 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient LLM-based Advertising via Model Compression and Parallel Verification
May 12, 2026Large language models (LLMs) have shown remarkable potential in advertising scenarios such as ad creative generation and targeted advertising. However, deploying LLMs in real-time advertising systems poses significant challenges due to their high inference latency and computational cost. In this paper, we propose an Efficient Generative Targeting framework that integrates adaptive group quantization, layer-adaptive hierarchical sparsification, and prefix-tree parallel verification to accelerate LLM inference while preserving generation quality. Extensive experiments on two real-world advertising scenarios demonstrate that our framework achieves significant speedup with acceptable quality degradation, making it operationally viable for practical deployments.
FedAds: A Benchmark for Privacy-Preserving CVR Estimation with Vertical Federated Learning
May 15, 2023



Conversion rate (CVR) estimation aims to predict the probability of conversion event after a user has clicked an ad. Typically, online publisher has user browsing interests and click feedbacks, while demand-side advertising platform collects users' post-click behaviors such as dwell time and conversion decisions. To estimate CVR accurately and protect data privacy better, vertical federated learning (vFL) is a natural solution to combine two sides' advantages for training models, without exchanging raw data. Both CVR estimation and applied vFL algorithms have attracted increasing research attentions. However, standardized and systematical evaluations are missing: due to the lack of standardized datasets, existing studies adopt public datasets to simulate a vFL setting via hand-crafted feature partition, which brings challenges to fair comparison. We introduce FedAds, the first benchmark for CVR estimation with vFL, to facilitate standardized and systematical evaluations for vFL algorithms. It contains a large-scale real world dataset collected from Alibaba's advertising platform, as well as systematical evaluations for both effectiveness and privacy aspects of various vFL algorithms. Besides, we also explore to incorporate unaligned data in vFL to improve effectiveness, and develop perturbation operations to protect privacy well. We hope that future research work in vFL and CVR estimation benefits from the FedAds benchmark.
Hybrid Contrastive Constraints for Multi-Scenario Ad Ranking
Feb 06, 2023Multi-scenario ad ranking aims at leveraging the data from multiple domains or channels for training a unified ranking model to improve the performance at each individual scenario. Although the research on this task has made important progress, it still lacks the consideration of cross-scenario relations, thus leading to limitation in learning capability and difficulty in interrelation modeling. In this paper, we propose a Hybrid Contrastive Constrained approach (HC^2) for multi-scenario ad ranking. To enhance the modeling of data interrelation, we elaborately design a hybrid contrastive learning approach to capture commonalities and differences among multiple scenarios. The core of our approach consists of two elaborated contrastive losses, namely generalized and individual contrastive loss, which aim at capturing common knowledge and scenario-specific knowledge, respectively. To adapt contrastive learning to the complex multi-scenario setting, we propose a series of important improvements. For generalized contrastive loss, we enhance contrastive learning by extending the contrastive samples (label-aware and diffusion noise enhanced contrastive samples) and reweighting the contrastive samples (reciprocal similarity weighting). For individual contrastive loss, we use the strategies of dropout-based augmentation and {cross-scenario encoding} for generating meaningful positive and negative contrastive samples, respectively. Extensive experiments on both offline evaluation and online test have demonstrated the effectiveness of the proposed HC$^2$ by comparing it with a number of competitive baselines.
