 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving Averaging: Personalized Lip-Sync Driven Characters Based on Identity Adapter
Mar 09, 2025



Recent advances in diffusion-based lip-syncing generative models have demonstrated their ability to produce highly synchronized talking face videos for visual dubbing. Although these models excel at lip synchronization, they often struggle to maintain fine-grained control over facial details in generated images. In this work, we identify "lip averaging" phenomenon where the model fails to preserve subtle facial details when dubbing unseen in-the-wild videos. This issue arises because the commonly used UNet backbone primarily integrates audio features into visual representations in the latent space via cross-attention mechanisms and multi-scale fusion, but it struggles to retain fine-grained lip details in the generated faces. To address this issue, we propose UnAvgLip, which extracts identity embeddings from reference videos to generate highly faithful facial sequences while maintaining accurate lip synchronization. Specifically, our method comprises two primary components: (1) an Identity Perceiver module that encodes facial embeddings to align with conditioned audio features; and (2) an ID-CrossAttn module that injects facial embeddings into the generation process, enhancing model's capability of identity retention. Extensive experiments demonstrate that, at a modest training and inference cost, UnAvgLip effectively mitigates the "averaging" phenomenon in lip inpainting, significantly preserving unique facial characteristics while maintaining precise lip synchronization. Compared with the original approach, our method demonstrates significant improvements of 5% on the identity consistency metric and 2% on the SSIM metric across two benchmark datasets (HDTF and LRW).
A Regularized Newton Method for Nonconvex Optimization with Global and Local Complexity Guarantees
Feb 07, 2025
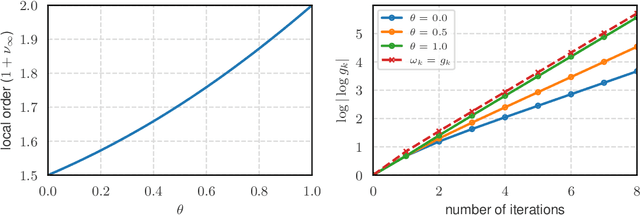
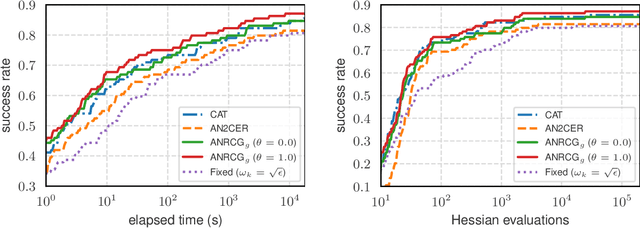
We consider the problem of finding an $\epsilon$-stationary point of a nonconvex function with a Lipschitz continuous Hessian and propose a quadratic regularized Newton method incorporating a new class of regularizers constructed from the current and previous gradients. The method leverages a recently developed linear conjugate gradient approach with a negative curvature monitor to solve the regularized Newton equation. Notably, our algorithm is adaptive, requiring no prior knowledge of the Lipschitz constant of the Hessian, and achieves a global complexity of $O(\epsilon^{-\frac{3}{2}}) + \tilde O(1)$ in terms of the second-order oracle calls, and $\tilde O(\epsilon^{-\frac{7}{4}})$ for Hessian-vector products, respectively. Moreover, when the iterates converge to a point where the Hessian is positive definite, the method exhibits quadratic local convergence. Preliminary numerical results illustrate the competitiveness of our algorithm.
