 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancingBox: A Lightweight MoCap System for Character Animation from Physical Proxies
Mar 18, 2026Creating compelling 3D character animations typically requires either expert use of professional software or expensive motion capture systems operated by skilled actors. We present DancingBox, a lightweight, vision-based system that makes motion capture accessible to novices by reimagining the process as digital puppetry. Instead of tracking precise human motions, DancingBox captures the approximate movements of everyday objects manipulated by users with a single webcam. These coarse proxy motions are then refined into realistic character animations by conditioning a generative motion model on bounding-box representations, enriched with human motion priors learned from large-scale datasets. To overcome the lack of paired proxy-animation data, we synthesize training pairs by converting existing motion capture sequences into proxy representations. A user study demonstrates that DancingBox enables intuitive and creative character animation using diverse proxies, from plush toys to bananas, lowering the barrier to entry for novice animators.
AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications
Feb 26, 2026Large Language Models (LLMs) are deployed as autonomous agents in increasingly complex applications, where enabling long-horizon memory is critical for achieving strong performance. However, a significant gap exists between practical applications and current evaluation standards for agent memory: existing benchmarks primarily focus on dialogue-centric, human-agent interactions. In reality, agent memory consists of a continuous stream of agent-environment interactions that are primarily composed of machine-generated representations. To bridge this gap, we introduce AMA-Bench (Agent Memory with Any length), which evaluates long-horizon memory for LLMs in real agentic applications. It features two key components: (1) a set of real-world agentic trajectories across representative agentic applications, paired with expert-curated QA, and (2) a set of synthetic agentic trajectories that scale to arbitrary horizons, paired with rule-based QA. Our comprehensive study shows that existing memory systems underperform on AMA-Bench primarily because they lack causality and objective information and are constrained by the lossy nature of similarity-based retrieval employed by many memory systems. To address these limitations, we propose AMA-Agent, an effective memory system featuring a causality graph and tool-augmented retrieval. Our results demonstrate that AMA-Agent achieves 57.22% average accuracy on AMA-Bench, surpassing the strongest memory system baselines by 11.16%.
Benchmarking Unified Face Attack Detection via Hierarchical Prompt Tuning
May 19, 2025Presentation Attack Detection and Face Forgery Detection are designed to protect face data from physical media-based Presentation Attacks and digital editing-based DeepFakes respectively. But separate training of these two models makes them vulnerable to unknown attacks and burdens deployment environments. The lack of a Unified Face Attack Detection model to handle both types of attacks is mainly due to two factors. First, there's a lack of adequate benchmarks for models to explore. Existing UAD datasets have limited attack types and samples, restricting the model's ability to address advanced threats. To address this, we propose UniAttackDataPlus (UniAttackData+), the most extensive and sophisticated collection of forgery techniques to date. It includes 2,875 identities and their 54 kinds of falsified samples, totaling 697,347 videos. Second, there's a lack of a reliable classification criterion. Current methods try to find an arbitrary criterion within the same semantic space, which fails when encountering diverse attacks. So, we present a novel Visual-Language Model-based Hierarchical Prompt Tuning Framework (HiPTune) that adaptively explores multiple classification criteria from different semantic spaces. We build a Visual Prompt Tree to explore various classification rules hierarchically. Then, by adaptively pruning the prompts, the model can select the most suitable prompts to guide the encoder to extract discriminative features at different levels in a coarse-to-fine way. Finally, to help the model understand the classification criteria in visual space, we propose a Dynamically Prompt Integration module to project the visual prompts to the text encoder for more accurate semantics. Experiments on 12 datasets have shown the potential to inspire further innovations in the UAD field.
DiffCSG: Differentiable CSG via Rasterization
Sep 02, 2024Differentiable rendering is a key ingredient for inverse rendering and machine learning, as it allows to optimize scene parameters (shape, materials, lighting) to best fit target images. Differentiable rendering requires that each scene parameter relates to pixel values through differentiable operations. While 3D mesh rendering algorithms have been implemented in a differentiable way, these algorithms do not directly extend to Constructive-Solid-Geometry (CSG), a popular parametric representation of shapes, because the underlying boolean operations are typically performed with complex black-box mesh-processing libraries. We present an algorithm, DiffCSG, to render CSG models in a differentiable manner. Our algorithm builds upon CSG rasterization, which displays the result of boolean operations between primitives without explicitly computing the resulting mesh and, as such, bypasses black-box mesh processing. We describe how to implement CSG rasterization within a differentiable rendering pipeline, taking special care to apply antialiasing along primitive intersections to obtain gradients in such critical areas. Our algorithm is simple and fast, can be easily incorporated into modern machine learning setups, and enables a range of applications for computer-aided design, including direct and image-based editing of CSG primitives. Code and data: https://yyyyyhc.github.io/DiffCSG/.
