 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentMath: Empowering Mathematical Reasoning for Large Language Models via Tool-Augmented Agent
Dec 23, 2025Large Reasoning Models (LRMs) like o3 and DeepSeek-R1 have achieved remarkable progress in natural language reasoning with long chain-of-thought. However, they remain computationally inefficient and struggle with accuracy when solving problems requiring complex mathematical operations. In this work, we present AgentMath, an agent framework that seamlessly integrates language models' reasoning capabilities with code interpreters' computational precision to efficiently tackle complex mathematical problems. Our approach introduces three key innovations: (1) An automated method that converts natural language chain-of-thought into structured tool-augmented trajectories, generating high-quality supervised fine-tuning (SFT) data to alleviate data scarcity; (2) A novel agentic reinforcement learning (RL) paradigm that dynamically interleaves natural language generation with real-time code execution. This enables models to autonomously learn optimal tool-use strategies through multi-round interactive feedback, while fostering emergent capabilities in code refinement and error correction; (3) An efficient training system incorporating innovative techniques, including request-level asynchronous rollout scheduling, agentic partial rollout, and prefix-aware weighted load balancing, achieving 4-5x speedup and making efficient RL training feasible on ultra-long sequences with scenarios with massive tool calls.Extensive evaluations show that AgentMath achieves state-of-the-art performance on challenging mathematical competition benchmarks including AIME24, AIME25, and HMMT25. Specifically, AgentMath-30B-A3B attains 90.6%, 86.4%, and 73.8% accuracy respectively, achieving advanced capabilities.These results validate the effectiveness of our approach and pave the way for building more sophisticated and scalable mathematical reasoning agents.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
WarriorCoder: Learning from Expert Battles to Augment Code Large Language Models
Dec 23, 2024Despite recent progress achieved by code large language models (LLMs), their remarkable abilities are largely dependent on fine-tuning on the high-quality data, posing challenges for data collection and annotation. To address this, current methods often design various data flywheels to gather complex code instructions, enabling models to handle more intricate tasks. However, these approaches typically rely on off-the-shelf datasets and data augmentation from the limited pool of proprietary LLMs (e.g., Claude, GPT4, and so on), which limits the diversity of the constructed data and makes it prone to systemic biases. In this paper, we propose WarriorCoder which learns from expert battles to address these limitations. Specifically, we create an arena for current expert code LLMs, where each model challenges and responds to others' challenges, with evaluations conducted by uninvolved judge models. This competitive framework generates novel training data constructed from scratch, harnessing the strengths of all participants. Experimental results demonstrate that WarriorCoder achieves competitive performance compared to previous methods, even without relying on proprietary LLMs.
Self-Adaptive Reconstruction with Contrastive Learning for Unsupervised Sentence Embeddings
Feb 23, 2024
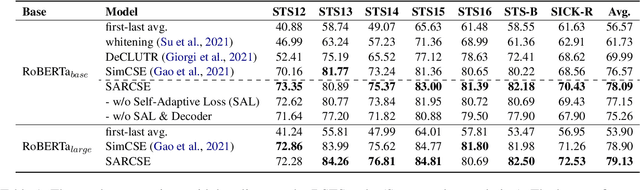
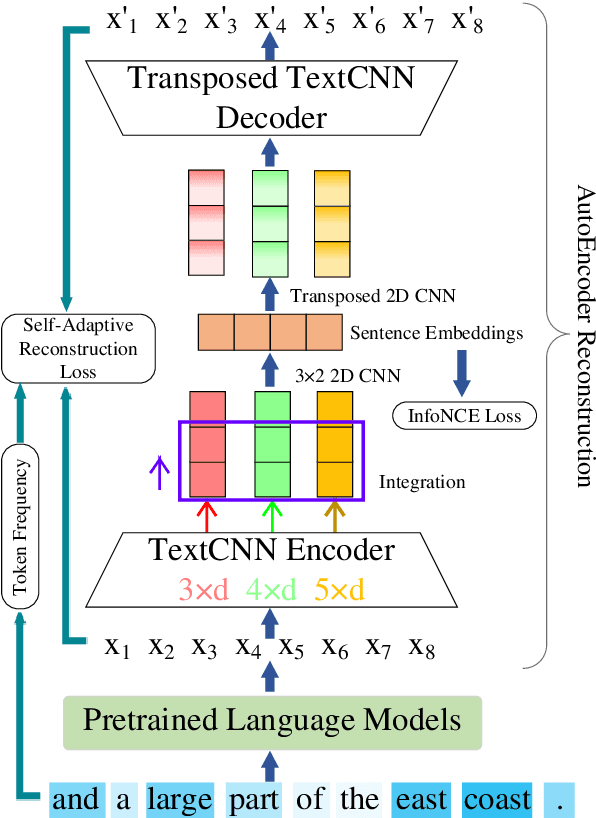
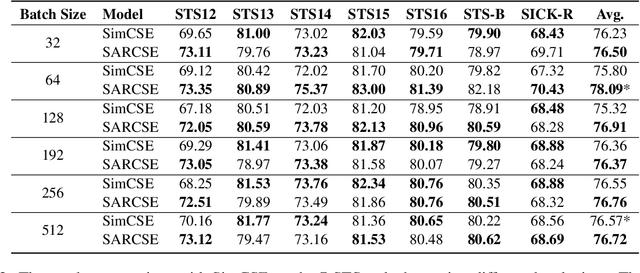
