 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACT: A Simple and Efficient Framework for Active Finetuning
Jun 01, 2026The main goal of active finetuning is to improve a pretrained model's performance on a specific task or domain by finetuning it with carefully selected informative or challenging data. Previous research has predominantly focused on the active aspect (i.e., data selection) while uniformly employing full finetuning for model adaptation, which inevitably distorts pretrained features due to distribution shift. This issue becomes particularly pronounced when the model size is large relative to the finetuning data quantity, leading to heightened overfitting risks. To address this critical gap, we formally outline the FiAF task that emphasizes systematic exploration of finetuning methodologies in active learning. We propose FACT, a three-phase hierarchical finetuning framework featuring both efficiency and simplicity, specifically designed for active finetuning scenarios. Our comprehensive experiments span: (1) Three major dataset categories encompassing classic (CIFAR10, CIFAR100, ImageNet-1k), imbalanced (CIFAR10-LT, CIFAR100-LT), and fine-grained (StanfordCars, FGVCAircraft) image classification datasets, each evaluated under 3-5 distinct sampling ratios; (2) Diverse pretrained architectures including Convolutional Neural Network (ConvNeXt), Vision Transformer (ViT), and Vision LSTM (ViL) networks; (3) A systematic investigation of frozen feature augmentation (FroFA) strategies. (4) A comprehensive and rigorous analysis of efficiency and generalizability. The results demonstrate significant improvements with strong generalization and robustness. Notably, under low sampling ratios, our framework achieves remarkable performance gains of over 20% on the ViT model for CIFAR10, CIFAR100, and ImageNet-1k benchmarks. This systematic approach establishes new state-of-the-art performance while maintaining parameter efficiency, proving particularly effective when labeled data is scarce.
Reasoning-Driven Anomaly Detection and Localization with Image-Level Supervision
Mar 28, 2026Multimodal large language models (MLLMs) have recently demonstrated remarkable reasoning and perceptual abilities for anomaly detection. However, most approaches remain confined to image-level anomaly detection and textual reasoning, while pixel-level localization still relies on external vision modules and dense annotations. In this work, we activate the intrinsic reasoning potential of MLLMs to perform anomaly detection, pixel-level localization, and interpretable reasoning solely from image-level supervision, without any auxiliary components or pixel-wise labels. Specifically, we propose Reasoning-Driven Anomaly Localization (ReAL), which extracts anomaly-related tokens from the autoregressive reasoning process and aggregates their attention responses to produce pixel-level anomaly maps. We further introduce a Consistency-Guided Reasoning Optimization (CGRO) module that leverages reinforcement learning to align reasoning tokens with visual attentions, resulting in more coherent reasoning and accurate anomaly localization. Extensive experiments on four public benchmarks demonstrate that our method significantly improves anomaly detection, localization, and interpretability. Remarkably, despite relying solely on image-level supervision, our approach achieves performance competitive with MLLM-based methods trained under dense pixel-level supervision. Code is available at https://github.com/YizhouJin313/ReADL.
Uni-MDTrack: Learning Decoupled Memory and Dynamic States for Parameter-Efficient Visual Tracking in All Modality
Mar 15, 2026With the advent of Transformer-based one-stream trackers that possess strong capability in inter-frame relation modeling, recent research has increasingly focused on how to introduce spatio-temporal context. However, most existing methods rely on a limited number of historical frames, which not only leads to insufficient utilization of the context, but also inevitably increases the length of input and incurs prohibitive computational overhead. Methods that query an external memory bank, on the other hand, suffer from inadequate fusion between the retrieved spatio-temporal features and the backbone. Moreover, using discrete historical frames as context overlooks the rich dynamics of the target. To address the issues, we propose Uni-MDTrack, which consists of two core components: Memory-Aware Compression Prompt (MCP) module and Dynamic State Fusion (DSF) module. MCP effectively compresses rich memory features into memory-aware prompt tokens, which deeply interact with the input throughout the entire backbone, significantly enhancing the performance while maintaining a stable computational load. DSF complements the discrete memory by capturing the continuous dynamic, progressively introducing the updated dynamic state features from shallow to deep layers, while also preserving high efficiency. Uni-MDTrack also supports unified tracking across RGB, RGB-D/T/E, and RGB-Language modalities. Experiments show that in Uni-MDTrack, training only the MCP, DSF, and prediction head, keeping the proportion of trainable parameters around 30%, yields substantial performance gains, achieves state-of-the-art results on 10 datasets spanning five modalities. Furthermore, both MCP and DSF exhibit excellent generality, functioning as plug-and-play components that can boost the performance of various baseline trackers, while significantly outperforming existing parameter-efficient training approaches.