Unified Physical-Digital Attack Detection Challenge
Apr 09, 2024Face Anti-Spoofing (FAS) is crucial to safeguard Face Recognition (FR) Systems. In real-world scenarios, FRs are confronted with both physical and digital attacks. However, existing algorithms often address only one type of attack at a time, which poses significant limitations in real-world scenarios where FR systems face hybrid physical-digital threats. To facilitate the research of Unified Attack Detection (UAD) algorithms, a large-scale UniAttackData dataset has been collected. UniAttackData is the largest public dataset for Unified Attack Detection, with a total of 28,706 videos, where each unique identity encompasses all advanced attack types. Based on this dataset, we organized a Unified Physical-Digital Face Attack Detection Challenge to boost the research in Unified Attack Detections. It attracted 136 teams for the development phase, with 13 qualifying for the final round. The results re-verified by the organizing team were used for the final ranking. This paper comprehensively reviews the challenge, detailing the dataset introduction, protocol definition, evaluation criteria, and a summary of published results. Finally, we focus on the detailed analysis of the highest-performing algorithms and offer potential directions for unified physical-digital attack detection inspired by this competition. Challenge Website: https://sites.google.com/view/face-anti-spoofing-challenge/welcome/challengecvpr2024.
Unified Physical-Digital Face Attack Detection
Jan 31, 2024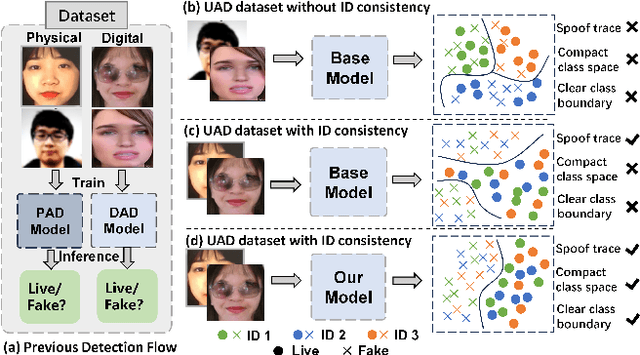
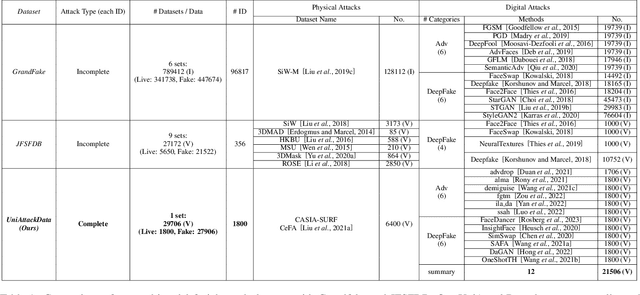
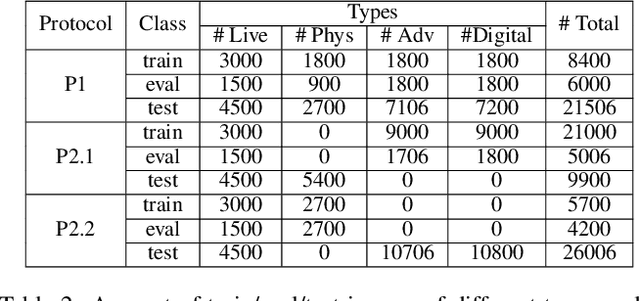

Face Recognition (FR) systems can suffer from physical (i.e., print photo) and digital (i.e., DeepFake) attacks. However, previous related work rarely considers both situations at the same time. This implies the deployment of multiple models and thus more computational burden. The main reasons for this lack of an integrated model are caused by two factors: (1) The lack of a dataset including both physical and digital attacks with ID consistency which means the same ID covers the real face and all attack types; (2) Given the large intra-class variance between these two attacks, it is difficult to learn a compact feature space to detect both attacks simultaneously. To address these issues, we collect a Unified physical-digital Attack dataset, called UniAttackData. The dataset consists of $1,800$ participations of 2 and 12 physical and digital attacks, respectively, resulting in a total of 29,706 videos. Then, we propose a Unified Attack Detection framework based on Vision-Language Models (VLMs), namely UniAttackDetection, which includes three main modules: the Teacher-Student Prompts (TSP) module, focused on acquiring unified and specific knowledge respectively; the Unified Knowledge Mining (UKM) module, designed to capture a comprehensive feature space; and the Sample-Level Prompt Interaction (SLPI) module, aimed at grasping sample-level semantics. These three modules seamlessly form a robust unified attack detection framework. Extensive experiments on UniAttackData and three other datasets demonstrate the superiority of our approach for unified face attack detection.
CADTalk: An Algorithm and Benchmark for Semantic Commenting of CAD Programs
Nov 30, 2023



CAD programs are a popular way to compactly encode shapes as a sequence of operations that are easy to parametrically modify. However, without sufficient semantic comments and structure, such programs can be challenging to understand, let alone modify. We introduce the problem of semantic commenting CAD programs, wherein the goal is to segment the input program into code blocks corresponding to semantically meaningful shape parts and assign a semantic label to each block. We solve the problem by combining program parsing with visual-semantic analysis afforded by recent advances in foundational language and vision models. Specifically, by executing the input programs, we create shapes, which we use to generate conditional photorealistic images to make use of semantic annotators for such images. We then distill the information across the images and link back to the original programs to semantically comment on them. Additionally, we collected and annotated a benchmark dataset, CADTalk, consisting of 5,280 machine-made programs and 45 human-made programs with ground truth semantic comments to foster future research. We extensively evaluated our approach, compared to a GPT-based baseline approach, and an open-set shape segmentation baseline, i.e., PartSLIP, and reported an 83.24% accuracy on the new CADTalk dataset. Project page: https://enigma-li.github.io/CADTalk/.
