 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalist Cross-Domain Molecular Learning Framework for Structure-Based Drug Discovery
Mar 06, 2025Structure-based drug discovery (SBDD) is a systematic scientific process that develops new drugs by leveraging the detailed physical structure of the target protein. Recent advancements in pre-trained models for biomolecules have demonstrated remarkable success across various biochemical applications, including drug discovery and protein engineering. However, in most approaches, the pre-trained models primarily focus on the characteristics of either small molecules or proteins, without delving into their binding interactions which are essential cross-domain relationships pivotal to SBDD. To fill this gap, we propose a general-purpose foundation model named BIT (an abbreviation for Biomolecular Interaction Transformer), which is capable of encoding a range of biochemical entities, including small molecules, proteins, and protein-ligand complexes, as well as various data formats, encompassing both 2D and 3D structures. Specifically, we introduce Mixture-of-Domain-Experts (MoDE) to handle the biomolecules from diverse biochemical domains and Mixture-of-Structure-Experts (MoSE) to capture positional dependencies in the molecular structures. The proposed mixture-of-experts approach enables BIT to achieve both deep fusion and domain-specific encoding, effectively capturing fine-grained molecular interactions within protein-ligand complexes. Then, we perform cross-domain pre-training on the shared Transformer backbone via several unified self-supervised denoising tasks. Experimental results on various benchmarks demonstrate that BIT achieves exceptional performance in downstream tasks, including binding affinity prediction, structure-based virtual screening, and molecular property prediction.
ListConRanker: A Contrastive Text Reranker with Listwise Encoding
Jan 13, 2025



Reranker models aim to re-rank the passages based on the semantics similarity between the given query and passages, which have recently received more attention due to the wide application of the Retrieval-Augmented Generation. Most previous methods apply pointwise encoding, meaning that it can only encode the context of the query for each passage input into the model. However, for the reranker model, given a query, the comparison results between passages are even more important, which is called listwise encoding. Besides, previous models are trained using the cross-entropy loss function, which leads to issues of unsmooth gradient changes during training and low training efficiency. To address these issues, we propose a novel Listwise-encoded Contrastive text reRanker (ListConRanker). It can help the passage to be compared with other passages during the encoding process, and enhance the contrastive information between positive examples and between positive and negative examples. At the same time, we use the circle loss to train the model to increase the flexibility of gradients and solve the problem of training efficiency. Experimental results show that ListConRanker achieves state-of-the-art performance on the reranking benchmark of Chinese Massive Text Embedding Benchmark, including the cMedQA1.0, cMedQA2.0, MMarcoReranking, and T2Reranking datasets.
A3S: A General Active Clustering Method with Pairwise Constraints
Jul 14, 2024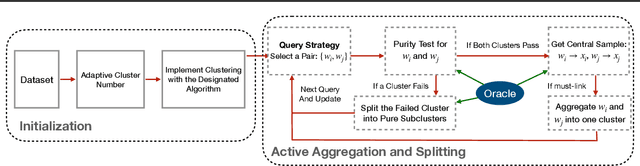

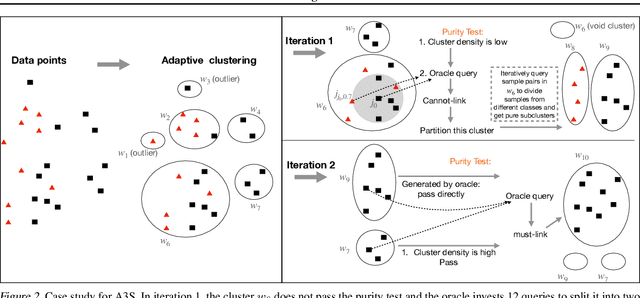
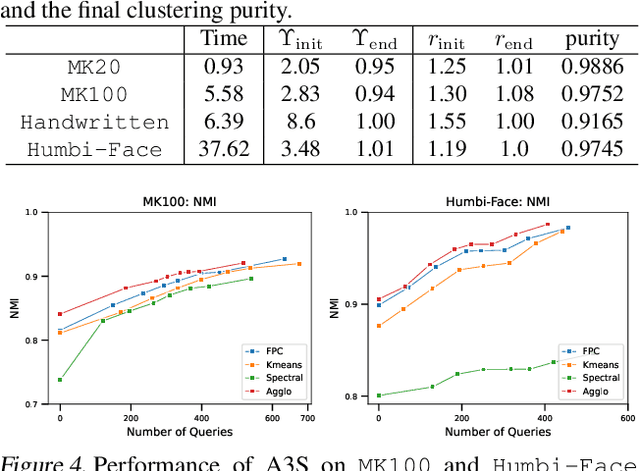
Active clustering aims to boost the clustering performance by integrating human-annotated pairwise constraints through strategic querying. Conventional approaches with semi-supervised clustering schemes encounter high query costs when applied to large datasets with numerous classes. To address these limitations, we propose a novel Adaptive Active Aggregation and Splitting (A3S) framework, falling within the cluster-adjustment scheme in active clustering. A3S features strategic active clustering adjustment on the initial cluster result, which is obtained by an adaptive clustering algorithm. In particular, our cluster adjustment is inspired by the quantitative analysis of Normalized mutual information gain under the information theory framework and can provably improve the clustering quality. The proposed A3S framework significantly elevates the performance and scalability of active clustering. In extensive experiments across diverse real-world datasets, A3S achieves desired results with significantly fewer human queries compared with existing methods.