Unsupervised sentence embeddings task aims to convert sentences to semantic vector representations. Most previous works directly use the sentence representations derived from pretrained language models. However, due to the token bias in pretrained language models, the models can not capture the fine-grained semantics in sentences, which leads to poor predictions. To address this issue, we propose a novel Self-Adaptive Reconstruction Contrastive Sentence Embeddings (SARCSE) framework, which reconstructs all tokens in sentences with an AutoEncoder to help the model to preserve more fine-grained semantics during tokens aggregating. In addition, we proposed a self-adaptive reconstruction loss to alleviate the token bias towards frequency. Experimental results show that SARCSE gains significant improvements compared with the strong baseline SimCSE on the 7 STS tasks.
Balancing the Causal Effects in Class-Incremental Learning
Feb 15, 2024Class-Incremental Learning (CIL) is a practical and challenging problem for achieving general artificial intelligence. Recently, Pre-Trained Models (PTMs) have led to breakthroughs in both visual and natural language processing tasks. Despite recent studies showing PTMs' potential ability to learn sequentially, a plethora of work indicates the necessity of alleviating the catastrophic forgetting of PTMs. Through a pilot study and a causal analysis of CIL, we reveal that the crux lies in the imbalanced causal effects between new and old data. Specifically, the new data encourage models to adapt to new classes while hindering the adaptation of old classes. Similarly, the old data encourages models to adapt to old classes while hindering the adaptation of new classes. In other words, the adaptation process between new and old classes conflicts from the causal perspective. To alleviate this problem, we propose Balancing the Causal Effects (BaCE) in CIL. Concretely, BaCE proposes two objectives for building causal paths from both new and old data to the prediction of new and classes, respectively. In this way, the model is encouraged to adapt to all classes with causal effects from both new and old data and thus alleviates the causal imbalance problem. We conduct extensive experiments on continual image classification, continual text classification, and continual named entity recognition. Empirical results show that BaCE outperforms a series of CIL methods on different tasks and settings.
Beyond Anti-Forgetting: Multimodal Continual Instruction Tuning with Positive Forward Transfer
Jan 17, 2024Multimodal Continual Instruction Tuning (MCIT) enables Multimodal Large Language Models (MLLMs) to meet continuously emerging requirements without expensive retraining. MCIT faces two major obstacles: catastrophic forgetting (where old knowledge is forgotten) and negative forward transfer (where the performance of future tasks is degraded). Although existing methods have greatly alleviated catastrophic forgetting, they still suffer from negative forward transfer. By performing singular value decomposition (SVD) on input embeddings, we discover a large discrepancy in different input embeddings. The discrepancy results in the model learning irrelevant information for old and pre-trained tasks, which leads to catastrophic forgetting and negative forward transfer. To address these issues, we propose Fwd-Prompt, a prompt-based method projecting prompt gradient to the residual space to minimize the interference between tasks and to the pre-trained subspace for reusing pre-trained knowledge. Our experiments demonstrate that Fwd-Prompt achieves state-of-the-art performance while updating fewer parameters and requiring no old samples. Our research sheds light on the potential of continuously adapting MLLMs to new tasks under the instruction tuning paradigm and encourages future studies to explore MCIT. The code will soon be publicly available.