Enhancing Generalizable 6D Pose Tracking of an In-Hand Object with Tactile Sensing
Oct 08, 2022
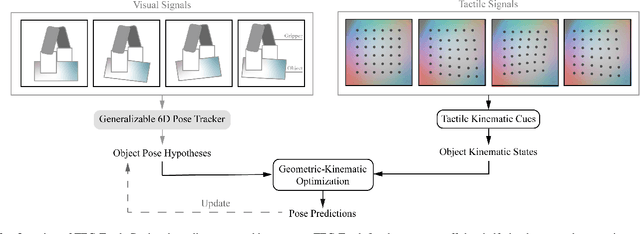


While holding and manipulating an object, humans track the object states through vision and touch so as to achieve complex tasks. However, nowadays the majority of robot research perceives object states just from visual signals, hugely limiting the robotic manipulation abilities. This work presents a tactile-enhanced generalizable 6D pose tracking design named TEG-Track to track previously unseen in-hand objects. TEG-Track extracts tactile kinematic cues of an in-hand object from consecutive tactile sensing signals. Such cues are incorporated into a geometric-kinematic optimization scheme to enhance existing generalizable visual trackers. To test our method in real scenarios and enable future studies on generalizable visual-tactile tracking, we collect a real visual-tactile in-hand object pose tracking dataset. Experiments show that TEG-Track significantly improves state-of-the-art generalizable 6D pose trackers in both synthetic and real cases.
Unsupervised Learning of 3D Semantic Keypoints with Mutual Reconstruction
Mar 19, 2022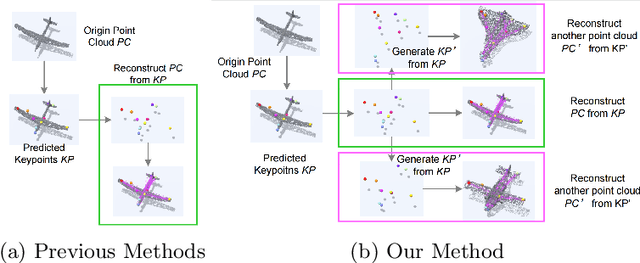
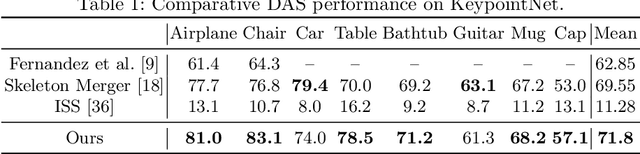
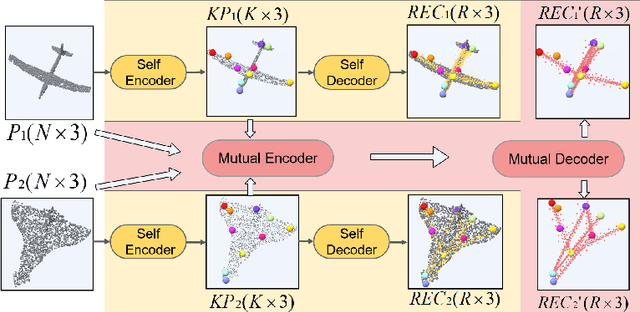
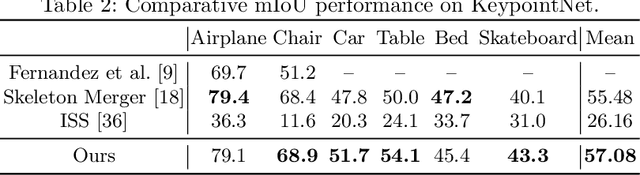
Semantic 3D keypoints are category-level semantic consistent points on 3D objects. Detecting 3D semantic keypoints is a foundation for a number of 3D vision tasks but remains challenging, due to the ambiguity of semantic information, especially when the objects are represented by unordered 3D point clouds. Existing unsupervised methods tend to generate category-level keypoints in implicit manners, making it difficult to extract high-level information, such as semantic labels and topology. From a novel mutual reconstruction perspective, we present an unsupervised method to generate consistent semantic keypoints from point clouds explicitly. To achieve this, the proposed model predicts keypoints that not only reconstruct the object itself but also reconstruct other instances in the same category. To the best of our knowledge, the proposed method is the first to mine 3D semantic consistent keypoints from a mutual reconstruction view. Experiments under various evaluation metrics as well as comparisons with the state-of-the-arts demonstrate the efficacy of our new solution to mining semantic consistent keypoints with mutual reconstruction.