 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointCSP: Cross-Sample Semantic Propagation and Stability Preservation in Self-Supervised Point Cloud Learning
May 03, 2026Scene-level point cloud self-supervised learning (PC-SSL) has demonstrated potential in enhancing the generalization capability of 3D vision models. Despite the advances in the field through existing methods, the sample-independent modeling paradigm still poses significant limitations in terms of maintaining consistent semantic representations across scenes. This challenge hinders the construction of a unified and transferable semantic space. To address this issue, we propose a PC-SSL framework based on cross-sample semantic propagation (CSP), in which samples within a batch are serialized into continuous input and processed by a state-space model to enable semantic state propagation. This mechanism explicitly models the dynamic dependencies across samples in the state space, allowing the network to establish cross-sample semantic consistency in the latent space and achieve global semantic alignment. Since serialization-based pretraining requires batch-level input organization, we further introduce an asymmetric semantic preservation distillation (SPD) during finetuning to achieve structural alignment of semantic transfer and eliminate inconsistencies caused by batch dependency. The proposed SPD ensures stable transfer of pretrained semantics through a heterogeneous input mechanism and a semantic feature alignment constraint. This enables the model to maintain structured semantic consistency and robustness under single-scene testing conditions. Extensive experiments on multiple benchmark datasets demonstrate that our method consistently outperforms state-of-the-art methods in both performance and semantic consistency.
Distilling Future Temporal Knowledge with Masked Feature Reconstruction for 3D Object Detection
Dec 09, 2025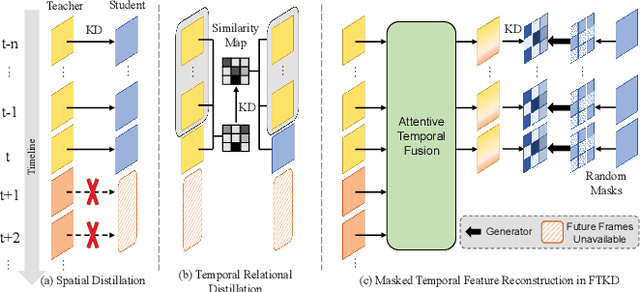
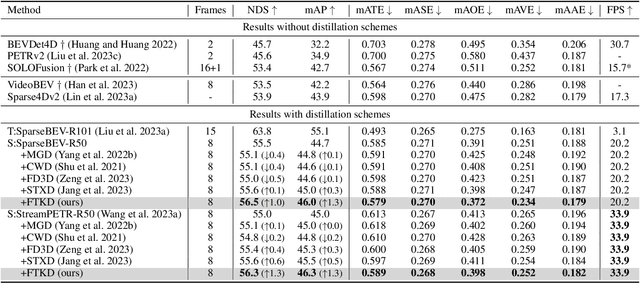
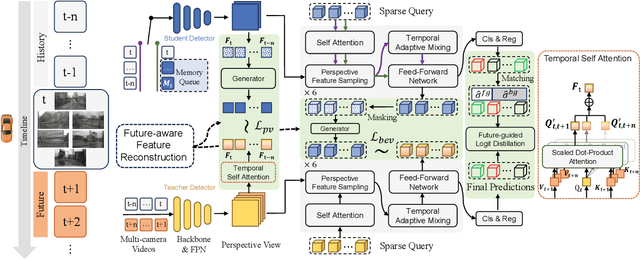
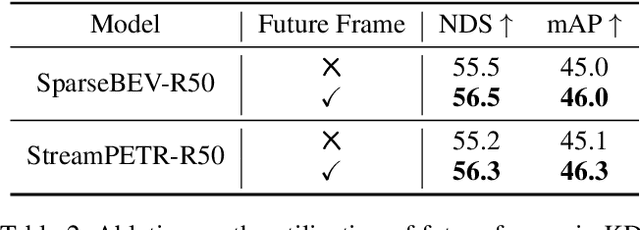
Camera-based temporal 3D object detection has shown impressive results in autonomous driving, with offline models improving accuracy by using future frames. Knowledge distillation (KD) can be an appealing framework for transferring rich information from offline models to online models. However, existing KD methods overlook future frames, as they mainly focus on spatial feature distillation under strict frame alignment or on temporal relational distillation, thereby making it challenging for online models to effectively learn future knowledge. To this end, we propose a sparse query-based approach, Future Temporal Knowledge Distillation (FTKD), which effectively transfers future frame knowledge from an offline teacher model to an online student model. Specifically, we present a future-aware feature reconstruction strategy to encourage the student model to capture future features without strict frame alignment. In addition, we further introduce future-guided logit distillation to leverage the teacher's stable foreground and background context. FTKD is applied to two high-performing 3D object detection baselines, achieving up to 1.3 mAP and 1.3 NDS gains on the nuScenes dataset, as well as the most accurate velocity estimation, without increasing inference cost.