Dust to Tower: Coarse-to-Fine Photo-Realistic Scene Reconstruction from Sparse Uncalibrated Images
Dec 27, 2024



Photo-realistic scene reconstruction from sparse-view, uncalibrated images is highly required in practice. Although some successes have been made, existing methods are either Sparse-View but require accurate camera parameters (i.e., intrinsic and extrinsic), or SfM-free but need densely captured images. To combine the advantages of both methods while addressing their respective weaknesses, we propose Dust to Tower (D2T), an accurate and efficient coarse-to-fine framework to optimize 3DGS and image poses simultaneously from sparse and uncalibrated images. Our key idea is to first construct a coarse model efficiently and subsequently refine it using warped and inpainted images at novel viewpoints. To do this, we first introduce a Coarse Construction Module (CCM) which exploits a fast Multi-View Stereo model to initialize a 3D Gaussian Splatting (3DGS) and recover initial camera poses. To refine the 3D model at novel viewpoints, we propose a Confidence Aware Depth Alignment (CADA) module to refine the coarse depth maps by aligning their confident parts with estimated depths by a Mono-depth model. Then, a Warped Image-Guided Inpainting (WIGI) module is proposed to warp the training images to novel viewpoints by the refined depth maps, and inpainting is applied to fulfill the ``holes" in the warped images caused by view-direction changes, providing high-quality supervision to further optimize the 3D model and the camera poses. Extensive experiments and ablation studies demonstrate the validity of D2T and its design choices, achieving state-of-the-art performance in both tasks of novel view synthesis and pose estimation while keeping high efficiency. Codes will be publicly available.
Spatiotemporal Decoupling for Efficient Vision-Based Occupancy Forecasting
Nov 21, 2024



The task of occupancy forecasting (OCF) involves utilizing past and present perception data to predict future occupancy states of autonomous vehicle surrounding environments, which is critical for downstream tasks such as obstacle avoidance and path planning. Existing 3D OCF approaches struggle to predict plausible spatial details for movable objects and suffer from slow inference speeds due to neglecting the bias and uneven distribution of changing occupancy states in both space and time. In this paper, we propose a novel spatiotemporal decoupling vision-based paradigm to explicitly tackle the bias and achieve both effective and efficient 3D OCF. To tackle spatial bias in empty areas, we introduce a novel spatial representation that decouples the conventional dense 3D format into 2D bird's-eye view (BEV) occupancy with corresponding height values, enabling 3D OCF derived only from 2D predictions thus enhancing efficiency. To reduce temporal bias on static voxels, we design temporal decoupling to improve end-to-end OCF by temporally associating instances via predicted flows. We develop an efficient multi-head network EfficientOCF to achieve 3D OCF with our devised spatiotemporally decoupled representation. A new metric, conditional IoU (C-IoU), is also introduced to provide a robust 3D OCF performance assessment, especially in datasets with missing or incomplete annotations. The experimental results demonstrate that EfficientOCF surpasses existing baseline methods on accuracy and efficiency, achieving state-of-the-art performance with a fast inference time of 82.33ms with a single GPU. Our code will be released as open source.
PRISM: PRogressive dependency maxImization for Scale-invariant image Matching
Aug 07, 2024

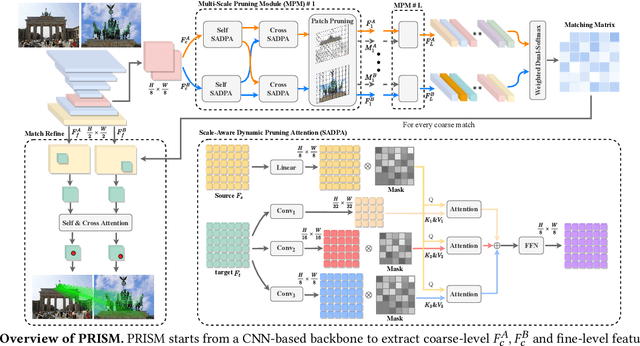

Image matching aims at identifying corresponding points between a pair of images. Currently, detector-free methods have shown impressive performance in challenging scenarios, thanks to their capability of generating dense matches and global receptive field. However, performing feature interaction and proposing matches across the entire image is unnecessary, because not all image regions contribute to the matching process. Interacting and matching in unmatchable areas can introduce errors, reducing matching accuracy and efficiency. Meanwhile, the scale discrepancy issue still troubles existing methods. To address above issues, we propose PRogressive dependency maxImization for Scale-invariant image Matching (PRISM), which jointly prunes irrelevant patch features and tackles the scale discrepancy. To do this, we firstly present a Multi-scale Pruning Module (MPM) to adaptively prune irrelevant features by maximizing the dependency between the two feature sets. Moreover, we design the Scale-Aware Dynamic Pruning Attention (SADPA) to aggregate information from different scales via a hierarchical design. Our method's superior matching performance and generalization capability are confirmed by leading accuracy across various evaluation benchmarks and downstream tasks. The code is publicly available at https://github.com/Master-cai/PRISM.
