 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssistant-Guided Mitigation of Teacher Preference Bias in LLM-as-a-Judge
May 25, 2025LLM-as-a-Judge employs large language models (LLMs), such as GPT-4, to evaluate the quality of LLM-generated responses, gaining popularity for its cost-effectiveness and strong alignment with human evaluations. However, training proxy judge models using evaluation data generated by powerful teacher models introduces a critical yet previously overlooked issue: teacher preference bias, where the proxy judge model learns a biased preference for responses from the teacher model. To tackle this problem, we propose a novel setting that incorporates an additional assistant model, which is not biased toward the teacher model's responses, to complement the training data. Building on this setup, we introduce AGDe-Judge, a three-stage framework designed to debias from both the labels and feedbacks in the training data. Extensive experiments demonstrate that AGDe-Judge effectively reduces teacher preference bias while maintaining strong performance across six evaluation benchmarks. Code is available at https://github.com/Liuz233/AGDe-Judge.
Less is More: Improving LLM Alignment via Preference Data Selection
Feb 22, 2025Direct Preference Optimization (DPO) has emerged as a promising approach for aligning large language models with human preferences. While prior work mainly extends DPO from the aspect of the objective function, we instead improve DPO from the largely overlooked but critical aspect of data selection. Specifically, we address the issue of parameter shrinkage caused by noisy data by proposing a novel margin-maximization principle for dataset curation in DPO training. To accurately estimate margins for data selection, we propose a dual-margin guided approach that considers both external reward margins and implicit DPO reward margins. Extensive experiments demonstrate that our method reduces computational cost dramatically while improving performance. Remarkably, by using just 10\% of the Ultrafeedback dataset, our approach achieves 3\% to 8\% improvements across various Llama and Mistral series models on the AlpacaEval 2.0 benchmark. Furthermore, our approach seamlessly extends to iterative DPO, yielding a roughly 3\% improvement with 25\% online data, while further reducing training time. These results highlight the potential of data selection strategies for advancing preference optimization.
A3S: A General Active Clustering Method with Pairwise Constraints
Jul 14, 2024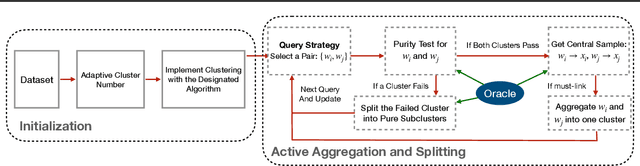

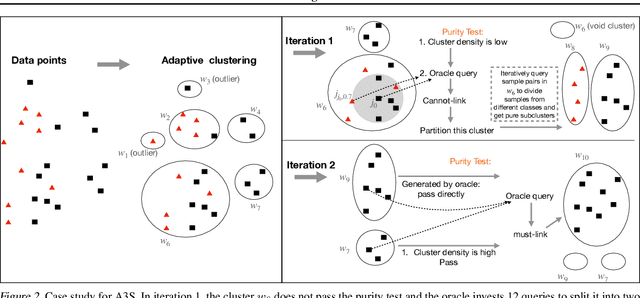
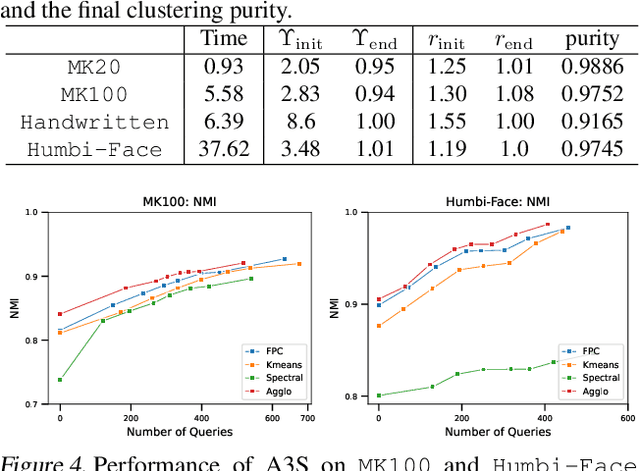
Active clustering aims to boost the clustering performance by integrating human-annotated pairwise constraints through strategic querying. Conventional approaches with semi-supervised clustering schemes encounter high query costs when applied to large datasets with numerous classes. To address these limitations, we propose a novel Adaptive Active Aggregation and Splitting (A3S) framework, falling within the cluster-adjustment scheme in active clustering. A3S features strategic active clustering adjustment on the initial cluster result, which is obtained by an adaptive clustering algorithm. In particular, our cluster adjustment is inspired by the quantitative analysis of Normalized mutual information gain under the information theory framework and can provably improve the clustering quality. The proposed A3S framework significantly elevates the performance and scalability of active clustering. In extensive experiments across diverse real-world datasets, A3S achieves desired results with significantly fewer human queries compared with existing methods.