 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Confounding to Learning: Dynamic Service Fee Pricing on Third-Party Platforms
Dec 28, 2025We study the pricing behavior of third-party platforms facing strategic agents. Assuming the platform is a revenue maximizer, it observes market features that generally affect demand. Since only the equilibrium price and quantity are observable, this presents a general demand learning problem under confounding. Mathematically, we develop an algorithm with optimal regret of $\Tilde{\cO}(\sqrt{T}\wedgeσ_S^{-2})$. Our results reveal that supply-side noise fundamentally affects the learnability of demand, leading to a phase transition in regret. Technically, we show that non-i.i.d. actions can serve as instrumental variables for learning demand. We also propose a novel homeomorphic construction that allows us to establish estimation bounds without assuming star-shapedness, providing the first efficiency guarantee for learning demand with deep neural networks. Finally, we demonstrate the practical applicability of our approach through simulations and real-world data from Zomato and Lyft.
Beyond Majority Voting: LLM Aggregation by Leveraging Higher-Order Information
Oct 01, 2025With the rapid progress of multi-agent large language model (LLM) reasoning, how to effectively aggregate answers from multiple LLMs has emerged as a fundamental challenge. Standard majority voting treats all answers equally, failing to consider latent heterogeneity and correlation across models. In this work, we design two new aggregation algorithms called Optimal Weight (OW) and Inverse Surprising Popularity (ISP), leveraging both first-order and second-order information. Our theoretical analysis shows these methods provably mitigate inherent limitations of majority voting under mild assumptions, leading to more reliable collective decisions. We empirically validate our algorithms on synthetic datasets, popular LLM fine-tuning benchmarks such as UltraFeedback and MMLU, and a real-world healthcare setting ARMMAN. Across all cases, our methods consistently outperform majority voting, offering both practical performance gains and conceptual insights for the design of robust multi-agent LLM pipelines.
The Sample Complexity of Online Strategic Decision Making with Information Asymmetry and Knowledge Transportability
Jun 11, 2025Information asymmetry is a pervasive feature of multi-agent systems, especially evident in economics and social sciences. In these settings, agents tailor their actions based on private information to maximize their rewards. These strategic behaviors often introduce complexities due to confounding variables. Simultaneously, knowledge transportability poses another significant challenge, arising from the difficulties of conducting experiments in target environments. It requires transferring knowledge from environments where empirical data is more readily available. Against these backdrops, this paper explores a fundamental question in online learning: Can we employ non-i.i.d. actions to learn about confounders even when requiring knowledge transfer? We present a sample-efficient algorithm designed to accurately identify system dynamics under information asymmetry and to navigate the challenges of knowledge transfer effectively in reinforcement learning, framed within an online strategic interaction model. Our method provably achieves learning of an $\epsilon$-optimal policy with a tight sample complexity of $O(1/\epsilon^2)$.
Less is More: Improving LLM Alignment via Preference Data Selection
Feb 22, 2025Direct Preference Optimization (DPO) has emerged as a promising approach for aligning large language models with human preferences. While prior work mainly extends DPO from the aspect of the objective function, we instead improve DPO from the largely overlooked but critical aspect of data selection. Specifically, we address the issue of parameter shrinkage caused by noisy data by proposing a novel margin-maximization principle for dataset curation in DPO training. To accurately estimate margins for data selection, we propose a dual-margin guided approach that considers both external reward margins and implicit DPO reward margins. Extensive experiments demonstrate that our method reduces computational cost dramatically while improving performance. Remarkably, by using just 10\% of the Ultrafeedback dataset, our approach achieves 3\% to 8\% improvements across various Llama and Mistral series models on the AlpacaEval 2.0 benchmark. Furthermore, our approach seamlessly extends to iterative DPO, yielding a roughly 3\% improvement with 25\% online data, while further reducing training time. These results highlight the potential of data selection strategies for advancing preference optimization.
Contextual Online Decision Making with Infinite-Dimensional Functional Regression
Jan 30, 2025
Contextual sequential decision-making problems play a crucial role in machine learning, encompassing a wide range of downstream applications such as bandits, sequential hypothesis testing and online risk control. These applications often require different statistical measures, including expectation, variance and quantiles. In this paper, we provide a universal admissible algorithm framework for dealing with all kinds of contextual online decision-making problems that directly learns the whole underlying unknown distribution instead of focusing on individual statistics. This is much more difficult because the dimension of the regression is uncountably infinite, and any existing linear contextual bandits algorithm will result in infinite regret. To overcome this issue, we propose an efficient infinite-dimensional functional regression oracle for contextual cumulative distribution functions (CDFs), where each data point is modeled as a combination of context-dependent CDF basis functions. Our analysis reveals that the decay rate of the eigenvalue sequence of the design integral operator governs the regression error rate and, consequently, the utility regret rate. Specifically, when the eigenvalue sequence exhibits a polynomial decay of order $\frac{1}{\gamma}\ge 1$, the utility regret is bounded by $\tilde{\mathcal{O}}\Big(T^{\frac{3\gamma+2}{2(\gamma+2)}}\Big)$. By setting $\gamma=0$, this recovers the existing optimal regret rate for contextual bandits with finite-dimensional regression and is optimal under a stronger exponential decay assumption. Additionally, we provide a numerical method to compute the eigenvalue sequence of the integral operator, enabling the practical implementation of our framework.