BEVPlace++: Fast, Robust, and Lightweight LiDAR Global Localization for Unmanned Ground Vehicles
Aug 03, 2024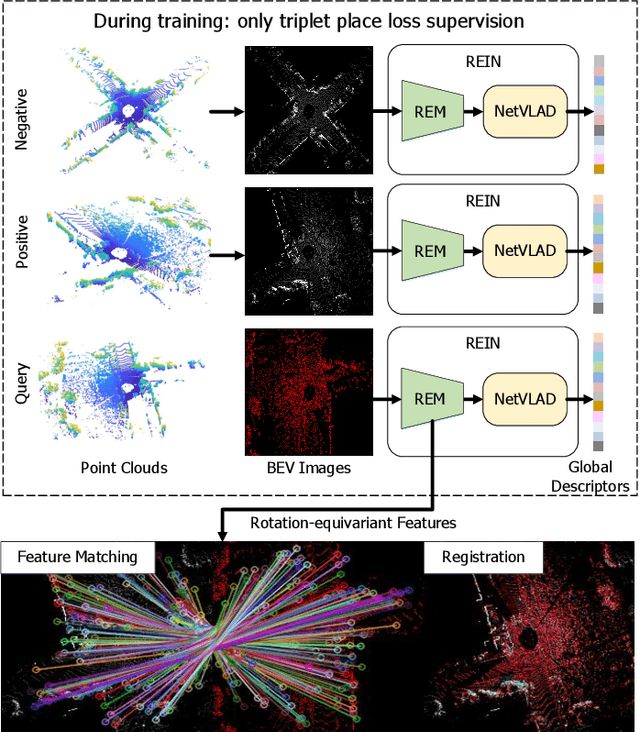
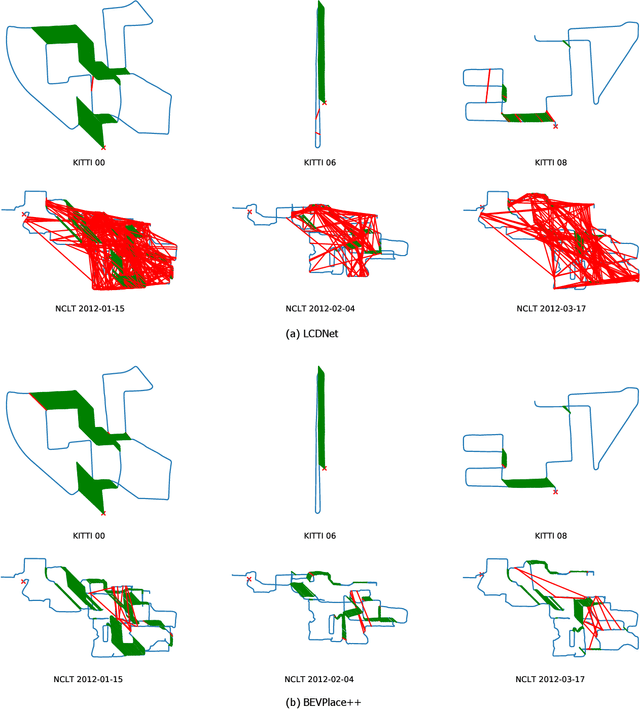
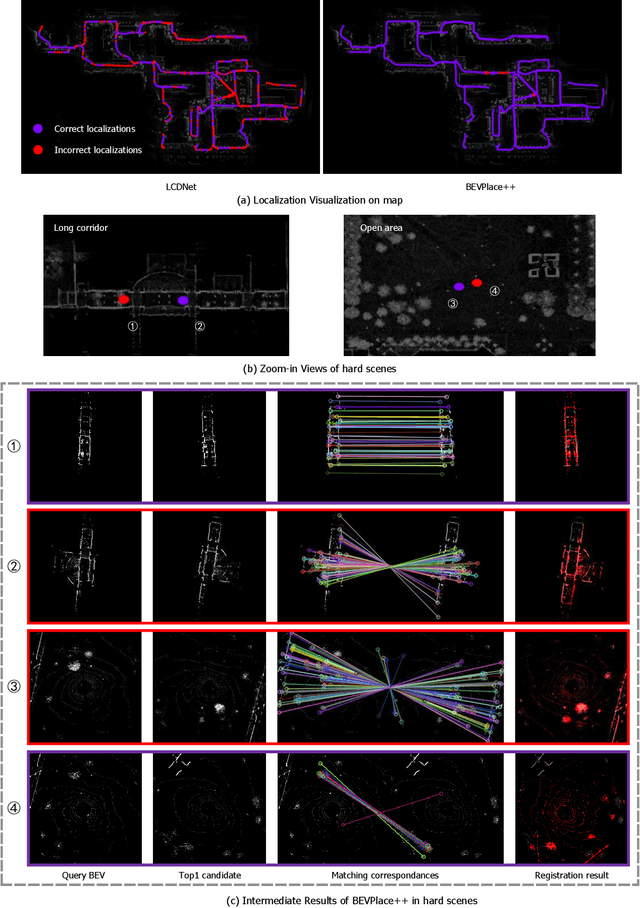
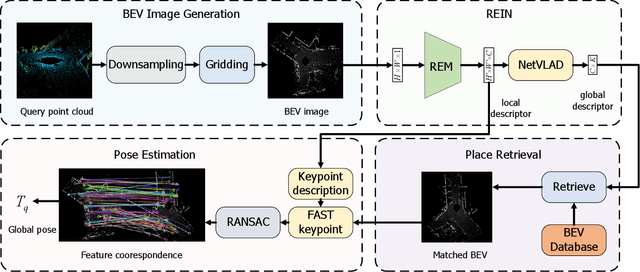
This article introduces BEVPlace++, a novel, fast, and robust LiDAR global localization method for unmanned ground vehicles. It uses lightweight convolutional neural networks (CNNs) on Bird's Eye View (BEV) image-like representations of LiDAR data to achieve accurate global localization through place recognition followed by 3-DoF pose estimation. Our detailed analyses reveal an interesting fact that CNNs are inherently effective at extracting distinctive features from LiDAR BEV images. Remarkably, keypoints of two BEV images with large translations can be effectively matched using CNN-extracted features. Building on this insight, we design a rotation equivariant module (REM) to obtain distinctive features while enhancing robustness to rotational changes. A Rotation Equivariant and Invariant Network (REIN) is then developed by cascading REM and a descriptor generator, NetVLAD, to sequentially generate rotation equivariant local features and rotation invariant global descriptors. The global descriptors are used first to achieve robust place recognition, and the local features are used for accurate pose estimation. Experimental results on multiple public datasets demonstrate that BEVPlace++, even when trained on a small dataset (3000 frames of KITTI) only with place labels, generalizes well to unseen environments, performs consistently across different days and years, and adapts to various types of LiDAR scanners. BEVPlace++ achieves state-of-the-art performance in subtasks of global localization including place recognition, loop closure detection, and global localization. Additionally, BEVPlace++ is lightweight, runs in real-time, and does not require accurate pose supervision, making it highly convenient for deployment. The source codes are publicly available at \href{https://github.com/zjuluolun/BEVPlace}{https://github.com/zjuluolun/BEVPlace}.