RLTP: Reinforcement Learning to Pace for Delayed Impression Modeling in Preloaded Ads
Feb 06, 2023

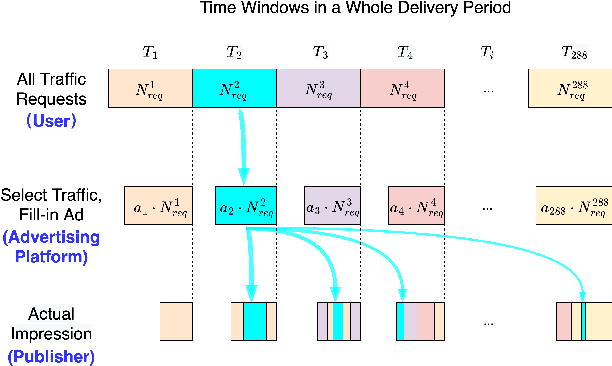

To increase brand awareness, many advertisers conclude contracts with advertising platforms to purchase traffic and then deliver advertisements to target audiences. In a whole delivery period, advertisers usually desire a certain impression count for the ads, and they also expect that the delivery performance is as good as possible (e.g., obtaining high click-through rate). Advertising platforms employ pacing algorithms to satisfy the demands via adjusting the selection probabilities to traffic requests in real-time. However, the delivery procedure is also affected by the strategies from publishers, which cannot be controlled by advertising platforms. Preloading is a widely used strategy for many types of ads (e.g., video ads) to make sure that the response time for displaying after a traffic request is legitimate, which results in delayed impression phenomenon. Traditional pacing algorithms cannot handle the preloading nature well because they rely on immediate feedback signals, and may fail to guarantee the demands from advertisers. In this paper, we focus on a new research problem of impression pacing for preloaded ads, and propose a Reinforcement Learning To Pace framework RLTP. It learns a pacing agent that sequentially produces selection probabilities in the whole delivery period. To jointly optimize the two objectives of impression count and delivery performance, RLTP employs tailored reward estimator to satisfy the guaranteed impression count, penalize the over-delivery and maximize the traffic value. Experiments on large-scale industrial datasets verify that RLTP outperforms baseline pacing algorithms by a large margin. We have deployed the RLTP framework online to our advertising platform, and results show that it achieves significant uplift to core metrics including delivery completion rate and click-through rate.
Correlative Preference Transfer with Hierarchical Hypergraph Network for Multi-Domain Recommendation
Nov 21, 2022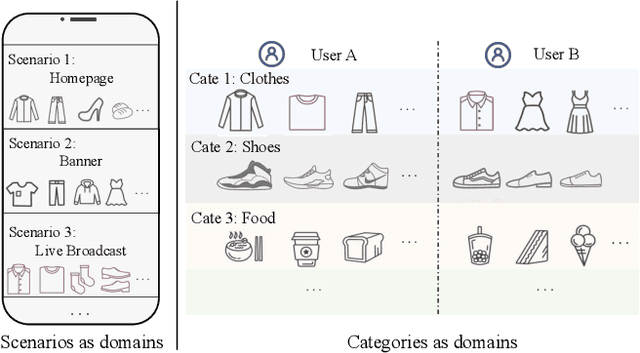



Advanced recommender systems usually involve multiple domains (scenarios or categories) for various marketing strategies, and users interact with them to satisfy their diverse demands. The goal of multi-domain recommendation is to improve the recommendation performance of all domains simultaneously. Conventional graph neural network based methods usually deal with each domain separately, or train a shared model for serving all domains. The former fails to leverage users' cross-domain behaviors, making the behavior sparseness issue a great obstacle. The latter learns shared user representation with respect to all domains, which neglects users' domain-specific preferences. These shortcomings greatly limit their performance in multi-domain recommendation. To tackle the limitations, an appropriate way is to learn from multi-domain user feedbacks and obtain separate user representations to characterize their domain-specific preferences. In this paper we propose $\mathsf{H^3Trans}$, a hierarchical hypergraph network based correlative preference transfer framework for multi-domain recommendation. $\mathsf{H^3Trans}$ represents multi-domain feedbacks into a unified graph to help preference transfer via taking full advantage of users' multi-domain behaviors. We incorporate two hyperedge-based modules, namely dynamic item transfer module (Hyper-I) and adaptive user aggregation module (Hyper-U). Hyper-I extracts correlative information from multi-domain user-item feedbacks for eliminating domain discrepancy of item representations. Hyper-U aggregates users' scattered preferences in multiple domains and further exploits the high-order (not only pair-wise) connections among them to learn user representations. Experimental results on both public datasets and large-scale production datasets verify the superiority of $\mathsf{H^3Trans}$ for multi-domain recommendation.
