 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboGene: Boosting VLA Pre-training via Diversity-Driven Agentic Framework for Real-World Task Generation
Feb 19, 2026The pursuit of general-purpose robotic manipulation is hindered by the scarcity of diverse, real-world interaction data. Unlike data collection from web in vision or language, robotic data collection is an active process incurring prohibitive physical costs. Consequently, automated task curation to maximize data value remains a critical yet under-explored challenge. Existing manual methods are unscalable and biased toward common tasks, while off-the-shelf foundation models often hallucinate physically infeasible instructions. To address this, we introduce RoboGene, an agentic framework designed to automate the generation of diverse, physically plausible manipulation tasks across single-arm, dual-arm, and mobile robots. RoboGene integrates three core components: diversity-driven sampling for broad task coverage, self-reflection mechanisms to enforce physical constraints, and human-in-the-loop refinement for continuous improvement. We conduct extensive quantitative analysis and large-scale real-world experiments, collecting datasets of 18k trajectories and introducing novel metrics to assess task quality, feasibility, and diversity. Results demonstrate that RoboGene significantly outperforms state-of-the-art foundation models (e.g., GPT-4o, Gemini 2.5 Pro). Furthermore, real-world experiments show that VLA models pre-trained with RoboGene achieve higher success rates and superior generalization, underscoring the importance of high-quality task generation. Our project is available at https://robogene-boost-vla.github.io.
RoboAug: One Annotation to Hundreds of Scenes via Region-Contrastive Data Augmentation for Robotic Manipulation
Feb 15, 2026Enhancing the generalization capability of robotic learning to enable robots to operate effectively in diverse, unseen scenes is a fundamental and challenging problem. Existing approaches often depend on pretraining with large-scale data collection, which is labor-intensive and time-consuming, or on semantic data augmentation techniques that necessitate an impractical assumption of flawless upstream object detection in real-world scenarios. In this work, we propose RoboAug, a novel generative data augmentation framework that significantly minimizes the reliance on large-scale pretraining and the perfect visual recognition assumption by requiring only the bounding box annotation of a single image during training. Leveraging this minimal information, RoboAug employs pre-trained generative models for precise semantic data augmentation and integrates a plug-and-play region-contrastive loss to help models focus on task-relevant regions, thereby improving generalization and boosting task success rates. We conduct extensive real-world experiments on three robots, namely UR-5e, AgileX, and Tien Kung 2.0, spanning over 35k rollouts. Empirical results demonstrate that RoboAug significantly outperforms state-of-the-art data augmentation baselines. Specifically, when evaluating generalization capabilities in unseen scenes featuring diverse combinations of backgrounds, distractors, and lighting conditions, our method achieves substantial gains over the baseline without augmentation. The success rates increase from 0.09 to 0.47 on UR-5e, from 0.16 to 0.60 on AgileX, and from 0.19 to 0.67 on Tien Kung 2.0. These results highlight the superior generalization and effectiveness of RoboAug in real-world manipulation tasks. Our project is available at https://x-roboaug.github.io/.
RoboMIND 2.0: A Multimodal, Bimanual Mobile Manipulation Dataset for Generalizable Embodied Intelligence
Dec 31, 2025While data-driven imitation learning has revolutionized robotic manipulation, current approaches remain constrained by the scarcity of large-scale, diverse real-world demonstrations. Consequently, the ability of existing models to generalize across long-horizon bimanual tasks and mobile manipulation in unstructured environments remains limited. To bridge this gap, we present RoboMIND 2.0, a comprehensive real-world dataset comprising over 310K dual-arm manipulation trajectories collected across six distinct robot embodiments and 739 complex tasks. Crucially, to support research in contact-rich and spatially extended tasks, the dataset incorporates 12K tactile-enhanced episodes and 20K mobile manipulation trajectories. Complementing this physical data, we construct high-fidelity digital twins of our real-world environments, releasing an additional 20K-trajectory simulated dataset to facilitate robust sim-to-real transfer. To fully exploit the potential of RoboMIND 2.0, we propose MIND-2 system, a hierarchical dual-system frame-work optimized via offline reinforcement learning. MIND-2 integrates a high-level semantic planner (MIND-2-VLM) to decompose abstract natural language instructions into grounded subgoals, coupled with a low-level Vision-Language-Action executor (MIND-2-VLA), which generates precise, proprioception-aware motor actions.