Diffusion-Based Planning for Autonomous Driving with Flexible Guidance
Jan 26, 2025



Achieving human-like driving behaviors in complex open-world environments is a critical challenge in autonomous driving. Contemporary learning-based planning approaches such as imitation learning methods often struggle to balance competing objectives and lack of safety assurance,due to limited adaptability and inadequacy in learning complex multi-modal behaviors commonly exhibited in human planning, not to mention their strong reliance on the fallback strategy with predefined rules. We propose a novel transformer-based Diffusion Planner for closed-loop planning, which can effectively model multi-modal driving behavior and ensure trajectory quality without any rule-based refinement. Our model supports joint modeling of both prediction and planning tasks under the same architecture, enabling cooperative behaviors between vehicles. Moreover, by learning the gradient of the trajectory score function and employing a flexible classifier guidance mechanism, Diffusion Planner effectively achieves safe and adaptable planning behaviors. Evaluations on the large-scale real-world autonomous planning benchmark nuPlan and our newly collected 200-hour delivery-vehicle driving dataset demonstrate that Diffusion Planner achieves state-of-the-art closed-loop performance with robust transferability in diverse driving styles.
An Instrumental Value for Data Production and its Application to Data Pricing
Dec 24, 2024How much value does a dataset or a data production process have to an agent who wishes to use the data to assist decision-making? This is a fundamental question towards understanding the value of data as well as further pricing of data. This paper develops an approach for capturing the instrumental value of data production processes, which takes two key factors into account: (a) the context of the agent's decision-making problem; (b) prior data or information the agent already possesses. We ''micro-found'' our valuation concepts by showing how they connect to classic notions of information design and signals in information economics. When instantiated in the domain of Bayesian linear regression, our value naturally corresponds to information gain. Based on our designed data value, we then study a basic monopoly pricing setting with a buyer looking to purchase from a seller some labeled data of a certain feature direction in order to improve a Bayesian regression model. We show that when the seller has the ability to fully customize any data request, she can extract the first-best revenue (i.e., full surplus) from any population of buyers, i.e., achieving first-degree price discrimination. If the seller can only sell data that are derived from an existing data pool, this limits her ability to customize, and achieving first-best revenue becomes generally impossible. However, we design a mechanism that achieves seller revenue at most $\log (\kappa)$ less than the first-best revenue, where $\kappa$ is the condition number associated with the data matrix. A corollary of this result is that the seller can extract the first-best revenue in the multi-armed bandits special case.
PRISM: PRogressive dependency maxImization for Scale-invariant image Matching
Aug 07, 2024

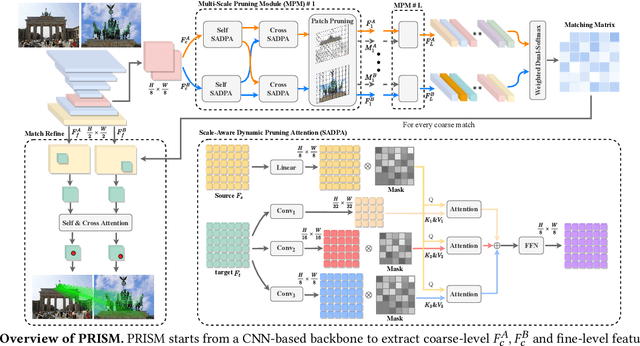

Image matching aims at identifying corresponding points between a pair of images. Currently, detector-free methods have shown impressive performance in challenging scenarios, thanks to their capability of generating dense matches and global receptive field. However, performing feature interaction and proposing matches across the entire image is unnecessary, because not all image regions contribute to the matching process. Interacting and matching in unmatchable areas can introduce errors, reducing matching accuracy and efficiency. Meanwhile, the scale discrepancy issue still troubles existing methods. To address above issues, we propose PRogressive dependency maxImization for Scale-invariant image Matching (PRISM), which jointly prunes irrelevant patch features and tackles the scale discrepancy. To do this, we firstly present a Multi-scale Pruning Module (MPM) to adaptively prune irrelevant features by maximizing the dependency between the two feature sets. Moreover, we design the Scale-Aware Dynamic Pruning Attention (SADPA) to aggregate information from different scales via a hierarchical design. Our method's superior matching performance and generalization capability are confirmed by leading accuracy across various evaluation benchmarks and downstream tasks. The code is publicly available at https://github.com/Master-cai/PRISM.