S4TP: Social-Suitable and Safety-Sensitive Trajectory Planning for Autonomous Vehicles
Apr 18, 2024



In public roads, autonomous vehicles (AVs) face the challenge of frequent interactions with human-driven vehicles (HDVs), which render uncertain driving behavior due to varying social characteristics among humans. To effectively assess the risks prevailing in the vicinity of AVs in social interactive traffic scenarios and achieve safe autonomous driving, this article proposes a social-suitable and safety-sensitive trajectory planning (S4TP) framework. Specifically, S4TP integrates the Social-Aware Trajectory Prediction (SATP) and Social-Aware Driving Risk Field (SADRF) modules. SATP utilizes Transformers to effectively encode the driving scene and incorporates an AV's planned trajectory during the prediction decoding process. SADRF assesses the expected surrounding risk degrees during AVs-HDVs interactions, each with different social characteristics, visualized as two-dimensional heat maps centered on the AV. SADRF models the driving intentions of the surrounding HDVs and predicts trajectories based on the representation of vehicular interactions. S4TP employs an optimization-based approach for motion planning, utilizing the predicted HDVs'trajectories as input. With the integration of SADRF, S4TP executes real-time online optimization of the planned trajectory of AV within lowrisk regions, thus improving the safety and the interpretability of the planned trajectory. We have conducted comprehensive tests of the proposed method using the SMARTS simulator. Experimental results in complex social scenarios, such as unprotected left turn intersections, merging, cruising, and overtaking, validate the superiority of our proposed S4TP in terms of safety and rationality. S4TP achieves a pass rate of 100% across all scenarios, surpassing the current state-of-the-art methods Fanta of 98.25% and Predictive-Decision of 94.75%.
ModaLink: Unifying Modalities for Efficient Image-to-PointCloud Place Recognition
Mar 27, 2024



Place recognition is an important task for robots and autonomous cars to localize themselves and close loops in pre-built maps. While single-modal sensor-based methods have shown satisfactory performance, cross-modal place recognition that retrieving images from a point-cloud database remains a challenging problem. Current cross-modal methods transform images into 3D points using depth estimation for modality conversion, which are usually computationally intensive and need expensive labeled data for depth supervision. In this work, we introduce a fast and lightweight framework to encode images and point clouds into place-distinctive descriptors. We propose an effective Field of View (FoV) transformation module to convert point clouds into an analogous modality as images. This module eliminates the necessity for depth estimation and helps subsequent modules achieve real-time performance. We further design a non-negative factorization-based encoder to extract mutually consistent semantic features between point clouds and images. This encoder yields more distinctive global descriptors for retrieval. Experimental results on the KITTI dataset show that our proposed methods achieve state-of-the-art performance while running in real time. Additional evaluation on the HAOMO dataset covering a 17 km trajectory further shows the practical generalization capabilities. We have released the implementation of our methods as open source at: https://github.com/haomo-ai/ModaLink.git.