Improving Factual Consistency of Text Summarization by Adversarially Decoupling Comprehension and Embellishment Abilities of LLMs
Nov 01, 2023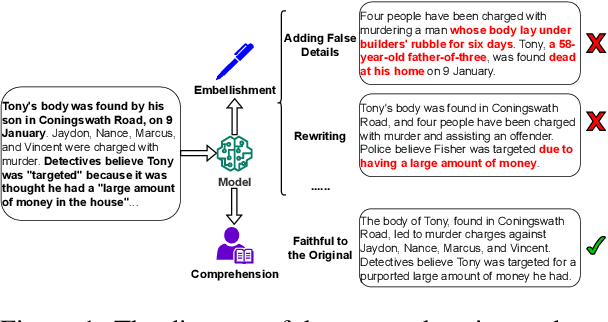
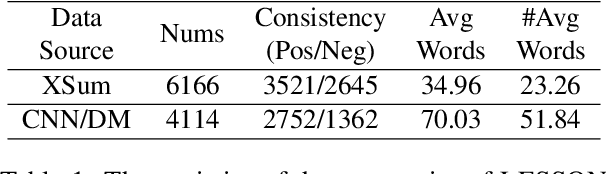
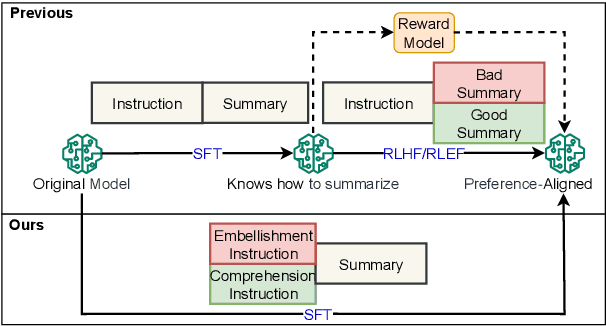
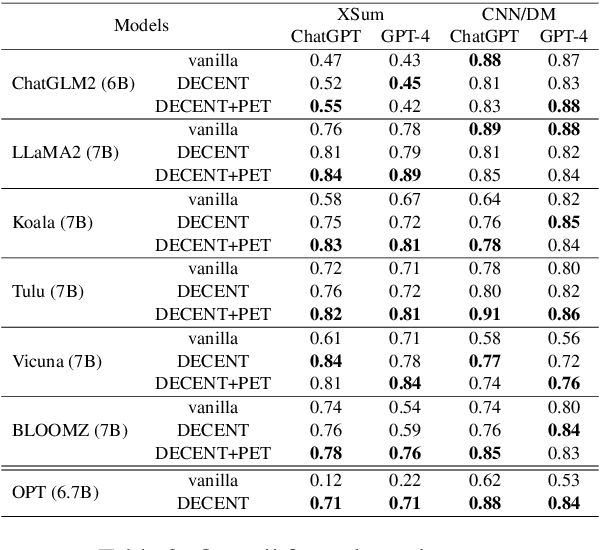
Despite the recent progress in text summarization made by large language models (LLMs), they often generate summaries that are factually inconsistent with original articles, known as "hallucinations" in text generation. Unlike previous small models (e.g., BART, T5), current LLMs make fewer silly mistakes but more sophisticated ones, such as imposing cause and effect, adding false details, and overgeneralizing, etc. These hallucinations are challenging to detect through traditional methods, which poses great challenges for improving the factual consistency of text summarization. In this paper, we propose an adversarially DEcoupling method to disentangle the Comprehension and EmbellishmeNT abilities of LLMs (DECENT). Furthermore, we adopt a probing-based parameter-efficient technique to cover the shortage of sensitivity for true and false in the training process of LLMs. In this way, LLMs are less confused about embellishing and understanding, thus can execute the instructions more accurately and have enhanced abilities to distinguish hallucinations. Experimental results show that DECENT significantly improves the reliability of text summarization based on LLMs.