RoboMIND: Benchmark on Multi-embodiment Intelligence Normative Data for Robot Manipulation
Dec 18, 2024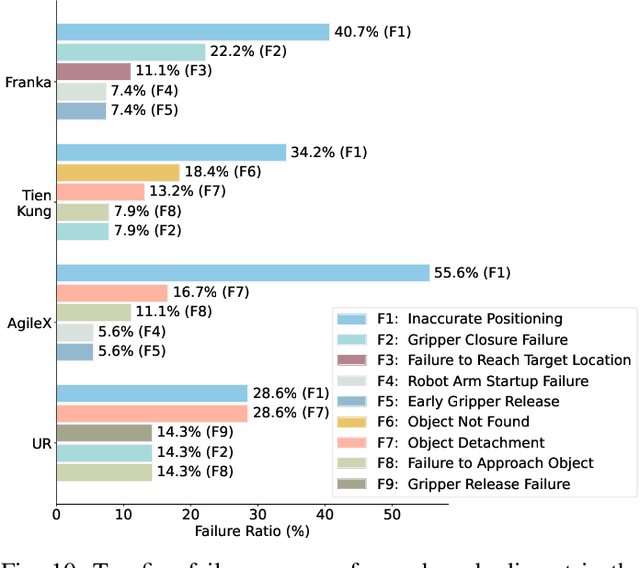
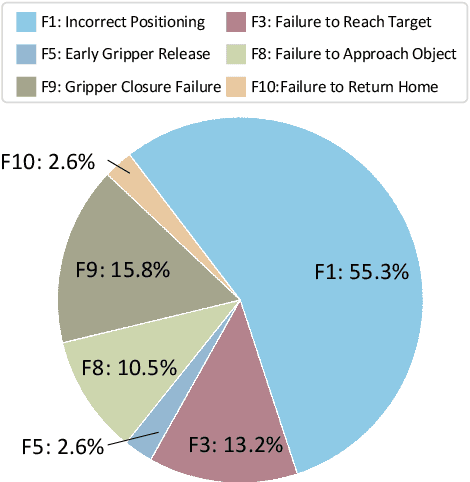
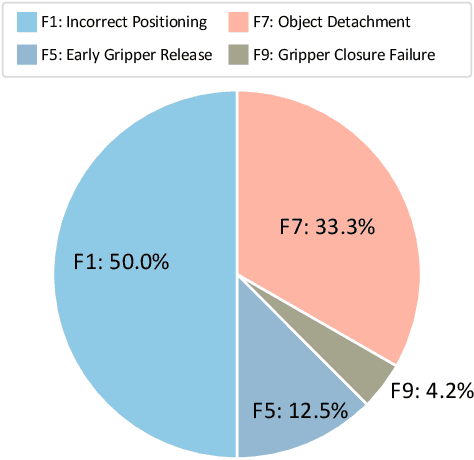
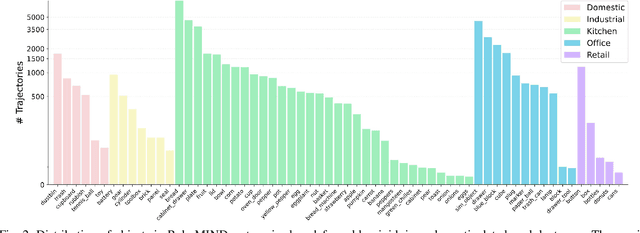
Developing robust and general-purpose robotic manipulation policies is a key goal in the field of robotics. To achieve effective generalization, it is essential to construct comprehensive datasets that encompass a large number of demonstration trajectories and diverse tasks. Unlike vision or language data that can be collected from the Internet, robotic datasets require detailed observations and manipulation actions, necessitating significant investment in hardware-software infrastructure and human labor. While existing works have focused on assembling various individual robot datasets, there remains a lack of a unified data collection standard and insufficient diversity in tasks, scenarios, and robot types. In this paper, we introduce RoboMIND (Multi-embodiment Intelligence Normative Data for Robot manipulation), featuring 55k real-world demonstration trajectories across 279 diverse tasks involving 61 different object classes. RoboMIND is collected through human teleoperation and encompasses comprehensive robotic-related information, including multi-view RGB-D images, proprioceptive robot state information, end effector details, and linguistic task descriptions. To ensure dataset consistency and reliability during policy learning, RoboMIND is built on a unified data collection platform and standardized protocol, covering four distinct robotic embodiments. We provide a thorough quantitative and qualitative analysis of RoboMIND across multiple dimensions, offering detailed insights into the diversity of our datasets. In our experiments, we conduct extensive real-world testing with four state-of-the-art imitation learning methods, demonstrating that training with RoboMIND data results in a high manipulation success rate and strong generalization. Our project is at https://x-humanoid-robomind.github.io/.
