 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLNE-Blocking: An Efficient Framework for Contamination Mitigation Evaluation on Large Language Models
Sep 18, 2025The problem of data contamination is now almost inevitable during the development of large language models (LLMs), with the training data commonly integrating those evaluation benchmarks even unintentionally. This problem subsequently makes it hard to benchmark LLMs fairly. Instead of constructing contamination-free datasets (quite hard), we propose a novel framework, \textbf{LNE-Blocking}, to restore model performance prior to contamination on potentially leaked datasets. Our framework consists of two components: contamination detection and disruption operation. For the prompt, the framework first uses the contamination detection method, \textbf{LNE}, to assess the extent of contamination in the model. Based on this, it adjusts the intensity of the disruption operation, \textbf{Blocking}, to elicit non-memorized responses from the model. Our framework is the first to efficiently restore the model's greedy decoding performance. This comes with a strong performance on multiple datasets with potential leakage risks, and it consistently achieves stable recovery results across different models and varying levels of data contamination. We release the code at https://github.com/RuijieH/LNE-Blocking to facilitate research.
Cross Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction
Dec 11, 2023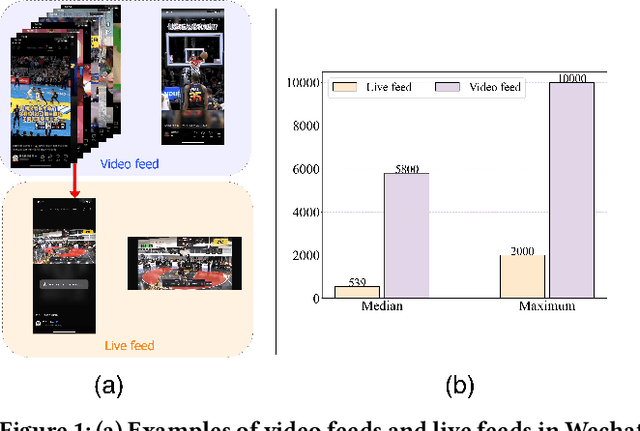

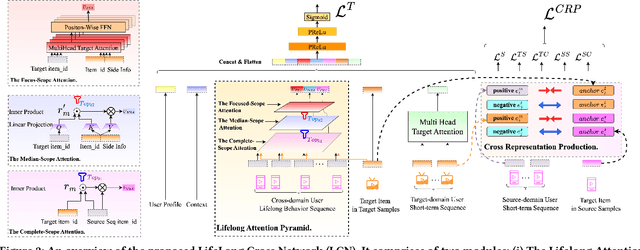
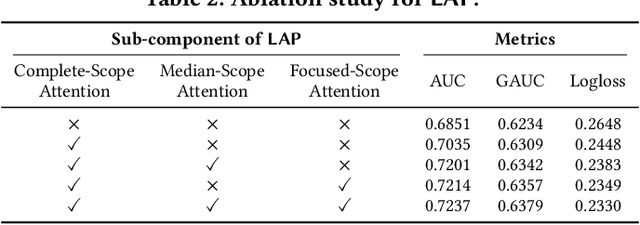
Deep neural networks (DNNs) that incorporated lifelong sequential modeling (LSM) have brought great success to recommendation systems in various social media platforms. While continuous improvements have been made in domain-specific LSM, limited work has been done in cross-domain LSM, which considers modeling of lifelong sequences of both target domain and source domain. In this paper, we propose Lifelong Cross Network (LCN) to incorporate cross-domain LSM to improve the click-through rate (CTR) prediction in the target domain. The proposed LCN contains a LifeLong Attention Pyramid (LAP) module that comprises of three levels of cascaded attentions to effectively extract interest representations with respect to the candidate item from lifelong sequences. We also propose Cross Representation Production (CRP) module to enforce additional supervision on the learning and alignment of cross-domain representations so that they can be better reused on learning of the CTR prediction in the target domain. We conducted extensive experiments on WeChat Channels industrial dataset as well as on benchmark dataset. Results have revealed that the proposed LCN outperforms existing work in terms of both prediction accuracy and online performance.
Shifting Perspective to See Difference: A Novel Multi-View Method for Skeleton based Action Recognition
Sep 07, 2022
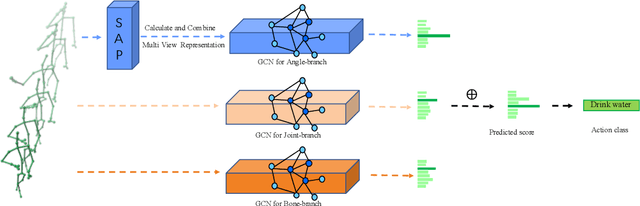