Benchmarking Unified Face Attack Detection via Hierarchical Prompt Tuning
May 19, 2025Presentation Attack Detection and Face Forgery Detection are designed to protect face data from physical media-based Presentation Attacks and digital editing-based DeepFakes respectively. But separate training of these two models makes them vulnerable to unknown attacks and burdens deployment environments. The lack of a Unified Face Attack Detection model to handle both types of attacks is mainly due to two factors. First, there's a lack of adequate benchmarks for models to explore. Existing UAD datasets have limited attack types and samples, restricting the model's ability to address advanced threats. To address this, we propose UniAttackDataPlus (UniAttackData+), the most extensive and sophisticated collection of forgery techniques to date. It includes 2,875 identities and their 54 kinds of falsified samples, totaling 697,347 videos. Second, there's a lack of a reliable classification criterion. Current methods try to find an arbitrary criterion within the same semantic space, which fails when encountering diverse attacks. So, we present a novel Visual-Language Model-based Hierarchical Prompt Tuning Framework (HiPTune) that adaptively explores multiple classification criteria from different semantic spaces. We build a Visual Prompt Tree to explore various classification rules hierarchically. Then, by adaptively pruning the prompts, the model can select the most suitable prompts to guide the encoder to extract discriminative features at different levels in a coarse-to-fine way. Finally, to help the model understand the classification criteria in visual space, we propose a Dynamically Prompt Integration module to project the visual prompts to the text encoder for more accurate semantics. Experiments on 12 datasets have shown the potential to inspire further innovations in the UAD field.
FA^{3}-CLIP: Frequency-Aware Cues Fusion and Attack-Agnostic Prompt Learning for Unified Face Attack Detection
Apr 01, 2025



Facial recognition systems are vulnerable to physical (e.g., printed photos) and digital (e.g., DeepFake) face attacks. Existing methods struggle to simultaneously detect physical and digital attacks due to: 1) significant intra-class variations between these attack types, and 2) the inadequacy of spatial information alone to comprehensively capture live and fake cues. To address these issues, we propose a unified attack detection model termed Frequency-Aware and Attack-Agnostic CLIP (FA\textsuperscript{3}-CLIP), which introduces attack-agnostic prompt learning to express generic live and fake cues derived from the fusion of spatial and frequency features, enabling unified detection of live faces and all categories of attacks. Specifically, the attack-agnostic prompt module generates generic live and fake prompts within the language branch to extract corresponding generic representations from both live and fake faces, guiding the model to learn a unified feature space for unified attack detection. Meanwhile, the module adaptively generates the live/fake conditional bias from the original spatial and frequency information to optimize the generic prompts accordingly, reducing the impact of intra-class variations. We further propose a dual-stream cues fusion framework in the vision branch, which leverages frequency information to complement subtle cues that are difficult to capture in the spatial domain. In addition, a frequency compression block is utilized in the frequency stream, which reduces redundancy in frequency features while preserving the diversity of crucial cues. We also establish new challenging protocols to facilitate unified face attack detection effectiveness. Experimental results demonstrate that the proposed method significantly improves performance in detecting physical and digital face attacks, achieving state-of-the-art results.