AdaSparse: Learning Adaptively Sparse Structures for Multi-Domain Click-Through Rate Prediction
Jul 01, 2022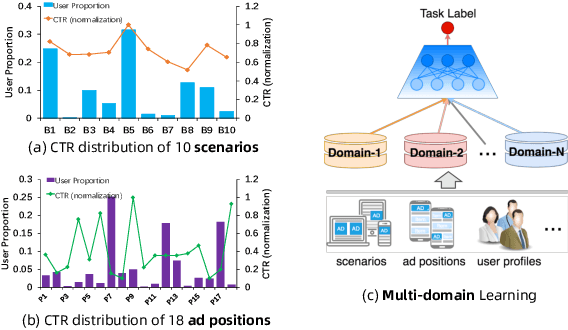
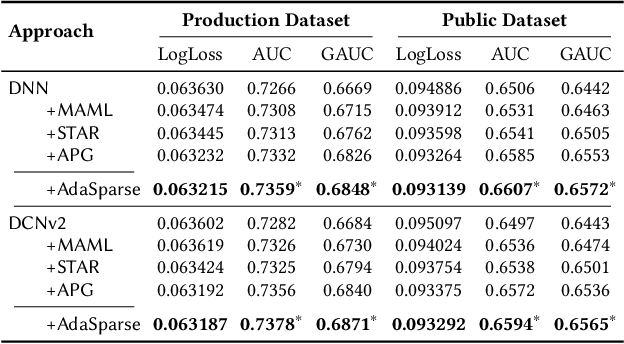
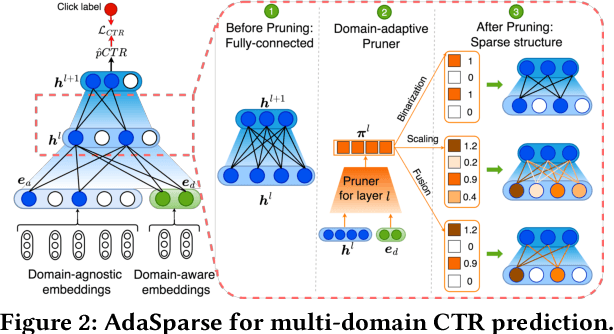
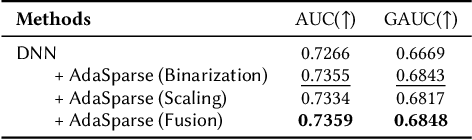
Click-through rate (CTR) prediction is a fundamental technique in recommendation and advertising systems. Recent studies have proved that learning a unified model to serve multiple domains is effective to improve the overall performance. However, it is still challenging to improve generalization across domains under limited training data, and hard to deploy current solutions due to their computational complexity. In this paper, we propose a simple yet effective framework AdaSparse for multi-domain CTR prediction, which learns adaptively sparse structure for each domain, achieving better generalization across domains with lower computational cost. In AdaSparse, we introduce domain-aware neuron-level weighting factors to measure the importance of neurons, with that for each domain our model can prune redundant neurons to improve generalization. We further add flexible sparsity regularizations to control the sparsity ratio of learned structures. Offline and online experiments show that AdaSparse outperforms previous multi-domain CTR models significantly.
