 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural-Symbolic Message Passing with Dynamic Pruning
Jan 24, 2025



Complex Query Answering (CQA) over incomplete Knowledge Graphs (KGs) is a challenging task. Recently, a line of message-passing-based research has been proposed to solve CQA. However, they perform unsatisfactorily on negative queries and fail to address the noisy messages between variable nodes in the query graph. Moreover, they offer little interpretability and require complex query data and resource-intensive training. In this paper, we propose a Neural-Symbolic Message Passing (NSMP) framework based on pre-trained neural link predictors. By introducing symbolic reasoning and fuzzy logic, NSMP can generalize to arbitrary existential first order logic queries without requiring training while providing interpretable answers. Furthermore, we introduce a dynamic pruning strategy to filter out noisy messages between variable nodes. Experimental results show that NSMP achieves a strong performance. Additionally, through complexity analysis and empirical verification, we demonstrate the superiority of NSMP in inference time over the current state-of-the-art neural-symbolic method. Compared to this approach, NSMP demonstrates faster inference times across all query types on benchmark datasets, with speedup ranging from 2$\times$ to over 150$\times$.
A Flexible and Scalable Framework for Video Moment Search
Jan 09, 2025Video moment search, the process of finding relevant moments in a video corpus to match a user's query, is crucial for various applications. Existing solutions, however, often assume a single perfect matching moment, struggle with inefficient inference, and have limitations with hour-long videos. This paper introduces a flexible and scalable framework for retrieving a ranked list of moments from collection of videos in any length to match a text query, a task termed Ranked Video Moment Retrieval (RVMR). Our framework, called Segment-Proposal-Ranking (SPR), simplifies the search process into three independent stages: segment retrieval, proposal generation, and moment refinement with re-ranking. Specifically, videos are divided into equal-length segments with precomputed embeddings indexed offline, allowing efficient retrieval regardless of video length. For scalable online retrieval, both segments and queries are projected into a shared feature space to enable approximate nearest neighbor (ANN) search. Retrieved segments are then merged into coarse-grained moment proposals. Then a refinement and re-ranking module is designed to reorder and adjust timestamps of the coarse-grained proposals. Evaluations on the TVR-Ranking dataset demonstrate that our framework achieves state-of-the-art performance with significant reductions in computational cost and processing time. The flexible design also allows for independent improvements to each stage, making SPR highly adaptable for large-scale applications.
TVR-Ranking: A Dataset for Ranked Video Moment Retrieval with Imprecise Queries
Jul 09, 2024



In this paper, we propose the task of \textit{Ranked Video Moment Retrieval} (RVMR) to locate a ranked list of matching moments from a collection of videos, through queries in natural language. Although a few related tasks have been proposed and studied by CV, NLP, and IR communities, RVMR is the task that best reflects the practical setting of moment search. To facilitate research in RVMR, we develop the TVR-Ranking dataset, based on the raw videos and existing moment annotations provided in the TVR dataset. Our key contribution is the manual annotation of relevance levels for 94,442 query-moment pairs. We then develop the $NDCG@K, IoU\geq \mu$ evaluation metric for this new task and conduct experiments to evaluate three baseline models. Our experiments show that the new RVMR task brings new challenges to existing models and we believe this new dataset contributes to the research on multi-modality search. The dataset is available at \url{https://github.com/Ranking-VMR/TVR-Ranking}
Pathformer: Recursive Path Query Encoding for Complex Logical Query Answering
Jun 21, 2024Complex Logical Query Answering (CLQA) over incomplete knowledge graphs is a challenging task. Recently, Query Embedding (QE) methods are proposed to solve CLQA by performing multi-hop logical reasoning. However, most of them only consider historical query context information while ignoring future information, which leads to their failure to capture the complex dependencies behind the elements of a query. In recent years, the transformer architecture has shown a strong ability to model long-range dependencies between words. The bidirectional attention mechanism proposed by the transformer can solve the limitation of these QE methods regarding query context. Still, as a sequence model, it is difficult for the transformer to model complex logical queries with branch structure computation graphs directly. To this end, we propose a neural one-point embedding method called Pathformer based on the tree-like computation graph, i.e., query computation tree. Specifically, Pathformer decomposes the query computation tree into path query sequences by branches and then uses the transformer encoder to recursively encode these path query sequences to obtain the final query embedding. This allows Pathformer to fully utilize future context information to explicitly model the complex interactions between various parts of the path query. Experimental results show that Pathformer outperforms existing competitive neural QE methods, and we found that Pathformer has the potential to be applied to non-one-point embedding space.