Stochastic Trajectory Prediction under Unstructured Constraints
Mar 18, 2025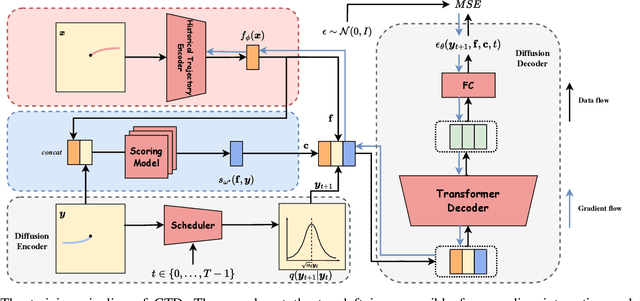
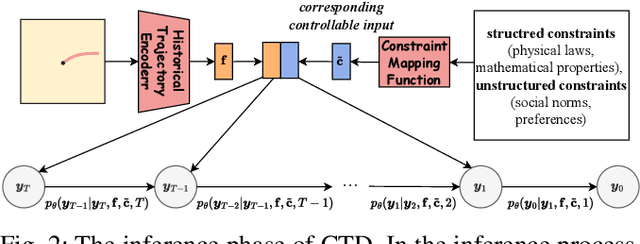
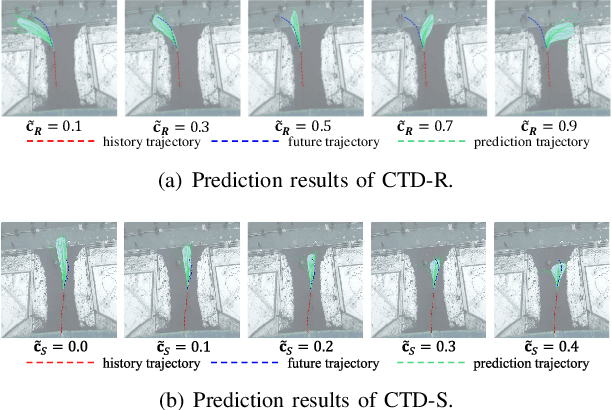
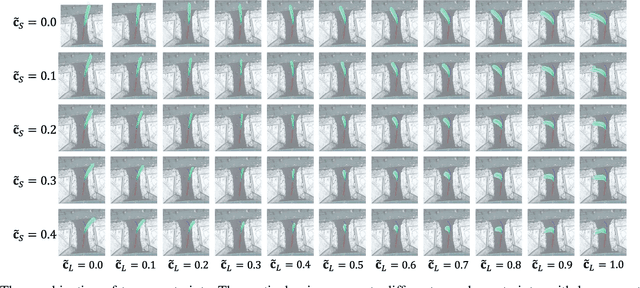
Trajectory prediction facilitates effective planning and decision-making, while constrained trajectory prediction integrates regulation into prediction. Recent advances in constrained trajectory prediction focus on structured constraints by constructing optimization objectives. However, handling unstructured constraints is challenging due to the lack of differentiable formal definitions. To address this, we propose a novel method for constrained trajectory prediction using a conditional generative paradigm, named Controllable Trajectory Diffusion (CTD). The key idea is that any trajectory corresponds to a degree of conformity to a constraint. By quantifying this degree and treating it as a condition, a model can implicitly learn to predict trajectories under unstructured constraints. CTD employs a pre-trained scoring model to predict the degree of conformity (i.e., a score), and uses this score as a condition for a conditional diffusion model to generate trajectories. Experimental results demonstrate that CTD achieves high accuracy on the ETH/UCY and SDD benchmarks. Qualitative analysis confirms that CTD ensures adherence to unstructured constraints and can predict trajectories that satisfy combinatorial constraints.