Self-Adaptive Reconstruction with Contrastive Learning for Unsupervised Sentence Embeddings
Feb 23, 2024
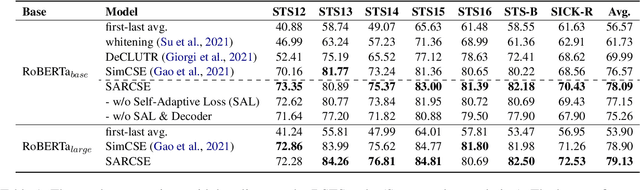
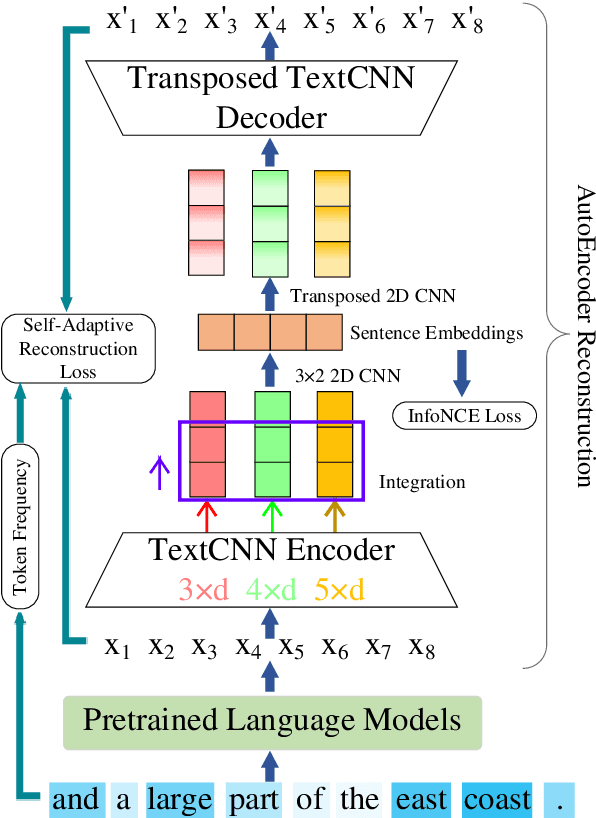
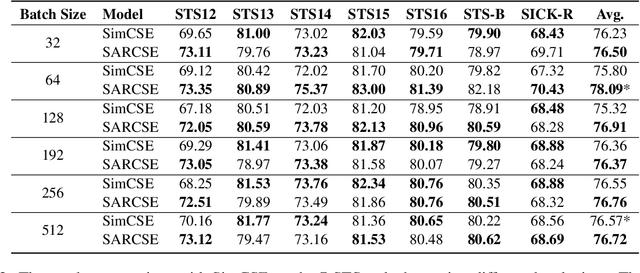
Unsupervised sentence embeddings task aims to convert sentences to semantic vector representations. Most previous works directly use the sentence representations derived from pretrained language models. However, due to the token bias in pretrained language models, the models can not capture the fine-grained semantics in sentences, which leads to poor predictions. To address this issue, we propose a novel Self-Adaptive Reconstruction Contrastive Sentence Embeddings (SARCSE) framework, which reconstructs all tokens in sentences with an AutoEncoder to help the model to preserve more fine-grained semantics during tokens aggregating. In addition, we proposed a self-adaptive reconstruction loss to alleviate the token bias towards frequency. Experimental results show that SARCSE gains significant improvements compared with the strong baseline SimCSE on the 7 STS tasks.
