 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIVA-GRPO: Enhancing Multimodal Reasoning through Difficulty-Adaptive Variant Advantage
Mar 01, 2026Reinforcement learning (RL) with group relative policy optimization (GRPO) has become a widely adopted approach for enhancing the reasoning capabilities of multimodal large language models (MLLMs). While GRPO enables long-chain reasoning without a critic, it often suffers from sparse rewards on difficult problems and advantage vanishing when group-level rewards are too consistent for overly easy or hard problems. Existing solutions (sample expansion, selective utilization, and indirect reward design) often fail to maintain enough variance in within-group reward distributions to yield clear optimization signals. To address this, we propose DIVA-GRPO, a difficulty-adaptive variant advantage method that adjusts variant difficulty distributions from a global perspective. DIVA-GRPO dynamically assesses problem difficulty, samples variants with appropriate difficulty levels, and calculates advantages across local and global groups using difficulty-weighted and normalized scaling. This alleviates reward sparsity and advantage vanishing while improving training stability. Extensive experiments on six reasoning benchmarks demonstrate that DIVA-GRPO outperforms existing approaches in training efficiency and reasoning performance. Code: https://github.com/Siaaaaaa1/DIVA-GRPO
QARM V2: Quantitative Alignment Multi-Modal Recommendation for Reasoning User Sequence Modeling
Feb 09, 2026With the evolution of large language models (LLMs), there is growing interest in leveraging their rich semantic understanding to enhance industrial recommendation systems (RecSys). Traditional RecSys relies on ID-based embeddings for user sequence modeling in the General Search Unit (GSU) and Exact Search Unit (ESU) paradigm, which suffers from low information density, knowledge isolation, and weak generalization ability. While LLMs offer complementary strengths with dense semantic representations and strong generalization, directly applying LLM embeddings to RecSys faces critical challenges: representation unmatch with business objectives and representation unlearning end-to-end with downstream tasks. In this paper, we present QARM V2, a unified framework that bridges LLM semantic understanding with RecSys business requirements for user sequence modeling.
OneMall: One Architecture, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Feb 02, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
OneMall: One Model, More Scenarios -- End-to-End Generative Recommender Family at Kuaishou E-Commerce
Jan 29, 2026In the wave of generative recommendation, we present OneMall, an end-to-end generative recommendation framework tailored for e-commerce services at Kuaishou. Our OneMall systematically unifies the e-commerce's multiple item distribution scenarios, such as Product-card, short-video and live-streaming. Specifically, it comprises three key components, aligning the entire model training pipeline to the LLM's pre-training/post-training: (1) E-commerce Semantic Tokenizer: we provide a tokenizer solution that captures both real-world semantics and business-specific item relations across different scenarios; (2) Transformer-based Architecture: we largely utilize Transformer as our model backbone, e.g., employing Query-Former for long sequence compression, Cross-Attention for multi-behavior sequence fusion, and Sparse MoE for scalable auto-regressive generation; (3) Reinforcement Learning Pipeline: we further connect retrieval and ranking models via RL, enabling the ranking model to serve as a reward signal for end-to-end policy retrieval model optimization. Extensive experiments demonstrate that OneMall achieves consistent improvements across all e-commerce scenarios: +13.01\% GMV in product-card, +15.32\% Orders in Short-Video, and +2.78\% Orders in Live-Streaming. OneMall has been deployed, serving over 400 million daily active users at Kuaishou.
ContextQFormer: A New Context Modeling Method for Multi-Turn Multi-Modal Conversations
May 29, 2025