Not All Frame Features Are Equal: Video-to-4D Generation via Decoupling Dynamic-Static Features
Feb 12, 2025Recently, the generation of dynamic 3D objects from a video has shown impressive results. Existing methods directly optimize Gaussians using whole information in frames. However, when dynamic regions are interwoven with static regions within frames, particularly if the static regions account for a large proportion, existing methods often overlook information in dynamic regions and are prone to overfitting on static regions. This leads to producing results with blurry textures. We consider that decoupling dynamic-static features to enhance dynamic representations can alleviate this issue. Thus, we propose a dynamic-static feature decoupling module (DSFD). Along temporal axes, it regards the portions of current frame features that possess significant differences relative to reference frame features as dynamic features. Conversely, the remaining parts are the static features. Then, we acquire decoupled features driven by dynamic features and current frame features. Moreover, to further enhance the dynamic representation of decoupled features from different viewpoints and ensure accurate motion prediction, we design a temporal-spatial similarity fusion module (TSSF). Along spatial axes, it adaptively selects a similar information of dynamic regions. Hinging on the above, we construct a novel approach, DS4D. Experimental results verify our method achieves state-of-the-art (SOTA) results in video-to-4D. In addition, the experiments on a real-world scenario dataset demonstrate its effectiveness on the 4D scene. Our code will be publicly available.
SSEditor: Controllable Mask-to-Scene Generation with Diffusion Model
Nov 19, 2024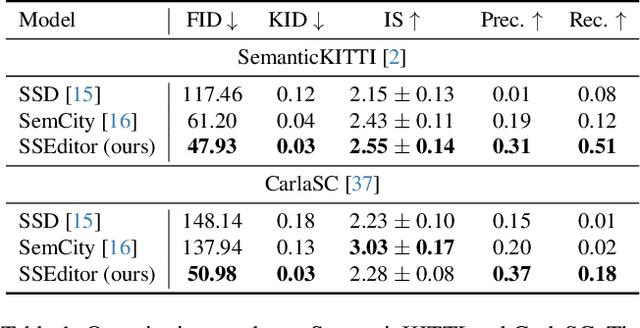
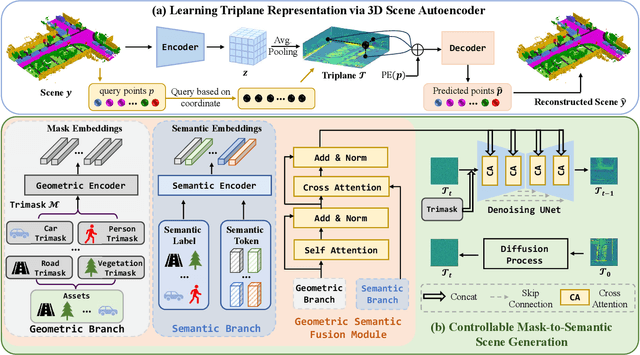

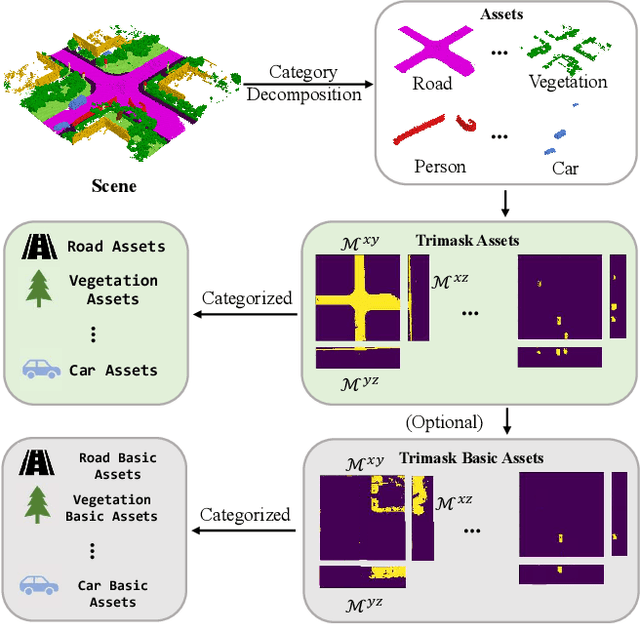
Recent advancements in 3D diffusion-based semantic scene generation have gained attention. However, existing methods rely on unconditional generation and require multiple resampling steps when editing scenes, which significantly limits their controllability and flexibility. To this end, we propose SSEditor, a controllable Semantic Scene Editor that can generate specified target categories without multiple-step resampling. SSEditor employs a two-stage diffusion-based framework: (1) a 3D scene autoencoder is trained to obtain latent triplane features, and (2) a mask-conditional diffusion model is trained for customizable 3D semantic scene generation. In the second stage, we introduce a geometric-semantic fusion module that enhance the model's ability to learn geometric and semantic information. This ensures that objects are generated with correct positions, sizes, and categories. Extensive experiments on SemanticKITTI and CarlaSC demonstrate that SSEditor outperforms previous approaches in terms of controllability and flexibility in target generation, as well as the quality of semantic scene generation and reconstruction. More importantly, experiments on the unseen Occ-3D Waymo dataset show that SSEditor is capable of generating novel urban scenes, enabling the rapid construction of 3D scenes.