Large Motion Model for Unified Multi-Modal Motion Generation
Apr 01, 2024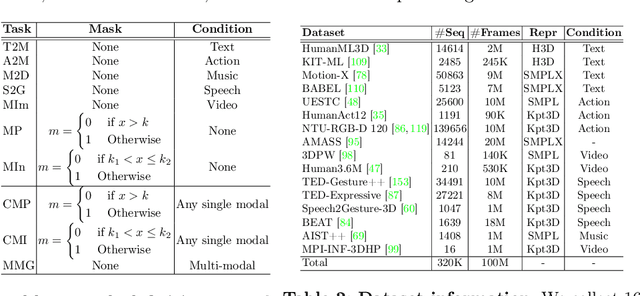
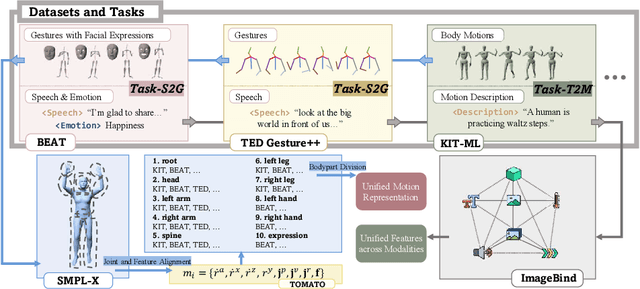
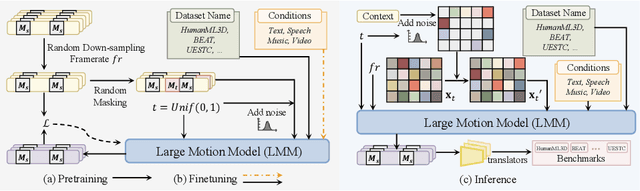
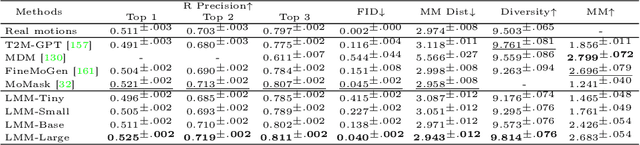
Human motion generation, a cornerstone technique in animation and video production, has widespread applications in various tasks like text-to-motion and music-to-dance. Previous works focus on developing specialist models tailored for each task without scalability. In this work, we present Large Motion Model (LMM), a motion-centric, multi-modal framework that unifies mainstream motion generation tasks into a generalist model. A unified motion model is appealing since it can leverage a wide range of motion data to achieve broad generalization beyond a single task. However, it is also challenging due to the heterogeneous nature of substantially different motion data and tasks. LMM tackles these challenges from three principled aspects: 1) Data: We consolidate datasets with different modalities, formats and tasks into a comprehensive yet unified motion generation dataset, MotionVerse, comprising 10 tasks, 16 datasets, a total of 320k sequences, and 100 million frames. 2) Architecture: We design an articulated attention mechanism ArtAttention that incorporates body part-aware modeling into Diffusion Transformer backbone. 3) Pre-Training: We propose a novel pre-training strategy for LMM, which employs variable frame rates and masking forms, to better exploit knowledge from diverse training data. Extensive experiments demonstrate that our generalist LMM achieves competitive performance across various standard motion generation tasks over state-of-the-art specialist models. Notably, LMM exhibits strong generalization capabilities and emerging properties across many unseen tasks. Additionally, our ablation studies reveal valuable insights about training and scaling up large motion models for future research.
Conditional Logical Message Passing Transformer for Complex Query Answering
Feb 20, 2024



Complex Query Answering (CQA) over Knowledge Graphs (KGs) is a challenging task. Given that KGs are usually incomplete, neural models are proposed to solve CQA by performing multi-hop logical reasoning. However, most of them cannot perform well on both one-hop and multi-hop queries simultaneously. Recent work proposes a logical message passing mechanism based on the pre-trained neural link predictors. While effective on both one-hop and multi-hop queries, it ignores the difference between the constant and variable nodes in a query graph. In addition, during the node embedding update stage, this mechanism cannot dynamically measure the importance of different messages, and whether it can capture the implicit logical dependencies related to a node and received messages remains unclear. In this paper, we propose Conditional Logical Message Passing Transformer (CLMPT), which considers the difference between constants and variables in the case of using pre-trained neural link predictors and performs message passing conditionally on the node type. We empirically verified that this approach can reduce computational costs without affecting performance. Furthermore, CLMPT uses the transformer to aggregate received messages and update the corresponding node embedding. Through the self-attention mechanism, CLMPT can assign adaptive weights to elements in an input set consisting of received messages and the corresponding node and explicitly model logical dependencies between various elements. Experimental results show that CLMPT is a new state-of-the-art neural CQA model.