ResWorld: Temporal Residual World Model for End-to-End Autonomous Driving
Feb 11, 2026The comprehensive understanding capabilities of world models for driving scenarios have significantly improved the planning accuracy of end-to-end autonomous driving frameworks. However, the redundant modeling of static regions and the lack of deep interaction with trajectories hinder world models from exerting their full effectiveness. In this paper, we propose Temporal Residual World Model (TR-World), which focuses on dynamic object modeling. By calculating the temporal residuals of scene representations, the information of dynamic objects can be extracted without relying on detection and tracking. TR-World takes only temporal residuals as input, thus predicting the future spatial distribution of dynamic objects more precisely. By combining the prediction with the static object information contained in the current BEV features, accurate future BEV features can be obtained. Furthermore, we propose Future-Guided Trajectory Refinement (FGTR) module, which conducts interaction between prior trajectories (predicted from the current scene representation) and the future BEV features. This module can not only utilize future road conditions to refine trajectories, but also provides sparse spatial-temporal supervision on future BEV features to prevent world model collapse. Comprehensive experiments conducted on the nuScenes and NAVSIM datasets demonstrate that our method, namely ResWorld, achieves state-of-the-art planning performance. The code is available at https://github.com/mengtan00/ResWorld.git.
LIBERO-X: Robustness Litmus for Vision-Language-Action Models
Feb 06, 2026Reliable benchmarking is critical for advancing Vision-Language-Action (VLA) models, as it reveals their generalization, robustness, and alignment of perception with language-driven manipulation tasks. However, existing benchmarks often provide limited or misleading assessments due to insufficient evaluation protocols that inadequately capture real-world distribution shifts. This work systematically rethinks VLA benchmarking from both evaluation and data perspectives, introducing LIBERO-X, a benchmark featuring: 1) A hierarchical evaluation protocol with progressive difficulty levels targeting three core capabilities: spatial generalization, object recognition, and task instruction understanding. This design enables fine-grained analysis of performance degradation under increasing environmental and task complexity; 2) A high-diversity training dataset collected via human teleoperation, where each scene supports multiple fine-grained manipulation objectives to bridge the train-evaluation distribution gap. Experiments with representative VLA models reveal significant performance drops under cumulative perturbations, exposing persistent limitations in scene comprehension and instruction grounding. By integrating hierarchical evaluation with diverse training data, LIBERO-X offers a more reliable foundation for assessing and advancing VLA development.
Beyond Open Vocabulary: Multimodal Prompting for Object Detection in Remote Sensing Images
Feb 02, 2026Open-vocabulary object detection in remote sensing commonly relies on text-only prompting to specify target categories, implicitly assuming that inference-time category queries can be reliably grounded through pretraining-induced text-visual alignment. In practice, this assumption often breaks down in remote sensing scenarios due to task- and application-specific category semantics, resulting in unstable category specification under open-vocabulary settings. To address this limitation, we propose RS-MPOD, a multimodal open-vocabulary detection framework that reformulates category specification beyond text-only prompting by incorporating instance-grounded visual prompts, textual prompts, and their multimodal integration. RS-MPOD introduces a visual prompt encoder to extract appearance-based category cues from exemplar instances, enabling text-free category specification, and a multimodal fusion module to integrate visual and textual information when both modalities are available. Extensive experiments on standard, cross-dataset, and fine-grained remote sensing benchmarks show that visual prompting yields more reliable category specification under semantic ambiguity and distribution shifts, while multimodal prompting provides a flexible alternative that remains competitive when textual semantics are well aligned.