BEVPlace++: Fast, Robust, and Lightweight LiDAR Global Localization for Unmanned Ground Vehicles
Aug 03, 2024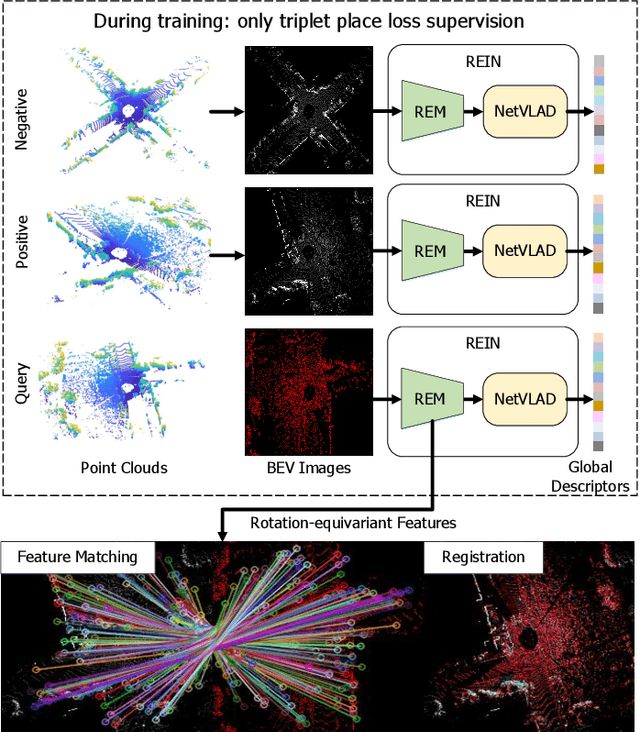
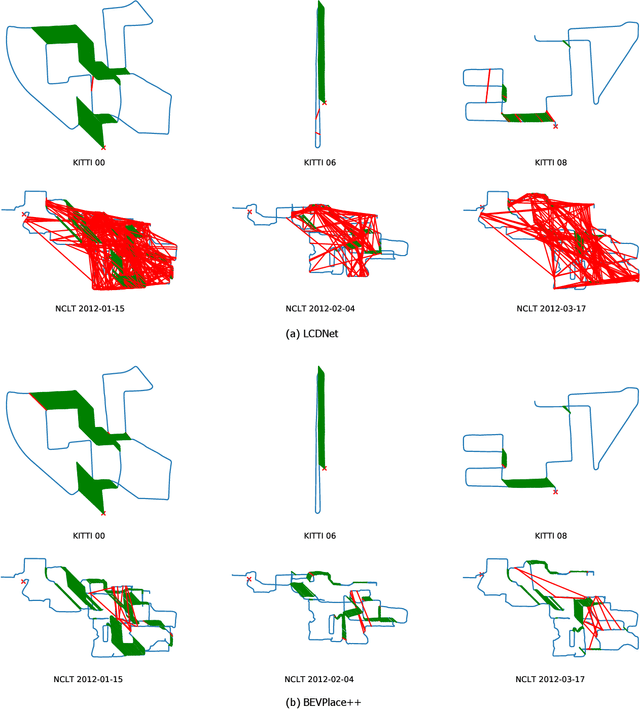
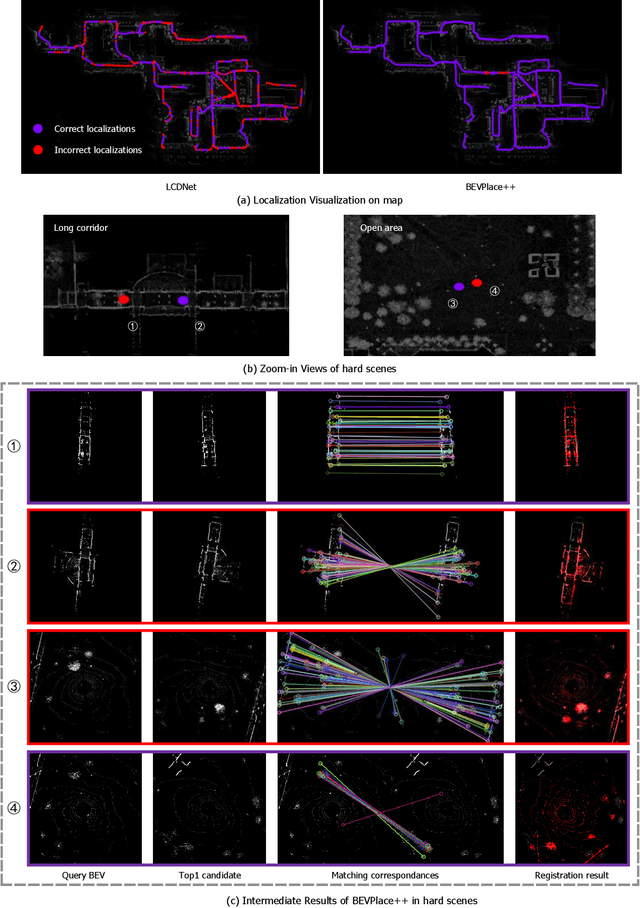
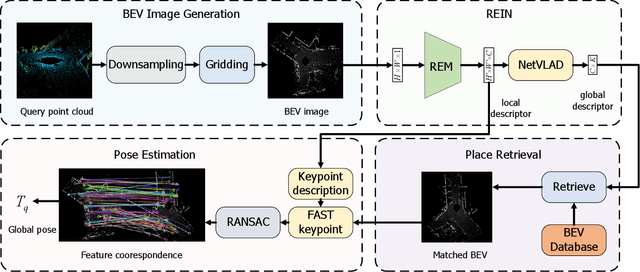
This article introduces BEVPlace++, a novel, fast, and robust LiDAR global localization method for unmanned ground vehicles. It uses lightweight convolutional neural networks (CNNs) on Bird's Eye View (BEV) image-like representations of LiDAR data to achieve accurate global localization through place recognition followed by 3-DoF pose estimation. Our detailed analyses reveal an interesting fact that CNNs are inherently effective at extracting distinctive features from LiDAR BEV images. Remarkably, keypoints of two BEV images with large translations can be effectively matched using CNN-extracted features. Building on this insight, we design a rotation equivariant module (REM) to obtain distinctive features while enhancing robustness to rotational changes. A Rotation Equivariant and Invariant Network (REIN) is then developed by cascading REM and a descriptor generator, NetVLAD, to sequentially generate rotation equivariant local features and rotation invariant global descriptors. The global descriptors are used first to achieve robust place recognition, and the local features are used for accurate pose estimation. Experimental results on multiple public datasets demonstrate that BEVPlace++, even when trained on a small dataset (3000 frames of KITTI) only with place labels, generalizes well to unseen environments, performs consistently across different days and years, and adapts to various types of LiDAR scanners. BEVPlace++ achieves state-of-the-art performance in subtasks of global localization including place recognition, loop closure detection, and global localization. Additionally, BEVPlace++ is lightweight, runs in real-time, and does not require accurate pose supervision, making it highly convenient for deployment. The source codes are publicly available at \href{https://github.com/zjuluolun/BEVPlace}{https://github.com/zjuluolun/BEVPlace}.