Preserving Commonsense Knowledge from Pre-trained Language Models via Causal Inference
Jun 19, 2023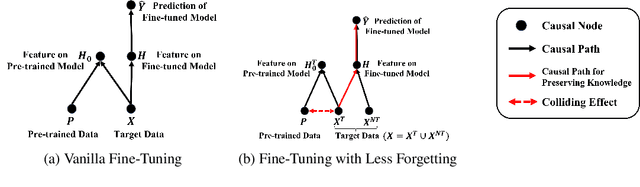
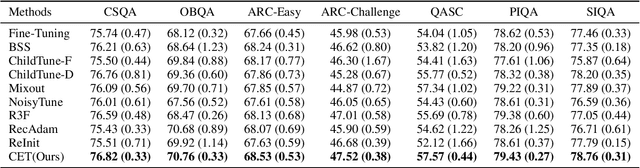
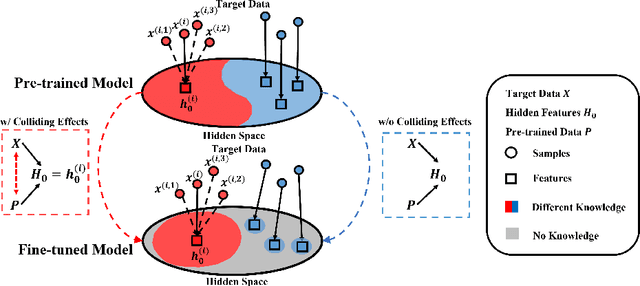
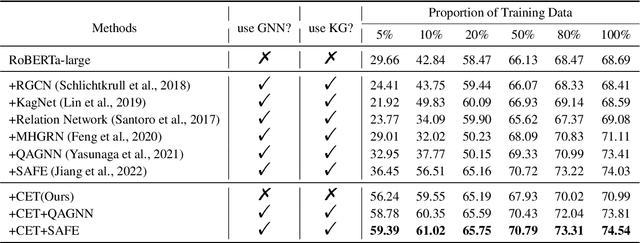
Fine-tuning has been proven to be a simple and effective technique to transfer the learned knowledge of Pre-trained Language Models (PLMs) to downstream tasks. However, vanilla fine-tuning easily overfits the target data and degrades the generalization ability. Most existing studies attribute it to catastrophic forgetting, and they retain the pre-trained knowledge indiscriminately without identifying what knowledge is transferable. Motivated by this, we frame fine-tuning into a causal graph and discover that the crux of catastrophic forgetting lies in the missing causal effects from the pretrained data. Based on the causal view, we propose a unified objective for fine-tuning to retrieve the causality back. Intriguingly, the unified objective can be seen as the sum of the vanilla fine-tuning objective, which learns new knowledge from target data, and the causal objective, which preserves old knowledge from PLMs. Therefore, our method is flexible and can mitigate negative transfer while preserving knowledge. Since endowing models with commonsense is a long-standing challenge, we implement our method on commonsense QA with a proposed heuristic estimation to verify its effectiveness. In the experiments, our method outperforms state-of-the-art fine-tuning methods on all six commonsense QA datasets and can be implemented as a plug-in module to inflate the performance of existing QA models.
Self-Learning Symmetric Multi-view Probabilistic Clustering
May 12, 2023



Multi-view Clustering (MVC) has achieved significant progress, with many efforts dedicated to learn knowledge from multiple views. However, most existing methods are either not applicable or require additional steps for incomplete multi-view clustering. Such a limitation results in poor-quality clustering performance and poor missing view adaptation. Besides, noise or outliers might significantly degrade the overall clustering performance, which are not handled well by most existing methods. Moreover, category information is required in most existing methods, which severely affects the clustering performance. In this paper, we propose a novel unified framework for incomplete and complete MVC named self-learning symmetric multi-view probabilistic clustering (SLS-MPC). SLS-MPC proposes a novel symmetric multi-view probability estimation and equivalently transforms multi-view pairwise posterior matching probability into composition of each view's individual distribution, which tolerates data missing and might extend to any number of views. Then, SLS-MPC proposes a novel self-learning probability function without any prior knowledge and hyper-parameters to learn each view's individual distribution from the aspect of consistency in single-view, cross-view and multi-view. Next, graph-context-aware refinement with path propagation and co-neighbor propagation is used to refine pairwise probability, which alleviates the impact of noise and outliers. Finally, SLS-MPC proposes a probabilistic clustering algorithm to adjust clustering assignments by maximizing the joint probability iteratively, in which category information is not required. Extensive experiments on multiple benchmarks for incomplete and complete MVC show that SLS-MPC significantly outperforms previous state-of-the-art methods.