Preserving Commonsense Knowledge from Pre-trained Language Models via Causal Inference
Jun 19, 2023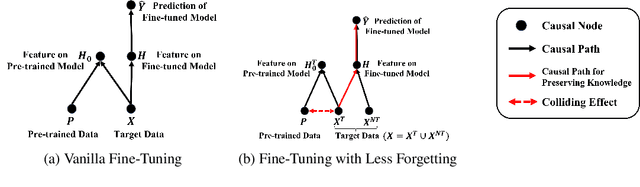
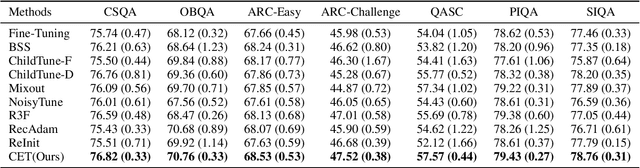
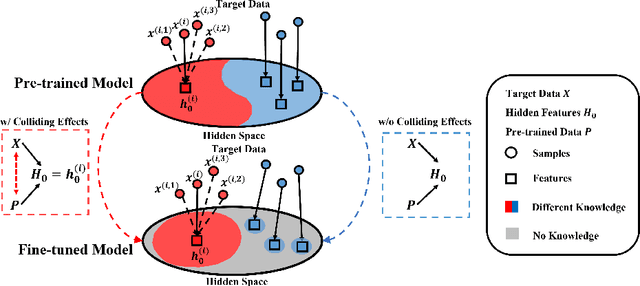
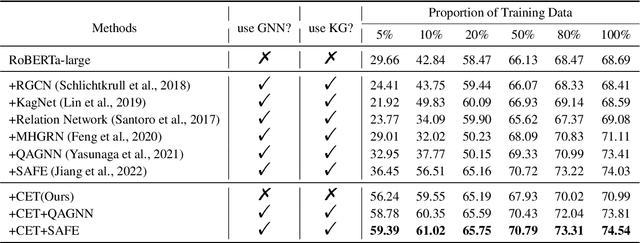
Fine-tuning has been proven to be a simple and effective technique to transfer the learned knowledge of Pre-trained Language Models (PLMs) to downstream tasks. However, vanilla fine-tuning easily overfits the target data and degrades the generalization ability. Most existing studies attribute it to catastrophic forgetting, and they retain the pre-trained knowledge indiscriminately without identifying what knowledge is transferable. Motivated by this, we frame fine-tuning into a causal graph and discover that the crux of catastrophic forgetting lies in the missing causal effects from the pretrained data. Based on the causal view, we propose a unified objective for fine-tuning to retrieve the causality back. Intriguingly, the unified objective can be seen as the sum of the vanilla fine-tuning objective, which learns new knowledge from target data, and the causal objective, which preserves old knowledge from PLMs. Therefore, our method is flexible and can mitigate negative transfer while preserving knowledge. Since endowing models with commonsense is a long-standing challenge, we implement our method on commonsense QA with a proposed heuristic estimation to verify its effectiveness. In the experiments, our method outperforms state-of-the-art fine-tuning methods on all six commonsense QA datasets and can be implemented as a plug-in module to inflate the performance of existing QA models.
Perturbation-based Self-supervised Attention for Attention Bias in Text Classification
May 25, 2023



In text classification, the traditional attention mechanisms usually focus too much on frequent words, and need extensive labeled data in order to learn. This paper proposes a perturbation-based self-supervised attention approach to guide attention learning without any annotation overhead. Specifically, we add as much noise as possible to all the words in the sentence without changing their semantics and predictions. We hypothesize that words that tolerate more noise are less significant, and we can use this information to refine the attention distribution. Experimental results on three text classification tasks show that our approach can significantly improve the performance of current attention-based models, and is more effective than existing self-supervised methods. We also provide a visualization analysis to verify the effectiveness of our approach.