EntroCut: Entropy-Guided Adaptive Truncation for Efficient Chain-of-Thought Reasoning in Small-scale Large Reasoning Models
Jan 30, 2026Large Reasoning Models (LRMs) excel at complex reasoning tasks through extended chain-of-thought generation, but their reliance on lengthy intermediate steps incurs substantial computational cost. We find that the entropy of the model's output distribution in early reasoning steps reliably distinguishes correct from incorrect reasoning. Motivated by this observation, we propose EntroCut, a training-free method that dynamically truncates reasoning by identifying high-confidence states where reasoning can be safely terminated. To comprehensively evaluate the trade-off between efficiency and accuracy, we introduce the Efficiency-Performance Ratio (EPR), a unified metric that quantifies relative token savings per unit accuracy loss. Experiments on four benchmarks show that EntroCut reduces token usage by up to 40\% with minimal accuracy sacrifice, achieving superior efficiency-performance trade-offs compared with existing training-free methods. These results demonstrate that entropy-guided dynamic truncation provides a practical approach to mitigate the inefficiency of LRMs.
Learn More, Forget Less: A Gradient-Aware Data Selection Approach for LLM
Nov 07, 2025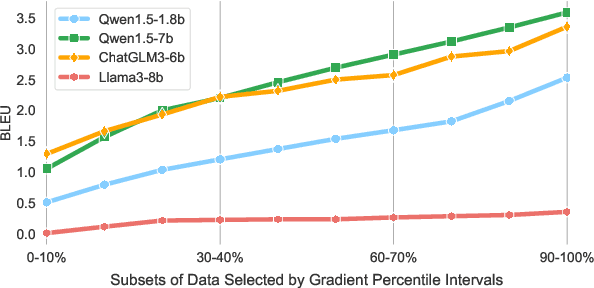
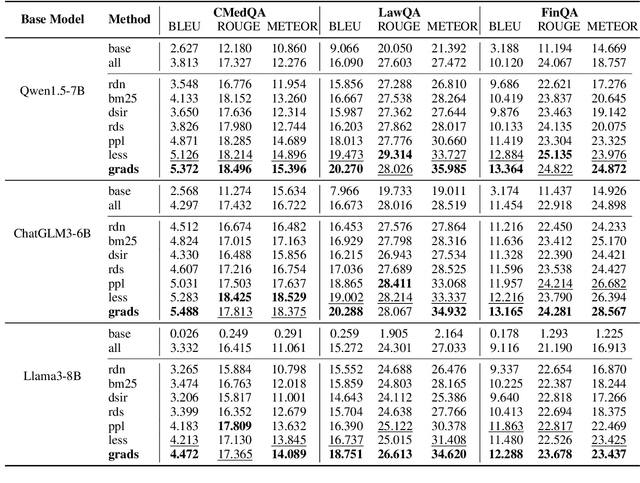
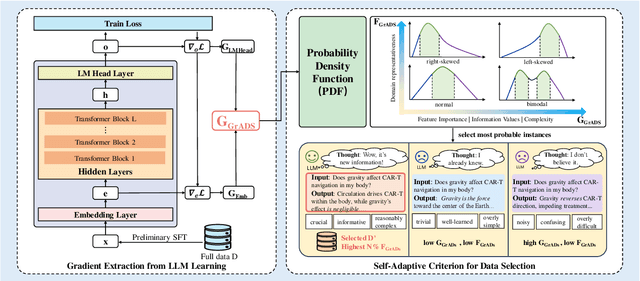
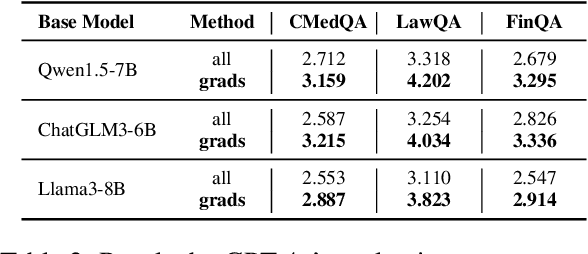
Despite large language models (LLMs) have achieved impressive achievements across numerous tasks, supervised fine-tuning (SFT) remains essential for adapting these models to specialized domains. However, SFT for domain specialization can be resource-intensive and sometimes leads to a deterioration in performance over general capabilities due to catastrophic forgetting (CF). To address these issues, we propose a self-adaptive gradient-aware data selection approach (GrADS) for supervised fine-tuning of LLMs, which identifies effective subsets of training data by analyzing gradients obtained from a preliminary training phase. Specifically, we design self-guided criteria that leverage the magnitude and statistical distribution of gradients to prioritize examples that contribute the most to the model's learning process. This approach enables the acquisition of representative samples that enhance LLMs understanding of domain-specific tasks. Through extensive experimentation with various LLMs across diverse domains such as medicine, law, and finance, GrADS has demonstrated significant efficiency and cost-effectiveness. Remarkably, utilizing merely 5% of the selected GrADS data, LLMs already surpass the performance of those fine-tuned on the entire dataset, and increasing to 50% of the data results in significant improvements! With catastrophic forgetting substantially mitigated simultaneously. We will release our code for GrADS later.