Coevolving with the Other You: Fine-Tuning LLM with Sequential Cooperative Multi-Agent Reinforcement Learning
Oct 08, 2024



Reinforcement learning (RL) has emerged as a pivotal technique for fine-tuning large language models (LLMs) on specific tasks. However, prevailing RL fine-tuning methods predominantly rely on PPO and its variants. Though these algorithms are effective in general RL settings, they often exhibit suboptimal performance and vulnerability to distribution collapse when applied to the fine-tuning of LLMs. In this paper, we propose CORY, extending the RL fine-tuning of LLMs to a sequential cooperative multi-agent reinforcement learning framework, to leverage the inherent coevolution and emergent capabilities of multi-agent systems. In CORY, the LLM to be fine-tuned is initially duplicated into two autonomous agents: a pioneer and an observer. The pioneer generates responses based on queries, while the observer generates responses using both the queries and the pioneer's responses. The two agents are trained together. During training, the agents exchange roles periodically, fostering cooperation and coevolution between them. Experiments evaluate CORY's performance by fine-tuning GPT-2 and Llama-2 under subjective and objective reward functions on the IMDB Review and GSM8K datasets, respectively. Results show that CORY outperforms PPO in terms of policy optimality, resistance to distribution collapse, and training robustness, thereby underscoring its potential as a superior methodology for refining LLMs in real-world applications.
C${^2}$RL: Content and Context Representation Learning for Gloss-free Sign Language Translation and Retrieval
Aug 19, 2024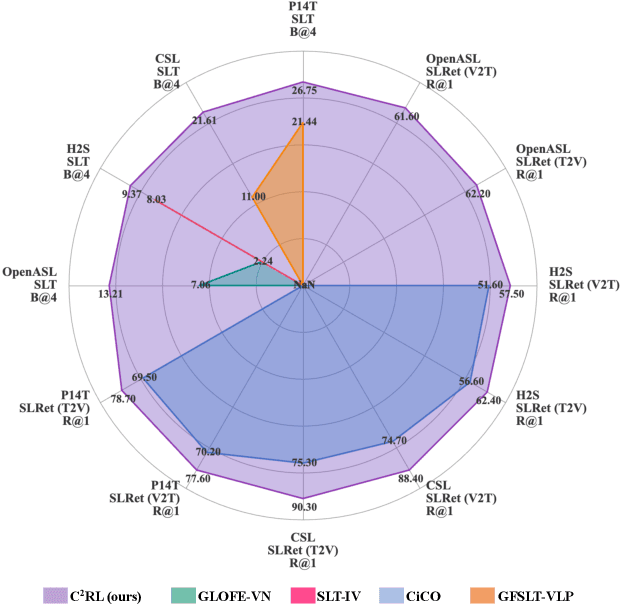
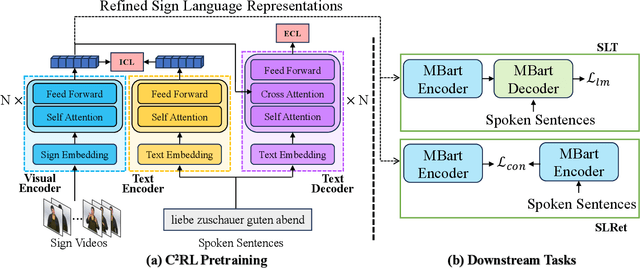
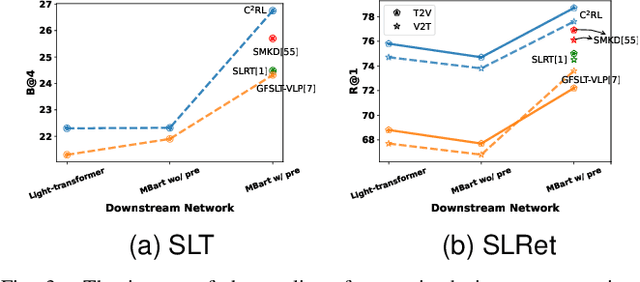
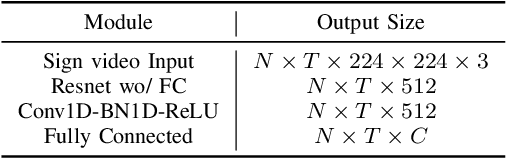
Sign Language Representation Learning (SLRL) is crucial for a range of sign language-related downstream tasks such as Sign Language Translation (SLT) and Sign Language Retrieval (SLRet). Recently, many gloss-based and gloss-free SLRL methods have been proposed, showing promising performance. Among them, the gloss-free approach shows promise for strong scalability without relying on gloss annotations. However, it currently faces suboptimal solutions due to challenges in encoding the intricate, context-sensitive characteristics of sign language videos, mainly struggling to discern essential sign features using a non-monotonic video-text alignment strategy. Therefore, we introduce