Pair-Based Joint Encoding with Relational Graph Convolutional Networks for Emotion-Cause Pair Extraction
Dec 04, 2022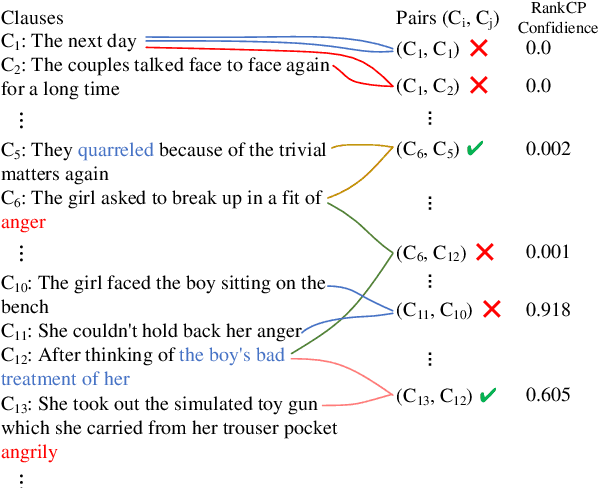
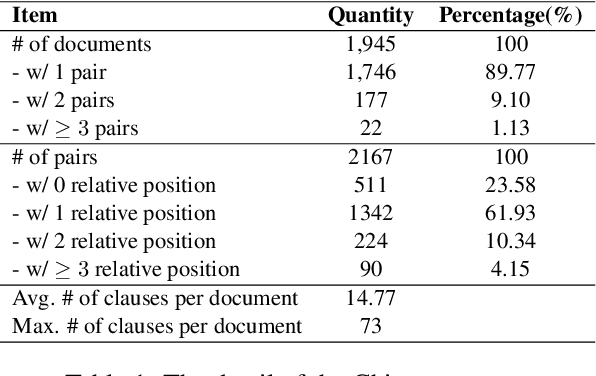
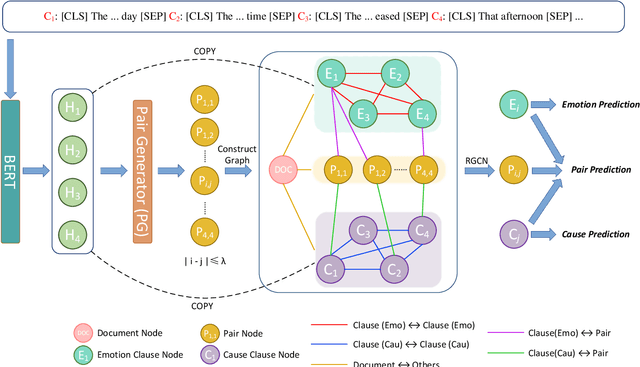
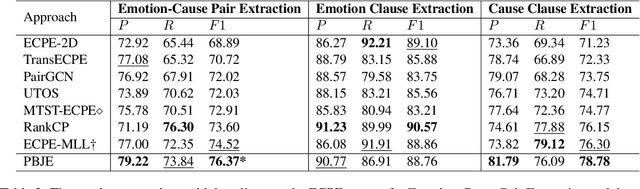
Emotion-cause pair extraction (ECPE) aims to extract emotion clauses and corresponding cause clauses, which have recently received growing attention. Previous methods sequentially encode features with a specified order. They first encode the emotion and cause features for clause extraction and then combine them for pair extraction. This lead to an imbalance in inter-task feature interaction where features extracted later have no direct contact with the former. To address this issue, we propose a novel Pair-Based Joint Encoding (PBJE) network, which generates pairs and clauses features simultaneously in a joint feature encoding manner to model the causal relationship in clauses. PBJE can balance the information flow among emotion clauses, cause clauses and pairs. From a multi-relational perspective, we construct a heterogeneous undirected graph and apply the Relational Graph Convolutional Network (RGCN) to capture the various relationship between clauses and the relationship between pairs and clauses. Experimental results show that PBJE achieves state-of-the-art performance on the Chinese benchmark corpus.
