 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Future Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Dec 09, 2025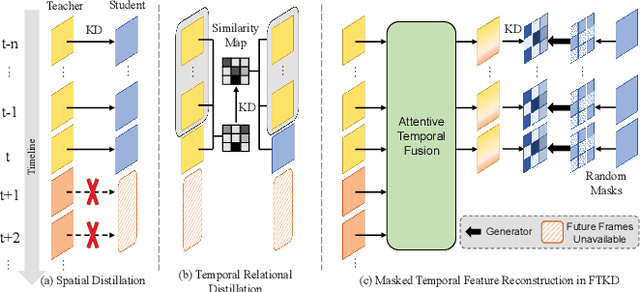
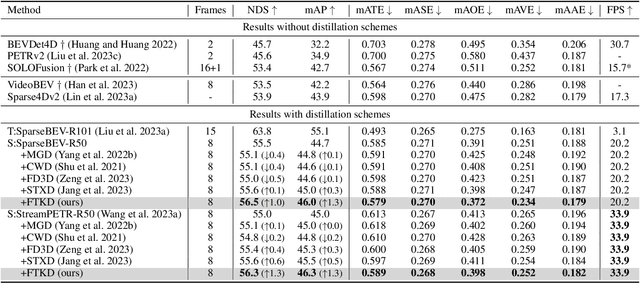
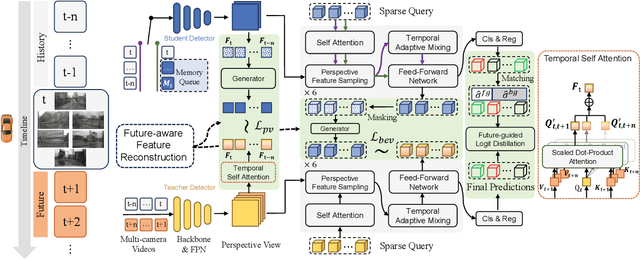
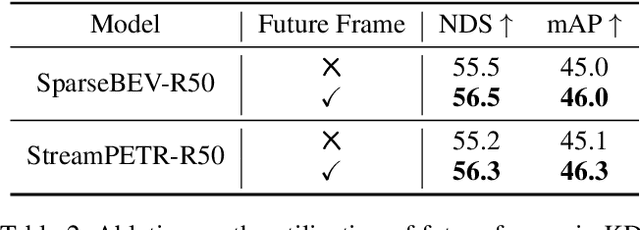
Camera-based temporal 3D object detection has shown impressive results in autonomous driving, with offline models improving accuracy by using future frames. Knowledge distillation (KD) can be an appealing framework for transferring rich information from offline models to online models. However, existing KD methods overlook future frames, as they mainly focus on spatial feature distillation under strict frame alignment or on temporal relational distillation, thereby making it challenging for online models to effectively learn future knowledge. To this end, we propose a sparse query-based approach, Future Temporal Knowledge Distillation (FTKD), which effectively transfers future frame knowledge from an offline teacher model to an online student model. Specifically, we present a future-aware feature reconstruction strategy to encourage the student model to capture future features without strict frame alignment. In addition, we further introduce future-guided logit distillation to leverage the teacher's stable foreground and background context. FTKD is applied to two high-performing 3D object detection baselines, achieving up to 1.3 mAP and 1.3 NDS gains on the nuScenes dataset, as well as the most accurate velocity estimation, without increasing inference cost.
Predictor-Based Time Delay Control of A Hex-Jet Unmanned Aerial Vehicle
Mar 12, 2025Turbojet-powered VTOL UAVs have garnered increased attention in heavy-load transport and emergency services, due to their superior power density and thrust-to-weight ratio compared to existing electronic propulsion systems. The main challenge with jet-powered UAVs lies in the complexity of thrust vectoring mechanical systems, which aim to mitigate the slow dynamics of the turbojet. In this letter, we introduce a novel turbojet-powered UAV platform named Hex-Jet. Our concept integrates thrust vectoring and differential thrust for comprehensive attitude control. This approach notably simplifies the thrust vectoring mechanism. We utilize a predictor-based time delay control method based on the frequency domain model in our Hex-Jet controller design to mitigate the delay in roll attitude control caused by turbojet dynamics. Our comparative studies provide valuable insights for the UAV community, and flight tests on the scaled prototype demonstrate the successful implementation and verification of the proposed predictor-based time delay control technique.