Distilling Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Jan 08, 2024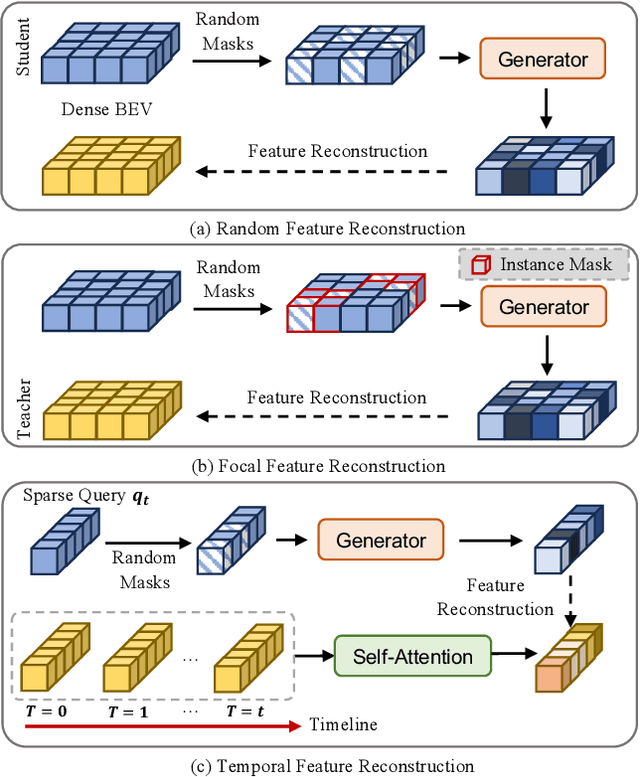
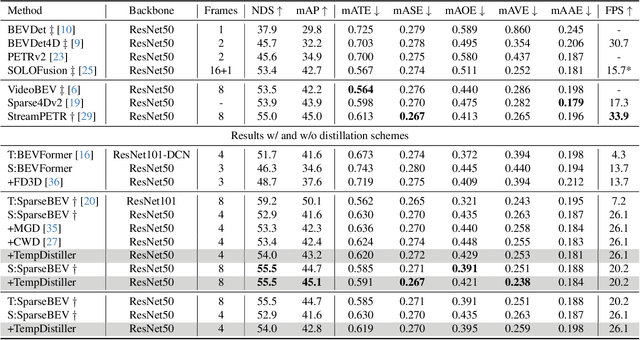
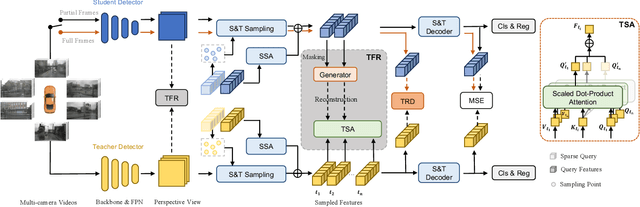
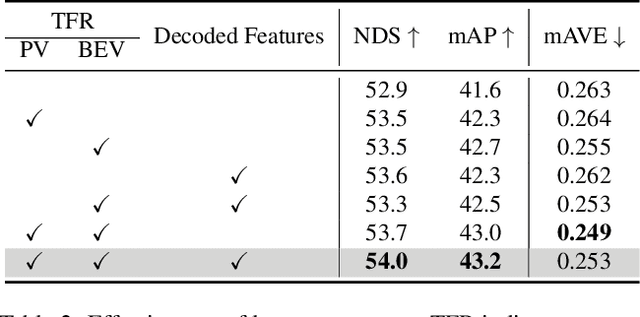
Striking a balance between precision and efficiency presents a prominent challenge in the bird's-eye-view (BEV) 3D object detection. Although previous camera-based BEV methods achieved remarkable performance by incorporating long-term temporal information, most of them still face the problem of low efficiency. One potential solution is knowledge distillation. Existing distillation methods only focus on reconstructing spatial features, while overlooking temporal knowledge. To this end, we propose TempDistiller, a Temporal knowledge Distiller, to acquire long-term memory from a teacher detector when provided with a limited number of frames. Specifically, a reconstruction target is formulated by integrating long-term temporal knowledge through self-attention operation applied to feature teachers. Subsequently, novel features are generated for masked student features via a generator. Ultimately, we utilize this reconstruction target to reconstruct the student features. In addition, we also explore temporal relational knowledge when inputting full frames for the student model. We verify the effectiveness of the proposed method on the nuScenes benchmark. The experimental results show our method obtain an enhancement of +1.6 mAP and +1.1 NDS compared to the baseline, a speed improvement of approximately 6 FPS after compressing temporal knowledge, and the most accurate velocity estimation.
Cam4DOcc: Benchmark for Camera-Only 4D Occupancy Forecasting in Autonomous Driving Applications
Dec 07, 2023



Understanding how the surrounding environment changes is crucial for performing downstream tasks safely and reliably in autonomous driving applications. Recent occupancy estimation techniques using only camera images as input can provide dense occupancy representations of large-scale scenes based on the current observation. However, they are mostly limited to representing the current 3D space and do not consider the future state of surrounding objects along the time axis. To extend camera-only occupancy estimation into spatiotemporal prediction, we propose Cam4DOcc, a new benchmark for camera-only 4D occupancy forecasting, evaluating the surrounding scene changes in a near future. We build our benchmark based on multiple publicly available datasets, including nuScenes, nuScenes-Occupancy, and Lyft-Level5, which provides sequential occupancy states of general movable and static objects, as well as their 3D backward centripetal flow. To establish this benchmark for future research with comprehensive comparisons, we introduce four baseline types from diverse camera-based perception and prediction implementations, including a static-world occupancy model, voxelization of point cloud prediction, 2D-3D instance-based prediction, and our proposed novel end-to-end 4D occupancy forecasting network. Furthermore, the standardized evaluation protocol for preset multiple tasks is also provided to compare the performance of all the proposed baselines on present and future occupancy estimation with respect to objects of interest in autonomous driving scenarios. The dataset and our implementation of all four baselines in the proposed Cam4DOcc benchmark will be released here: https://github.com/haomo-ai/Cam4DOcc.