Dynamic Connected Neural Decision Classifier and Regressor with Dynamic Softing Pruning
Nov 20, 2019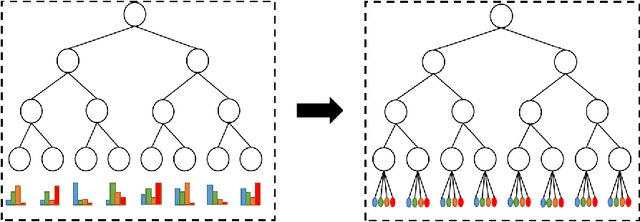
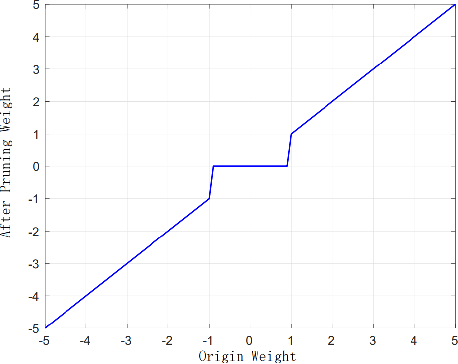
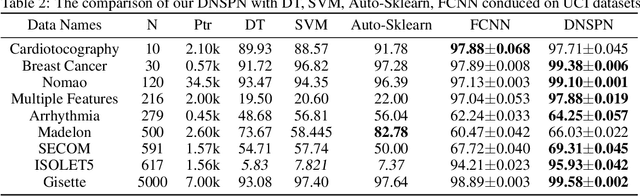
To deal with datasets of different complexity, this paper presents an efficient learning model that combines the proposed Dynamic Connected Neural Decision Networks (DNDN) and a new pruning method--Dynamic Soft Pruning (DSP). DNDN is a combination of random forests and deep neural networks thereby it enjoys both the properties of powerful classification capability and representation learning functionality. Different from Deep Neural Decision Forests (DNDF), this paper adopts an end-to-end training approach by representing the classification distribution with multiple randomly initialized softmax layers, which enables the placement of the forest trees after each layer in the neural network and greatly improves the training speed and stability. Furthermore, DSP is proposed to reduce the redundant connections of the network in a soft fashion which has high flexibility but demonstrates no performance loss compared with previous approaches. Extensive experiments on different datasets demonstrate the superiority of the proposed model over other popular algorithms in solving classification tasks.
Regression via Arbitrary Quantile Modeling
Nov 13, 2019
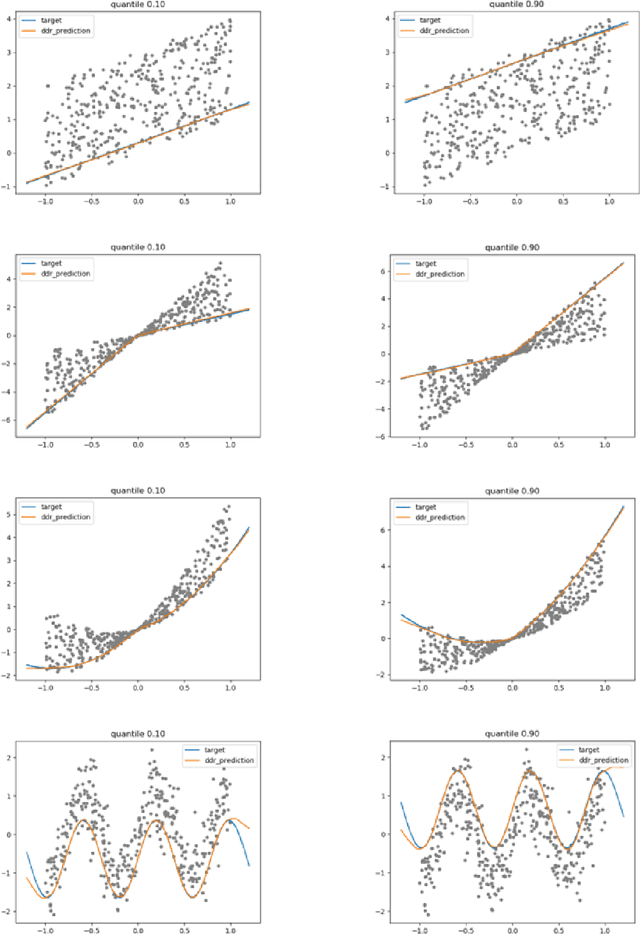

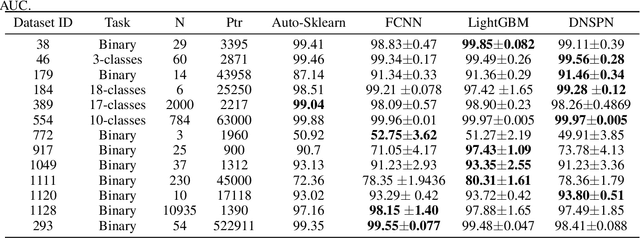
In the regression problem, L1 and L2 are the most commonly used loss functions, which produce mean predictions with different biases. However, the predictions are neither robust nor adequate enough since they only capture a few conditional distributions instead of the whole distribution, especially for small datasets. To address this problem, we proposed arbitrary quantile modeling to regulate the prediction, which achieved better performance compared to traditional loss functions. More specifically, a new distribution regression method, Deep Distribution Regression (DDR), is proposed to estimate arbitrary quantiles of the response variable. Our DDR method consists of two models: a Q model, which predicts the corresponding value for arbitrary quantile, and an F model, which predicts the corresponding quantile for arbitrary value. Furthermore, the duality between Q and F models enables us to design a novel loss function for joint training and perform a dual inference mechanism. Our experiments demonstrate that our DDR-joint and DDR-disjoint methods outperform previous methods such as AdaBoost, random forest, LightGBM, and neural networks both in terms of mean and quantile prediction.