SSEditor: Controllable Mask-to-Scene Generation with Diffusion Model
Nov 19, 2024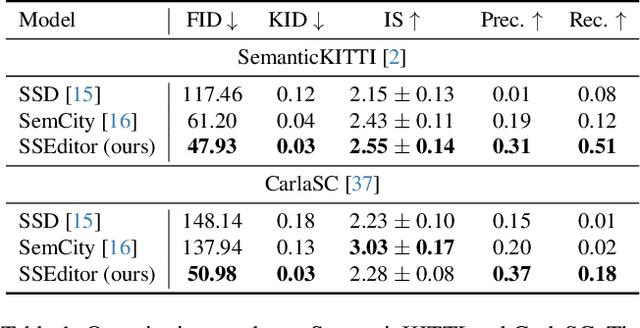
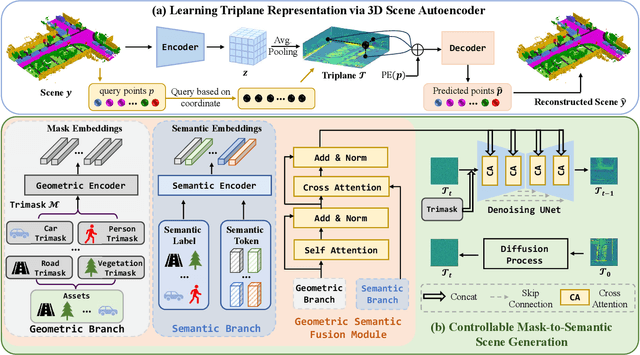

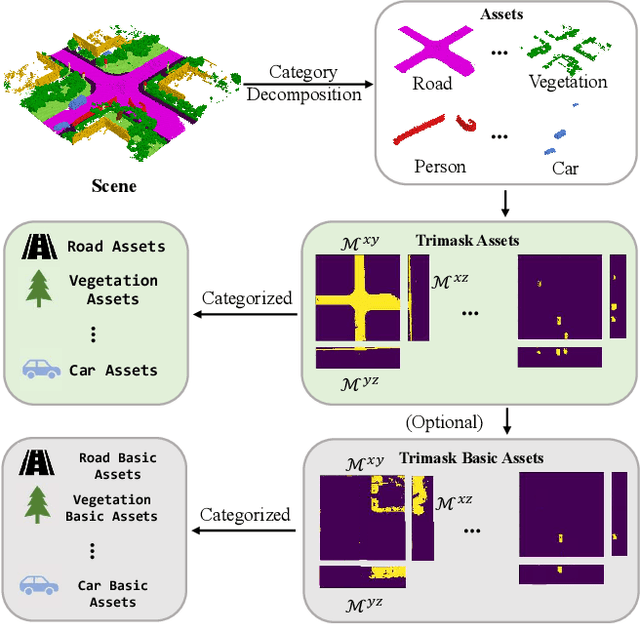
Recent advancements in 3D diffusion-based semantic scene generation have gained attention. However, existing methods rely on unconditional generation and require multiple resampling steps when editing scenes, which significantly limits their controllability and flexibility. To this end, we propose SSEditor, a controllable Semantic Scene Editor that can generate specified target categories without multiple-step resampling. SSEditor employs a two-stage diffusion-based framework: (1) a 3D scene autoencoder is trained to obtain latent triplane features, and (2) a mask-conditional diffusion model is trained for customizable 3D semantic scene generation. In the second stage, we introduce a geometric-semantic fusion module that enhance the model's ability to learn geometric and semantic information. This ensures that objects are generated with correct positions, sizes, and categories. Extensive experiments on SemanticKITTI and CarlaSC demonstrate that SSEditor outperforms previous approaches in terms of controllability and flexibility in target generation, as well as the quality of semantic scene generation and reconstruction. More importantly, experiments on the unseen Occ-3D Waymo dataset show that SSEditor is capable of generating novel urban scenes, enabling the rapid construction of 3D scenes.
