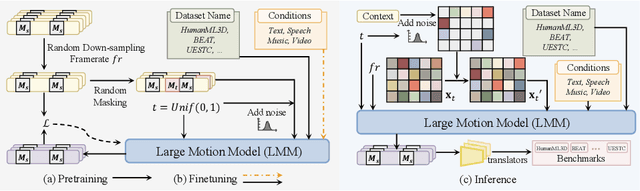
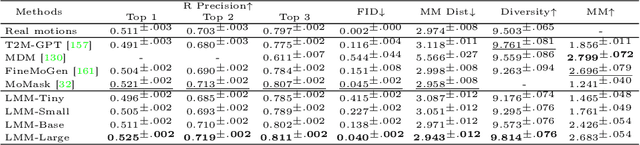
Human motion generation, a cornerstone technique in animation and video production, has widespread applications in various tasks like text-to-motion and music-to-dance. Previous works focus on developing specialist models tailored for each task without scalability. In this work, we present Large Motion Model (LMM), a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model. A unified motion model is appealing since it can leverage a wide range of motion data to achieve broad generalization beyond a single task. However, it is also challenging due to the heterogeneous nature of substantially different motion data and tasks. LMM tackles these challenges from three principled aspects: 1) Data: We consolidate datasets with different modalities, formats and tasks into a comprehensive yet unified motion generation dataset, MotionVerse, comprising 10 tasks, 16 datasets, a total of 320k sequences, and 100 million frames. 2) Architecture: We design an articulated attention mechanism ArtAttention that incorporates body part-aware modeling into Diffusion Transformer backbone. 3) Pre-Training: We propose a novel pre-training strategy for LMM, which employs variable frame rates and masking forms, to better exploit knowledge from diverse training data. Extensive experiments demonstrate that our generalist LMM achieves competitive performance across various standard motion generation tasks over state-of-the-art specialist models. Notably, LMM exhibits strong generalization capabilities and emerging properties across many unseen tasks. Additionally, our ablation studies reveal valuable insights about training and scaling up large motion models for future research.