S4TP: Social-Suitable and Safety-Sensitive Trajectory Planning for Autonomous Vehicles
Apr 18, 2024



In public roads, autonomous vehicles (AVs) face the challenge of frequent interactions with human-driven vehicles (HDVs), which render uncertain driving behavior due to varying social characteristics among humans. To effectively assess the risks prevailing in the vicinity of AVs in social interactive traffic scenarios and achieve safe autonomous driving, this article proposes a social-suitable and safety-sensitive trajectory planning (S4TP) framework. Specifically, S4TP integrates the Social-Aware Trajectory Prediction (SATP) and Social-Aware Driving Risk Field (SADRF) modules. SATP utilizes Transformers to effectively encode the driving scene and incorporates an AV's planned trajectory during the prediction decoding process. SADRF assesses the expected surrounding risk degrees during AVs-HDVs interactions, each with different social characteristics, visualized as two-dimensional heat maps centered on the AV. SADRF models the driving intentions of the surrounding HDVs and predicts trajectories based on the representation of vehicular interactions. S4TP employs an optimization-based approach for motion planning, utilizing the predicted HDVs'trajectories as input. With the integration of SADRF, S4TP executes real-time online optimization of the planned trajectory of AV within lowrisk regions, thus improving the safety and the interpretability of the planned trajectory. We have conducted comprehensive tests of the proposed method using the SMARTS simulator. Experimental results in complex social scenarios, such as unprotected left turn intersections, merging, cruising, and overtaking, validate the superiority of our proposed S4TP in terms of safety and rationality. S4TP achieves a pass rate of 100% across all scenarios, surpassing the current state-of-the-art methods Fanta of 98.25% and Predictive-Decision of 94.75%.