 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRQ-GMM: Residual Quantized Gaussian Mixture Model for Multimodal Semantic Discretization in CTR Prediction
Feb 13, 2026Multimodal content is crucial for click-through rate (CTR) prediction. However, directly incorporating continuous embeddings from pre-trained models into CTR models yields suboptimal results due to misaligned optimization objectives and convergence speed inconsistency during joint training. Discretizing embeddings into semantic IDs before feeding them into CTR models offers a more effective solution, yet existing methods suffer from limited codebook utilization, reconstruction accuracy, and semantic discriminability. We propose RQ-GMM (Residual Quantized Gaussian Mixture Model), which introduces probabilistic modeling to better capture the statistical structure of multimodal embedding spaces. Through Gaussian Mixture Models combined with residual quantization, RQ-GMM achieves superior codebook utilization and reconstruction accuracy. Experiments on public datasets and online A/B tests on a large-scale short-video platform serving hundreds of millions of users demonstrate substantial improvements: RQ-GMM yields a 1.502% gain in Advertiser Value over strong baselines. The method has been fully deployed, serving daily recommendations for hundreds of millions of users.
Distribution-Aware End-to-End Embedding for Streaming Numerical Features in Click-Through Rate Prediction
Feb 03, 2026This paper explores effective numerical feature embedding for Click-Through Rate prediction in streaming environments. Conventional static binning methods rely on offline statistics of numerical distributions; however, this inherently two-stage process often triggers semantic drift during bin boundary updates. While neural embedding methods enable end-to-end learning, they often discard explicit distributional information. Integrating such information end-to-end is challenging because streaming features often violate the i.i.d. assumption, precluding unbiased estimation of the population distribution via the expectation of order statistics. Furthermore, the critical context dependency of numerical distributions is often neglected. To this end, we propose DAES, an end-to-end framework designed to tackle numerical feature embedding in streaming training scenarios by integrating distributional information with an adaptive modulation mechanism. Specifically, we introduce an efficient reservoir-sampling-based distribution estimation method and two field-aware distribution modulation strategies to capture streaming distributions and field-dependent semantics. DAES significantly outperforms existing approaches as demonstrated by extensive offline and online experiments and has been fully deployed on a leading short-video platform with hundreds of millions of daily active users.
Introducing Context Information in Lifelong Sequential Modeling using Temporal Convolutional Networks
Feb 18, 2025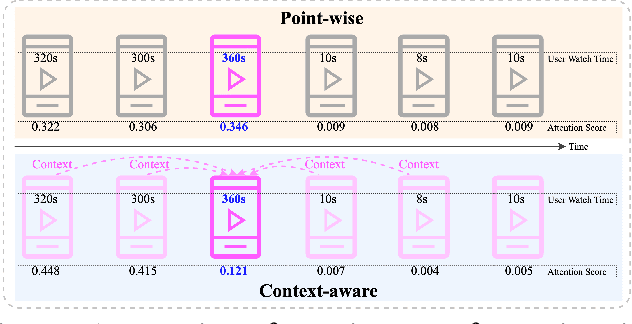
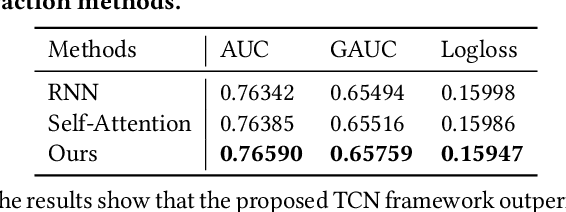
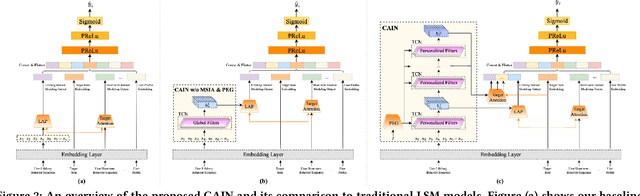
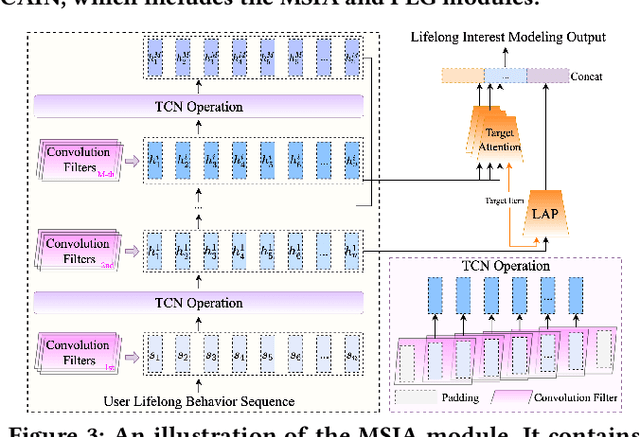
The importance of lifelong sequential modeling (LSM) is growing in the realm of social media recommendation systems. A key component in this process is the attention module, which derives interest representations with respect to candidate items from the sequence. Typically, attention modules function in a point-wise fashion, concentrating only on the relevance of individual items in the sequence to the candidate item. However, the context information in the neighboring items that is useful for more accurately evaluating the significance of each item has not been taken into account. In this study, we introduce a novel network which employs the Temporal Convolutional Network (TCN) to generate context-aware representations for each item throughout the lifelong sequence. These improved representations are then utilized in the attention module to produce context-aware interest representations. Expanding on this TCN framework, we present a enhancement module which includes multiple TCN layers and their respective attention modules to capture interest representations across different context scopes. Additionally, we also incorporate a lightweight sub-network to create convolution filters based on users' basic profile features. These personalized filters are then applied in the TCN layers instead of the original global filters to produce more user-specific representations. We performed experiments on both a public dataset and a proprietary dataset. The findings indicate that the proposed network surpasses existing methods in terms of prediction accuracy and online performance metrics.