Towards Generalizable Referring Image Segmentation via Target Prompt and Visual Coherence
Dec 01, 2023
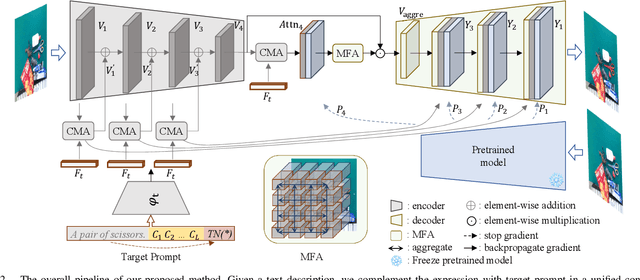
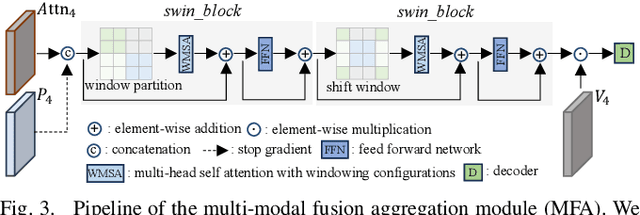

Referring image segmentation (RIS) aims to segment objects in an image conditioning on free-from text descriptions. Despite the overwhelming progress, it still remains challenging for current approaches to perform well on cases with various text expressions or with unseen visual entities, limiting its further application. In this paper, we present a novel RIS approach, which substantially improves the generalization ability by addressing the two dilemmas mentioned above. Specially, to deal with unconstrained texts, we propose to boost a given expression with an explicit and crucial prompt, which complements the expression in a unified context, facilitating target capturing in the presence of linguistic style changes. Furthermore, we introduce a multi-modal fusion aggregation module with visual guidance from a powerful pretrained model to leverage spatial relations and pixel coherences to handle the incomplete target masks and false positive irregular clumps which often appear on unseen visual entities. Extensive experiments are conducted in the zero-shot cross-dataset settings and the proposed approach achieves consistent gains compared to the state-of-the-art, e.g., 4.15\%, 5.45\%, and 4.64\% mIoU increase on RefCOCO, RefCOCO+ and ReferIt respectively, demonstrating its effectiveness. Additionally, the results on GraspNet-RIS show that our approach also generalizes well to new scenarios with large domain shifts.
An Empirical Study on Multi-Domain Robust Semantic Segmentation
Dec 08, 2022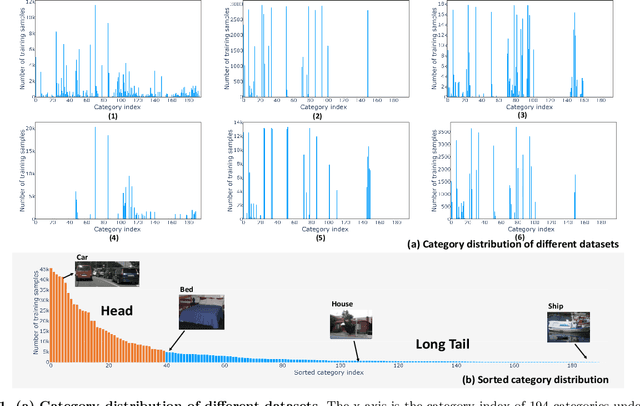
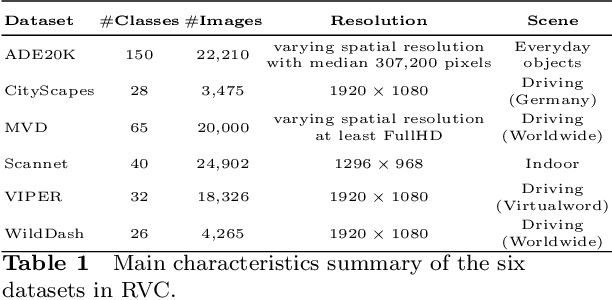

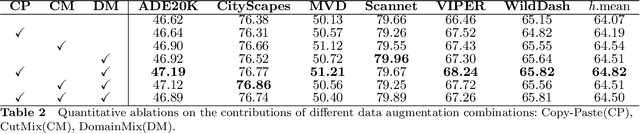
How to effectively leverage the plentiful existing datasets to train a robust and high-performance model is of great significance for many practical applications. However, a model trained on a naive merge of different datasets tends to obtain poor performance due to annotation conflicts and domain divergence.In this paper, we attempt to train a unified model that is expected to perform well across domains on several popularity segmentation datasets.We conduct a detailed analysis of the impact on model generalization from three aspects of data augmentation, training strategies, and model capacity.Based on the analysis, we propose a robust solution that is able to improve model generalization across domains.Our solution ranks 2nd on RVC 2022 semantic segmentation task, with a dataset only 1/3 size of the 1st model used.