Towards Personalized Bundle Creative Generation with Contrastive Non-Autoregressive Decoding
Jun 09, 2022
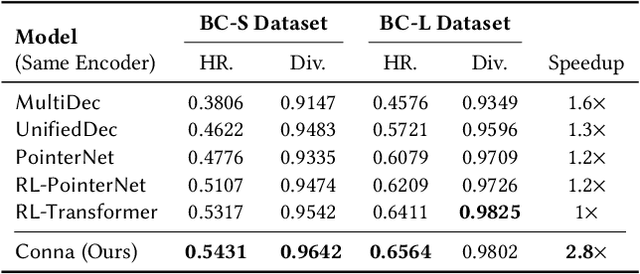
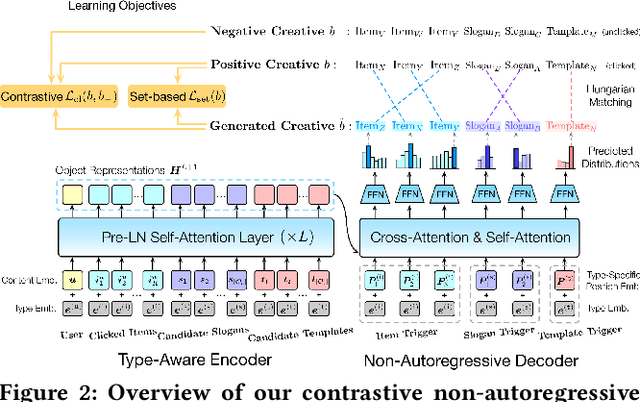
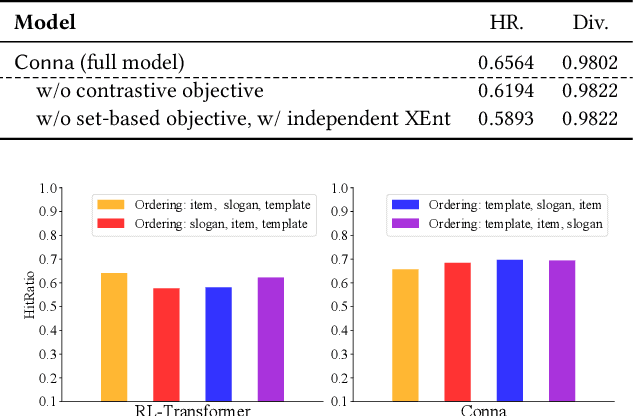
Current bundle generation studies focus on generating a combination of items to improve user experience. In real-world applications, there is also a great need to produce bundle creatives that consist of mixture types of objects (e.g., items, slogans and templates) for achieving better promotion effect. We study a new problem named bundle creative generation: for given users, the goal is to generate personalized bundle creatives that the users will be interested in. To take both quality and efficiency into account, we propose a contrastive non-autoregressive model that captures user preferences with ingenious decoding objective. Experiments on large-scale real-world datasets verify that our proposed model shows significant advantages in terms of creative quality and generation speed.
CREATER: CTR-driven Advertising Text Generation with Controlled Pre-Training and Contrastive Fine-Tuning
May 18, 2022

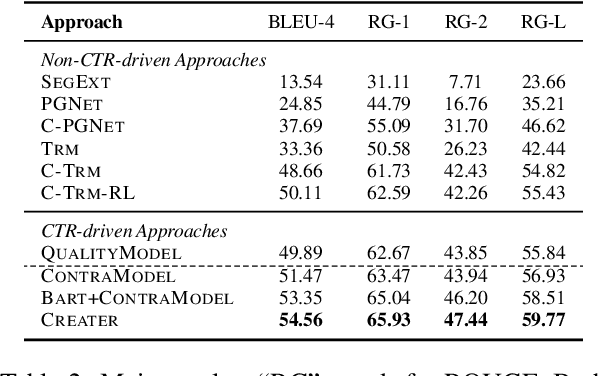

This paper focuses on automatically generating the text of an ad, and the goal is that the generated text can capture user interest for achieving higher click-through rate (CTR). We propose CREATER, a CTR-driven advertising text generation approach, to generate ad texts based on high-quality user reviews. To incorporate CTR objective, our model learns from online A/B test data with contrastive learning, which encourages the model to generate ad texts that obtain higher CTR. To alleviate the low-resource issue, we design a customized self-supervised objective reducing the gap between pre-training and fine-tuning. Experiments on industrial datasets show that CREATER significantly outperforms current approaches. It has been deployed online in a leading advertising platform and brings uplift on core online metrics.