Distilling Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Jan 08, 2024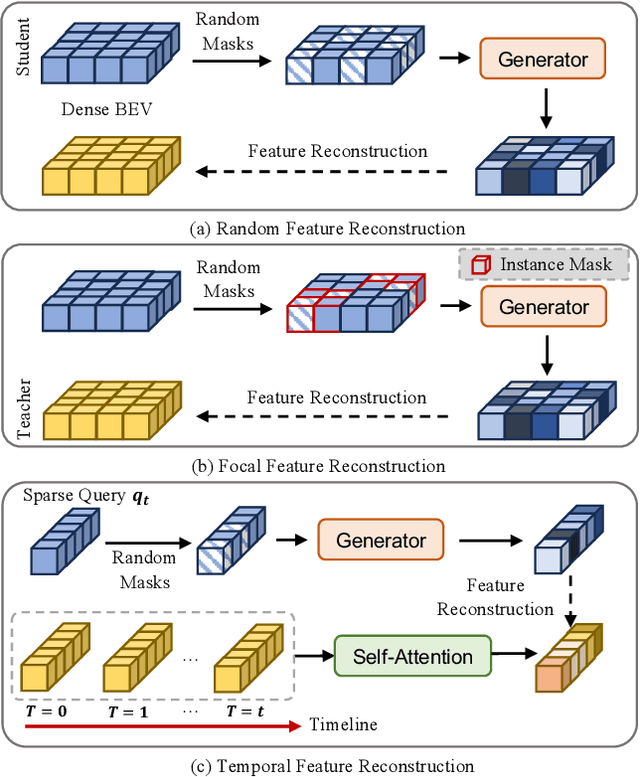
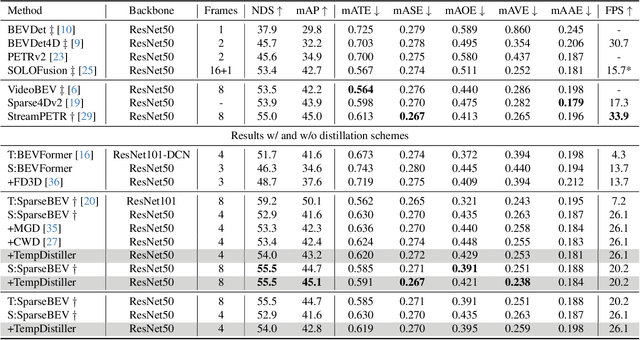
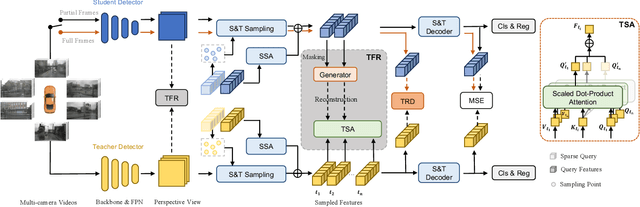
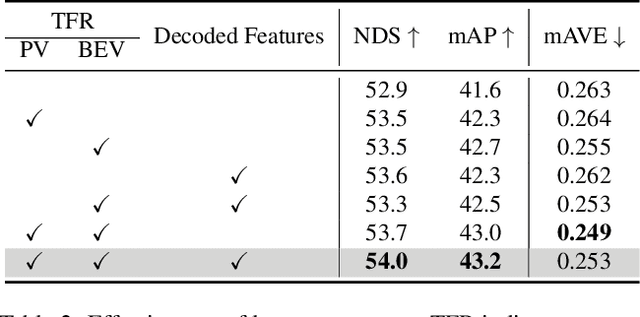
Striking a balance between precision and efficiency presents a prominent challenge in the bird's-eye-view (BEV) 3D object detection. Although previous camera-based BEV methods achieved remarkable performance by incorporating long-term temporal information, most of them still face the problem of low efficiency. One potential solution is knowledge distillation. Existing distillation methods only focus on reconstructing spatial features, while overlooking temporal knowledge. To this end, we propose TempDistiller, a Temporal knowledge Distiller, to acquire long-term memory from a teacher detector when provided with a limited number of frames. Specifically, a reconstruction target is formulated by integrating long-term temporal knowledge through self-attention operation applied to feature teachers. Subsequently, novel features are generated for masked student features via a generator. Ultimately, we utilize this reconstruction target to reconstruct the student features. In addition, we also explore temporal relational knowledge when inputting full frames for the student model. We verify the effectiveness of the proposed method on the nuScenes benchmark. The experimental results show our method obtain an enhancement of +1.6 mAP and +1.1 NDS compared to the baseline, a speed improvement of approximately 6 FPS after compressing temporal knowledge, and the most accurate velocity estimation.