Unsupervised Learning of 3D Semantic Keypoints with Mutual Reconstruction
Mar 19, 2022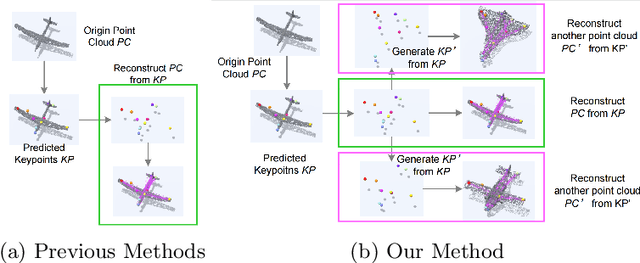
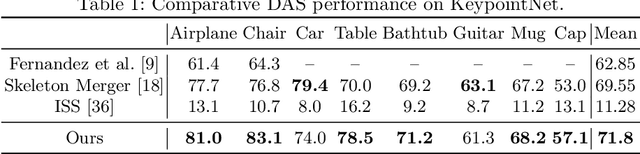
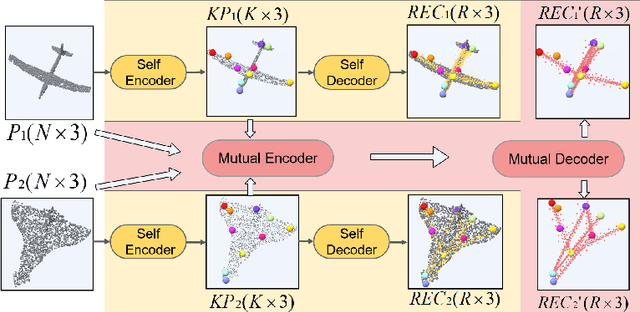
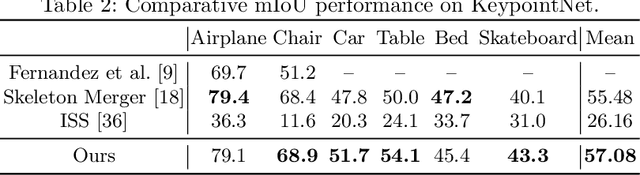
Semantic 3D keypoints are category-level semantic consistent points on 3D objects. Detecting 3D semantic keypoints is a foundation for a number of 3D vision tasks but remains challenging, due to the ambiguity of semantic information, especially when the objects are represented by unordered 3D point clouds. Existing unsupervised methods tend to generate category-level keypoints in implicit manners, making it difficult to extract high-level information, such as semantic labels and topology. From a novel mutual reconstruction perspective, we present an unsupervised method to generate consistent semantic keypoints from point clouds explicitly. To achieve this, the proposed model predicts keypoints that not only reconstruct the object itself but also reconstruct other instances in the same category. To the best of our knowledge, the proposed method is the first to mine 3D semantic consistent keypoints from a mutual reconstruction view. Experiments under various evaluation metrics as well as comparisons with the state-of-the-arts demonstrate the efficacy of our new solution to mining semantic consistent keypoints with mutual reconstruction.