Balancing the Causal Effects in Class-Incremental Learning
Feb 15, 2024Class-Incremental Learning (CIL) is a practical and challenging problem for achieving general artificial intelligence. Recently, Pre-Trained Models (PTMs) have led to breakthroughs in both visual and natural language processing tasks. Despite recent studies showing PTMs' potential ability to learn sequentially, a plethora of work indicates the necessity of alleviating the catastrophic forgetting of PTMs. Through a pilot study and a causal analysis of CIL, we reveal that the crux lies in the imbalanced causal effects between new and old data. Specifically, the new data encourage models to adapt to new classes while hindering the adaptation of old classes. Similarly, the old data encourages models to adapt to old classes while hindering the adaptation of new classes. In other words, the adaptation process between new and old classes conflicts from the causal perspective. To alleviate this problem, we propose Balancing the Causal Effects (BaCE) in CIL. Concretely, BaCE proposes two objectives for building causal paths from both new and old data to the prediction of new and classes, respectively. In this way, the model is encouraged to adapt to all classes with causal effects from both new and old data and thus alleviates the causal imbalance problem. We conduct extensive experiments on continual image classification, continual text classification, and continual named entity recognition. Empirical results show that BaCE outperforms a series of CIL methods on different tasks and settings.
Multi-scale 2D Temporal Map Diffusion Models for Natural Language Video Localization
Jan 16, 2024Natural Language Video Localization (NLVL), grounding phrases from natural language descriptions to corresponding video segments, is a complex yet critical task in video understanding. Despite ongoing advancements, many existing solutions lack the capability to globally capture temporal dynamics of the video data. In this study, we present a novel approach to NLVL that aims to address this issue. Our method involves the direct generation of a global 2D temporal map via a conditional denoising diffusion process, based on the input video and language query. The main challenges are the inherent sparsity and discontinuity of a 2D temporal map in devising the diffusion decoder. To address these challenges, we introduce a multi-scale technique and develop an innovative diffusion decoder. Our approach effectively encapsulates the interaction between the query and video data across various time scales. Experiments on the Charades and DiDeMo datasets underscore the potency of our design.
Delving Deep into the Generalization of Vision Transformers under Distribution Shifts
Jun 18, 2021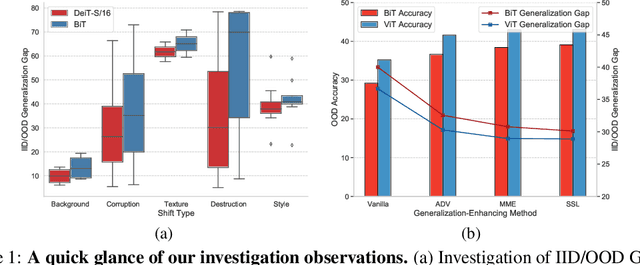
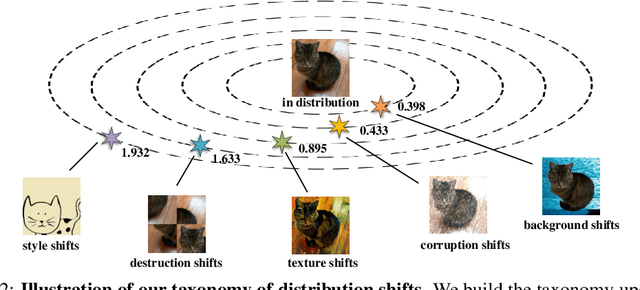

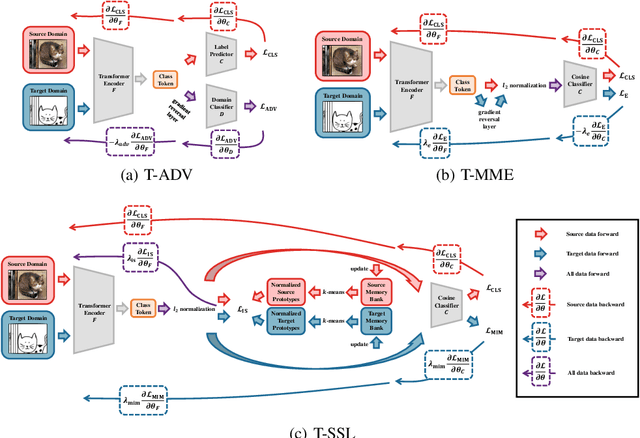
Recently, Vision Transformers (ViTs) have achieved impressive results on various vision tasks. Yet, their generalization ability under different distribution shifts is rarely understood. In this work, we provide a comprehensive study on the out-of-distribution generalization of ViTs. To support a systematic investigation, we first present a taxonomy of distribution shifts by categorizing them into five conceptual groups: corruption shift, background shift, texture shift, destruction shift, and style shift. Then we perform extensive evaluations of ViT variants under different groups of distribution shifts and compare their generalization ability with CNNs. Several important observations are obtained: 1) ViTs generalize better than CNNs under multiple distribution shifts. With the same or fewer parameters, ViTs are ahead of corresponding CNNs by more than 5% in top-1 accuracy under most distribution shifts. 2) Larger ViTs gradually narrow the in-distribution and out-of-distribution performance gap. To further improve the generalization of ViTs, we design the Generalization-Enhanced ViTs by integrating adversarial learning, information theory, and self-supervised learning. By investigating three types of generalization-enhanced ViTs, we observe their gradient-sensitivity and design a smoother learning strategy to achieve a stable training process. With modified training schemes, we achieve improvements on performance towards out-of-distribution data by 4% from vanilla ViTs. We comprehensively compare three generalization-enhanced ViTs with their corresponding CNNs, and observe that: 1) For the enhanced model, larger ViTs still benefit more for the out-of-distribution generalization. 2) generalization-enhanced ViTs are more sensitive to the hyper-parameters than corresponding CNNs. We hope our comprehensive study could shed light on the design of more generalizable learning architectures.