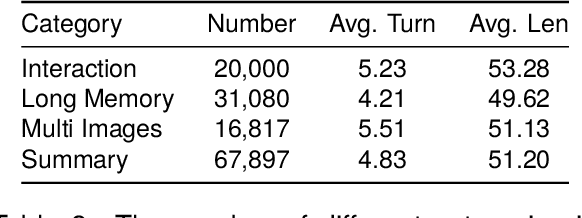
Multi-modal large language models have demonstrated remarkable zero-shot abilities and powerful image-understanding capabilities. However, the existing open-source multi-modal models suffer from the weak capability of multi-turn interaction, especially for long contexts. To address the issue, we first introduce a context modeling module, termed ContextQFormer, which utilizes a memory block to enhance the presentation of contextual information. Furthermore, to facilitate further research, we carefully build a new multi-turn multi-modal dialogue dataset (TMDialog) for pre-training, instruction-tuning, and evaluation, which will be open-sourced lately. Compared with other multi-modal dialogue datasets, TMDialog contains longer conversations, which supports the research of multi-turn multi-modal dialogue. In addition, ContextQFormer is compared with three baselines on TMDialog and experimental results illustrate that ContextQFormer achieves an improvement of 2%-4% in available rate over baselines.
GODBench: A Benchmark for Multimodal Large Language Models in Video Comment Art
May 16, 2025Video Comment Art enhances user engagement by providing creative content that conveys humor, satire, or emotional resonance, requiring a nuanced and comprehensive grasp of cultural and contextual subtleties. Although Multimodal Large Language Models (MLLMs) and Chain-of-Thought (CoT) have demonstrated strong reasoning abilities in STEM tasks (e.g. mathematics and coding), they still struggle to generate creative expressions such as resonant jokes and insightful satire. Moreover, existing benchmarks are constrained by their limited modalities and insufficient categories, hindering the exploration of comprehensive creativity in video-based Comment Art creation. To address these limitations, we introduce GODBench, a novel benchmark that integrates video and text modalities to systematically evaluate MLLMs' abilities to compose Comment Art. Furthermore, inspired by the propagation patterns of waves in physics, we propose Ripple of Thought (RoT), a multi-step reasoning framework designed to enhance the creativity of MLLMs. Extensive experiments reveal that existing MLLMs and CoT methods still face significant challenges in understanding and generating creative video comments. In contrast, RoT provides an effective approach to improve creative composing, highlighting its potential to drive meaningful advancements in MLLM-based creativity. GODBench is publicly available at https://github.com/stan-lei/GODBench-ACL2025.
KwaiChat: A Large-Scale Video-Driven Multilingual Mixed-Type Dialogue Corpus
Mar 10, 2025Video-based dialogue systems, such as education assistants, have compelling application value, thereby garnering growing interest. However, the current video-based dialogue systems are limited by their reliance on a single dialogue type, which hinders their versatility in practical applications across a range of scenarios, including question-answering, emotional dialog, etc. In this paper, we identify this challenge as how to generate video-driven multilingual mixed-type dialogues. To mitigate this challenge, we propose a novel task and create a human-to-human video-driven multilingual mixed-type dialogue corpus, termed KwaiChat, containing a total of 93,209 videos and 246,080 dialogues, across 4 dialogue types, 30 domains, 4 languages, and 13 topics. Additionally, we establish baseline models on KwaiChat. An extensive analysis of 7 distinct LLMs on KwaiChat reveals that GPT-4o achieves the best performance but still cannot perform well in this situation even with the help of in-context learning and fine-tuning, which indicates that the task is not trivial and needs further research.
Reliable Imputed-Sample Assisted Vertical Federated Learning
Jan 11, 2025Vertical Federated Learning (VFL) is a well-known FL variant that enables multiple parties to collaboratively train a model without sharing their raw data. Existing VFL approaches focus on overlapping samples among different parties, while their performance is constrained by the limited number of these samples, leaving numerous non-overlapping samples unexplored. Some previous work has explored techniques for imputing missing values in samples, but often without adequate attention to the quality of the imputed samples. To address this issue, we propose a Reliable Imputed-Sample Assisted (RISA) VFL framework to effectively exploit non-overlapping samples by selecting reliable imputed samples for training VFL models. Specifically, after imputing non-overlapping samples, we introduce evidence theory to estimate the uncertainty of imputed samples, and only samples with low uncertainty are selected. In this way, high-quality non-overlapping samples are utilized to improve VFL model. Experiments on two widely used datasets demonstrate the significant performance gains achieved by the RISA, especially with the limited overlapping samples, e.g., a 48% accuracy gain on CIFAR-10 with only 1% overlapping samples.
AnchorGT: Efficient and Flexible Attention Architecture for Scalable Graph Transformers
May 06, 2024



Graph Transformers (GTs) have significantly advanced the field of graph representation learning by overcoming the limitations of message-passing graph neural networks (GNNs) and demonstrating promising performance and expressive power. However, the quadratic complexity of self-attention mechanism in GTs has limited their scalability, and previous approaches to address this issue often suffer from expressiveness degradation or lack of versatility. To address this issue, we propose AnchorGT, a novel attention architecture for GTs with global receptive field and almost linear complexity, which serves as a flexible building block to improve the scalability of a wide range of GT models. Inspired by anchor-based GNNs, we employ structurally important $k$-dominating node set as anchors and design an attention mechanism that focuses on the relationship between individual nodes and anchors, while retaining the global receptive field for all nodes. With its intuitive design, AnchorGT can easily replace the attention module in various GT models with different network architectures and structural encodings, resulting in reduced computational overhead without sacrificing performance. In addition, we theoretically prove that AnchorGT attention can be strictly more expressive than Weisfeiler-Lehman test, showing its superiority in representing graph structures. Our experiments on three state-of-the-art GT models demonstrate that their AnchorGT variants can achieve better results while being faster and significantly more memory efficient.
FedAds: A Benchmark for Privacy-Preserving CVR Estimation with Vertical Federated Learning
May 15, 2023



Conversion rate (CVR) estimation aims to predict the probability of conversion event after a user has clicked an ad. Typically, online publisher has user browsing interests and click feedbacks, while demand-side advertising platform collects users' post-click behaviors such as dwell time and conversion decisions. To estimate CVR accurately and protect data privacy better, vertical federated learning (vFL) is a natural solution to combine two sides' advantages for training models, without exchanging raw data. Both CVR estimation and applied vFL algorithms have attracted increasing research attentions. However, standardized and systematical evaluations are missing: due to the lack of standardized datasets, existing studies adopt public datasets to simulate a vFL setting via hand-crafted feature partition, which brings challenges to fair comparison. We introduce FedAds, the first benchmark for CVR estimation with vFL, to facilitate standardized and systematical evaluations for vFL algorithms. It contains a large-scale real world dataset collected from Alibaba's advertising platform, as well as systematical evaluations for both effectiveness and privacy aspects of various vFL algorithms. Besides, we also explore to incorporate unaligned data in vFL to improve effectiveness, and develop perturbation operations to protect privacy well. We hope that future research work in vFL and CVR estimation benefits from the FedAds benchmark.