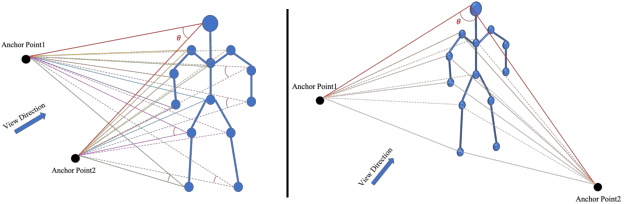
Skeleton-based human action recognition is a longstanding challenge due to its complex dynamics. Some fine-grain details of the dynamics play a vital role in classification. The existing work largely focuses on designing incremental neural networks with more complicated adjacent matrices to capture the details of joints relationships. However, they still have difficulties distinguishing actions that have broadly similar motion patterns but belong to different categories. Interestingly, we found that the subtle differences in motion patterns can be significantly amplified and become easy for audience to distinct through specified view directions, where this property haven't been fully explored before. Drastically different from previous work, we boost the performance by proposing a conceptually simple yet effective Multi-view strategy that recognizes actions from a collection of dynamic view features. Specifically, we design a novel Skeleton-Anchor Proposal (SAP) module which contains a Multi-head structure to learn a set of views. For feature learning of different views, we introduce a novel Angle Representation to transform the actions under different views and feed the transformations into the baseline model. Our module can work seamlessly with the existing action classification model. Incorporated with baseline models, our SAP module exhibits clear performance gains on many challenging benchmarks. Moreover, comprehensive experiments show that our model consistently beats down the state-of-the-art and remains effective and robust especially when dealing with corrupted data. Related code will be available on https://github.com/ideal-idea/SAP .
Posterior Probability Matters: Doubly-Adaptive Calibration for Neural Predictions in Online Advertising
May 15, 2022
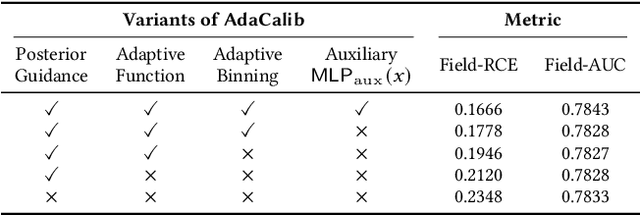
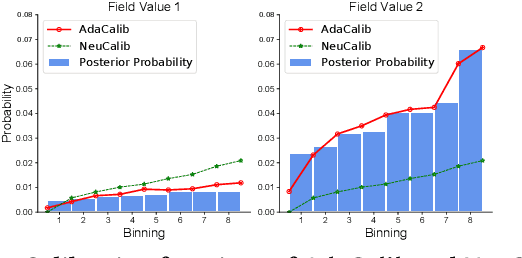
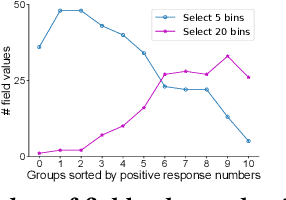
Predicting user response probabilities is vital for ad ranking and bidding. We hope that predictive models can produce accurate probabilistic predictions that reflect true likelihoods. Calibration techniques aims to post-process model predictions to posterior probabilities. Field-level calibration -- which performs calibration w.r.t. to a specific field value -- is fine-grained and more practical. In this paper we propose a doubly-adaptive approach AdaCalib. It learns an isotonic function family to calibrate model predictions with the guidance of posterior statistics, and field-adaptive mechanisms are designed to ensure that the posterior is appropriate for the field value to be calibrated. Experiments verify that AdaCalib achieves significant improvement on calibration performance. It has been deployed online and beats previous approach.
Self-attention based anchor proposal for skeleton-based action recognition
Dec 17, 2021
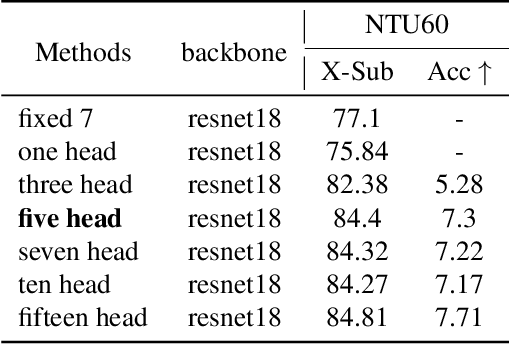


Skeleton sequences are widely used for action recognition task due to its lightweight and compact characteristics. Recent graph convolutional network (GCN) approaches have achieved great success for skeleton-based action recognition since its grateful modeling ability of non-Euclidean data. GCN is able to utilize the short-range joint dependencies while lack to directly model the distant joints relations that are vital to distinguishing various actions. Thus, many GCN approaches try to employ hierarchical mechanism to aggregate wider-range neighborhood information. We propose a novel self-attention based skeleton-anchor proposal (SAP) module to comprehensively model the internal relations of a human body for motion feature learning. The proposed SAP module aims to explore inherent relationship within human body using a triplet representation via encoding high order angle information rather than the fixed pair-wise bone connection used in the existing hierarchical GCN approaches. A Self-attention based anchor selection method is designed in the proposed SAP module for extracting the root point of encoding angular information. By coupling proposed SAP module with popular spatial-temporal graph neural networks, e.g. MSG3D, it achieves new state-of-the-art accuracy on challenging benchmark datasets. Further ablation study have shown the effectiveness of our proposed SAP module, which is able to obviously improve the performance of many popular skeleton-based action recognition methods.