Towards Overcoming False Positives in Visual Relationship Detection
Dec 24, 2020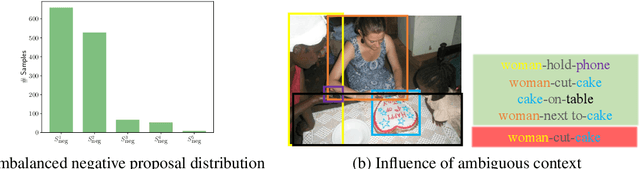
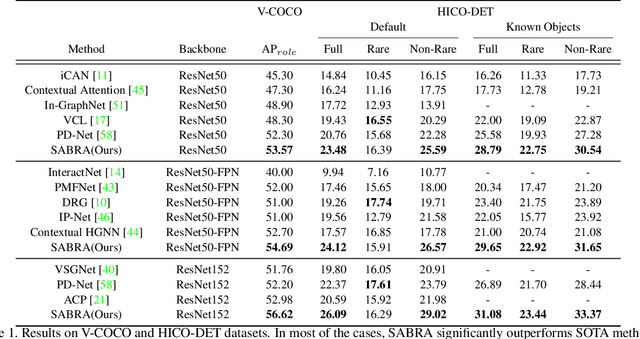
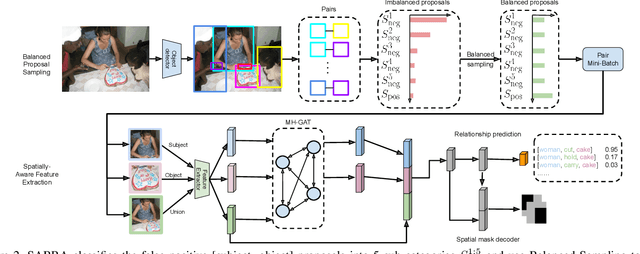
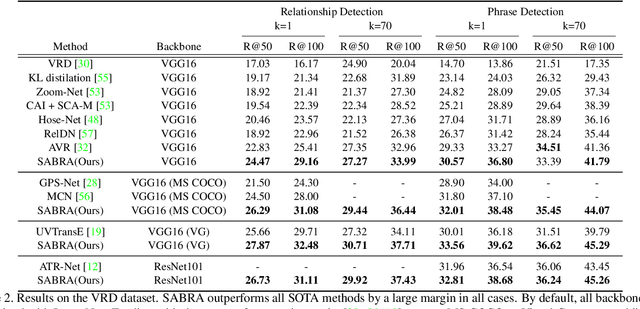
In this paper, we investigate the cause of the high false positive rate in Visual Relationship Detection (VRD). We observe that during training, the relationship proposal distribution is highly imbalanced: most of the negative relationship proposals are easy to identify, e.g., the inaccurate object detection, which leads to the under-fitting of low-frequency difficult proposals. This paper presents Spatially-Aware Balanced negative pRoposal sAmpling (SABRA), a robust VRD framework that alleviates the influence of false positives. To effectively optimize the model under imbalanced distribution, SABRA adopts Balanced Negative Proposal Sampling (BNPS) strategy for mini-batch sampling. BNPS divides proposals into 5 well defined sub-classes and generates a balanced training distribution according to the inverse frequency. BNPS gives an easier optimization landscape and significantly reduces the number of false positives. To further resolve the low-frequency challenging false positive proposals with high spatial ambiguity, we improve the spatial modeling ability of SABRA on two aspects: a simple and efficient multi-head heterogeneous graph attention network (MH-GAT) that models the global spatial interactions of objects, and a spatial mask decoder that learns the local spatial configuration. SABRA outperforms SOTA methods by a large margin on two human-object interaction (HOI) datasets and one general VRD dataset.