Relief R-CNN : Utilizing Convolutional Features for Fast Object Detection
Apr 26, 2017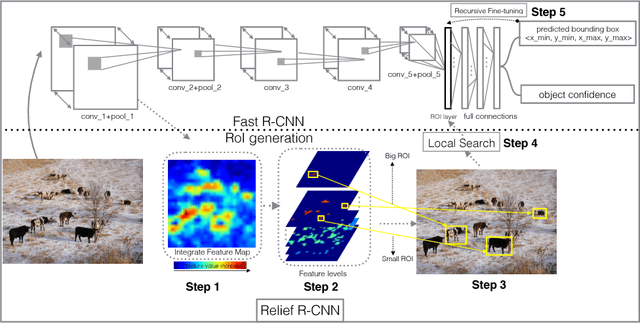
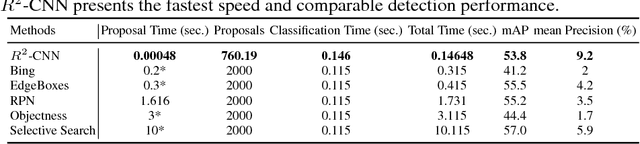
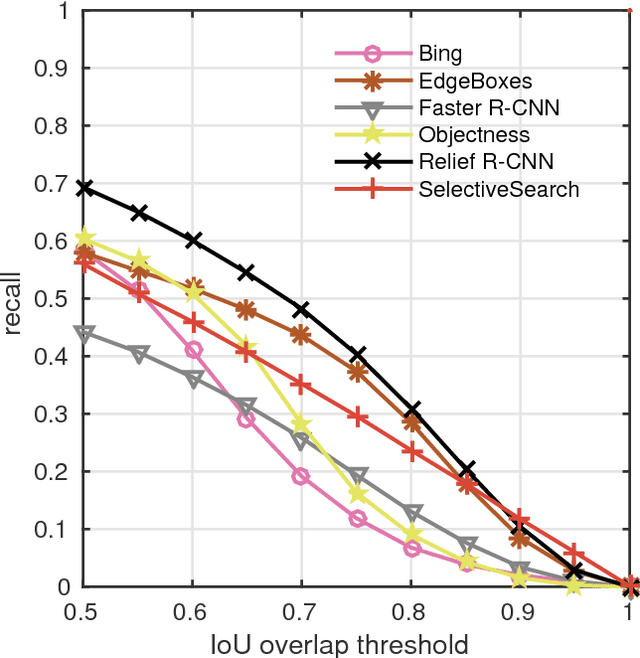
R-CNN style methods are sorts of the state-of-the-art object detection methods, which consist of region proposal generation and deep CNN classification. However, the proposal generation phase in this paradigm is usually time consuming, which would slow down the whole detection time in testing. This paper suggests that the value discrepancies among features in deep convolutional feature maps contain plenty of useful spatial information, and proposes a simple approach to extract the information for fast region proposal generation in testing. The proposed method, namely Relief R-CNN (R2-CNN), adopts a novel region proposal generator in a trained R-CNN style model. The new generator directly generates proposals from convolutional features by some simple rules, thus resulting in a much faster proposal generation speed and a lower demand of computation resources. Empirical studies show that R2-CNN could achieve the fastest detection speed with comparable accuracy among all the compared algorithms in testing.