Posterior Probability Matters: Doubly-Adaptive Calibration for Neural Predictions in Online Advertising
May 15, 2022
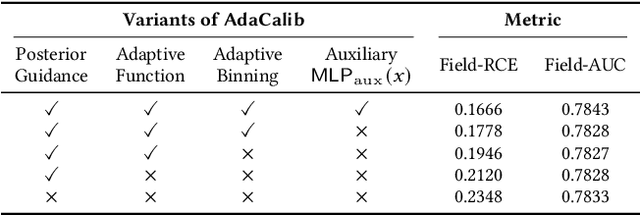
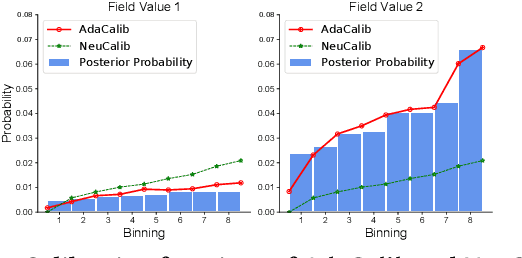
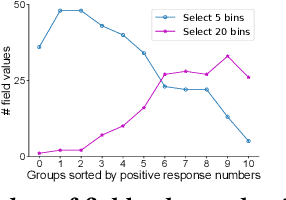
Predicting user response probabilities is vital for ad ranking and bidding. We hope that predictive models can produce accurate probabilistic predictions that reflect true likelihoods. Calibration techniques aims to post-process model predictions to posterior probabilities. Field-level calibration -- which performs calibration w.r.t. to a specific field value -- is fine-grained and more practical. In this paper we propose a doubly-adaptive approach AdaCalib. It learns an isotonic function family to calibrate model predictions with the guidance of posterior statistics, and field-adaptive mechanisms are designed to ensure that the posterior is appropriate for the field value to be calibrated. Experiments verify that AdaCalib achieves significant improvement on calibration performance. It has been deployed online and beats previous approach.
UKD: Debiasing Conversion Rate Estimation via Uncertainty-regularized Knowledge Distillation
Jan 20, 2022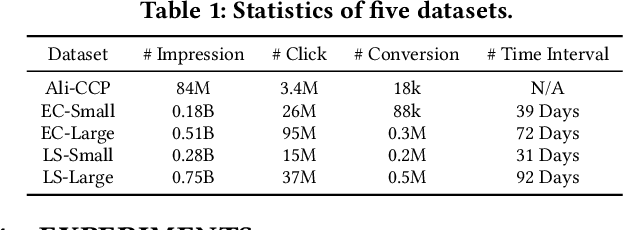

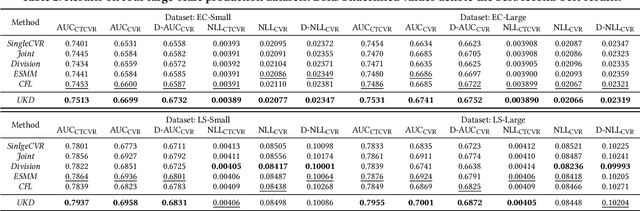

In online advertising, conventional post-click conversion rate (CVR) estimation models are trained using clicked samples. However, during online serving the models need to estimate for all impression ads, leading to the sample selection bias (SSB) issue. Intuitively, providing reliable supervision signals for unclicked ads is a feasible way to alleviate the SSB issue. This paper proposes an uncertainty-regularized knowledge distillation (UKD) framework to debias CVR estimation via distilling knowledge from unclicked ads. A teacher model learns click-adaptive representations and produces pseudo-conversion labels on unclicked ads as supervision signals. Then a student model is trained on both clicked and unclicked ads with knowledge distillation, performing uncertainty modeling to alleviate the inherent noise in pseudo-labels. Experiments on billion-scale datasets show that UKD outperforms previous debiasing methods. Online results verify that UKD achieves significant improvements.