an innovative pretraining paradigm for gloss-free SLRL, called C${^2}$RL, in this paper. Specifically, rather than merely incorporating a non-monotonic semantic alignment of video and text to learn language-oriented sign features, we emphasize two pivotal aspects of SLRL: Implicit Content Learning (ICL) and Explicit Context Learning (ECL). ICL delves into the content of communication, capturing the nuances, emphasis, timing, and rhythm of the signs. In contrast, ECL focuses on understanding the contextual meaning of signs and converting them into equivalent sentences. Despite its simplicity, extensive experiments confirm that the joint optimization of ICL and ECL results in robust sign language representation and significant performance gains in gloss-free SLT and SLRet tasks. Notably, C${^2}$RL improves the BLEU-4 score by +5.3 on P14T, +10.6 on CSL-daily, +6.2 on OpenASL, and +1.3 on How2Sign. It also boosts the R@1 score by +8.3 on P14T, +14.4 on CSL-daily, and +5.9 on How2Sign. Additionally, we set a new baseline for the OpenASL dataset in the SLRet task.
FeTT: Continual Class Incremental Learning via Feature Transformation Tuning
May 20, 2024Continual learning (CL) aims to extend deep models from static and enclosed environments to dynamic and complex scenarios, enabling systems to continuously acquire new knowledge of novel categories without forgetting previously learned knowledge. Recent CL models have gradually shifted towards the utilization of pre-trained models (PTMs) with parameter-efficient fine-tuning (PEFT) strategies. However, continual fine-tuning still presents a serious challenge of catastrophic forgetting due to the absence of previous task data. Additionally, the fine-tune-then-frozen mechanism suffers from performance limitations due to feature channels suppression and insufficient training data in the first CL task. To this end, this paper proposes feature transformation tuning (FeTT) model to non-parametrically fine-tune backbone features across all tasks, which not only operates independently of CL training data but also smooths feature channels to prevent excessive suppression. Then, the extended ensemble strategy incorporating different PTMs with FeTT model facilitates further performance improvement. We further elaborate on the discussions of the fine-tune-then-frozen paradigm and the FeTT model from the perspectives of discrepancy in class marginal distributions and feature channels. Extensive experiments on CL benchmarks validate the effectiveness of our proposed method.