SeeDNorm: Self-Rescaled Dynamic Normalization
Oct 26, 2025Normalization layer constitutes an essential component in neural networks. In transformers, the predominantly used RMSNorm constrains vectors to a unit hypersphere, followed by dimension-wise rescaling through a learnable scaling coefficient $\gamma$ to maintain the representational capacity of the model. However, RMSNorm discards the input norm information in forward pass and a static scaling factor $\gamma$ may be insufficient to accommodate the wide variability of input data and distributional shifts, thereby limiting further performance improvements, particularly in zero-shot scenarios that large language models routinely encounter. To address this limitation, we propose SeeDNorm, which enhances the representational capability of the model by dynamically adjusting the scaling coefficient based on the current input, thereby preserving the input norm information and enabling data-dependent, self-rescaled dynamic normalization. During backpropagation, SeeDNorm retains the ability of RMSNorm to dynamically adjust gradient according to the input norm. We provide a detailed analysis of the training optimization for SeedNorm and proposed corresponding solutions to address potential instability issues that may arise when applying SeeDNorm. We validate the effectiveness of SeeDNorm across models of varying sizes in large language model pre-training as well as supervised and unsupervised computer vision tasks. By introducing a minimal number of parameters and with neglligible impact on model efficiency, SeeDNorm achieves consistently superior performance compared to previously commonly used normalization layers such as RMSNorm and LayerNorm, as well as element-wise activation alternatives to normalization layers like DyT.
ContextQFormer: A New Context Modeling Method for Multi-Turn Multi-Modal Conversations
May 29, 2025


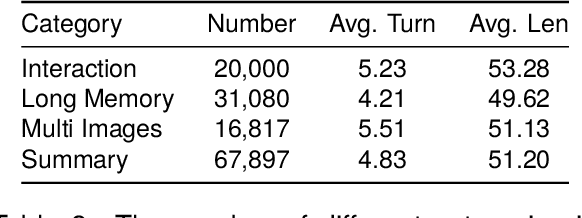
Multi-modal large language models have demonstrated remarkable zero-shot abilities and powerful image-understanding capabilities. However, the existing open-source multi-modal models suffer from the weak capability of multi-turn interaction, especially for long contexts. To address the issue, we first introduce a context modeling module, termed ContextQFormer, which utilizes a memory block to enhance the presentation of contextual information. Furthermore, to facilitate further research, we carefully build a new multi-turn multi-modal dialogue dataset (TMDialog) for pre-training, instruction-tuning, and evaluation, which will be open-sourced lately. Compared with other multi-modal dialogue datasets, TMDialog contains longer conversations, which supports the research of multi-turn multi-modal dialogue. In addition, ContextQFormer is compared with three baselines on TMDialog and experimental results illustrate that ContextQFormer achieves an improvement of 2%-4% in available rate over baselines.