Cross Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction
Dec 11, 2023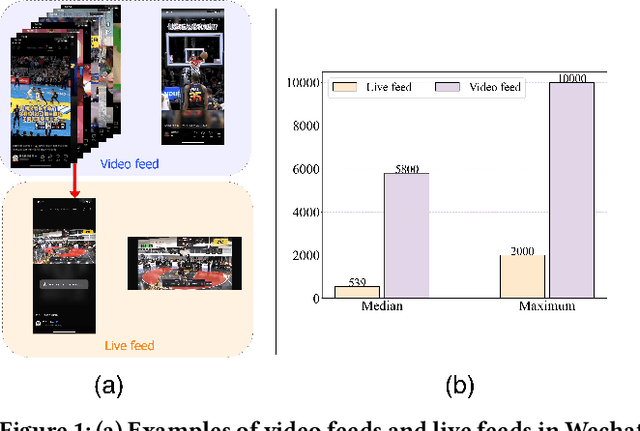

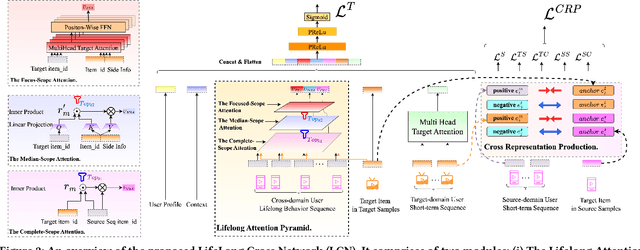
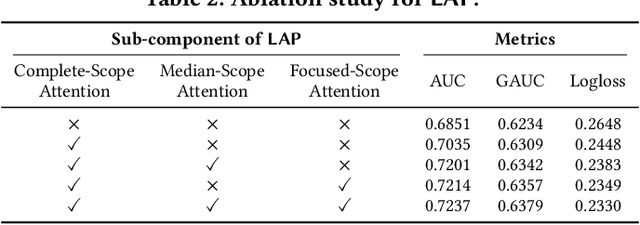
Deep neural networks (DNNs) that incorporated lifelong sequential modeling (LSM) have brought great success to recommendation systems in various social media platforms. While continuous improvements have been made in domain-specific LSM, limited work has been done in cross-domain LSM, which considers modeling of lifelong sequences of both target domain and source domain. In this paper, we propose Lifelong Cross Network (LCN) to incorporate cross-domain LSM to improve the click-through rate (CTR) prediction in the target domain. The proposed LCN contains a LifeLong Attention Pyramid (LAP) module that comprises of three levels of cascaded attentions to effectively extract interest representations with respect to the candidate item from lifelong sequences. We also propose Cross Representation Production (CRP) module to enforce additional supervision on the learning and alignment of cross-domain representations so that they can be better reused on learning of the CTR prediction in the target domain. We conducted extensive experiments on WeChat Channels industrial dataset as well as on benchmark dataset. Results have revealed that the proposed LCN outperforms existing work in terms of both prediction accuracy and online performance.
WeChat Neural Machine Translation Systems for WMT20
Oct 05, 2020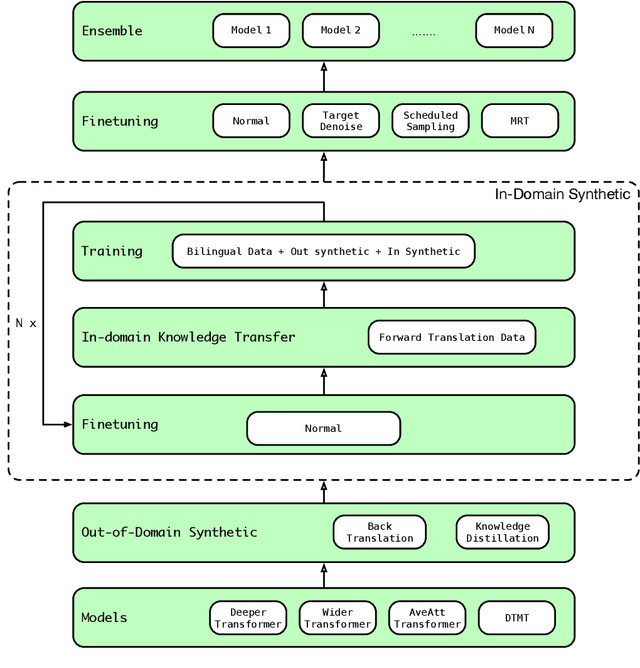

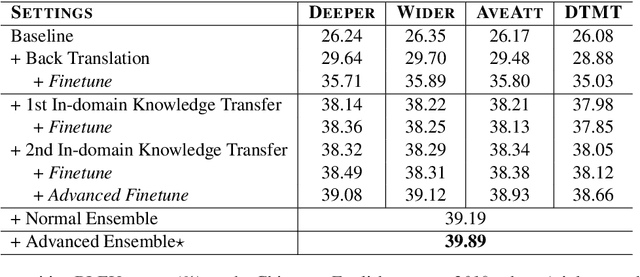
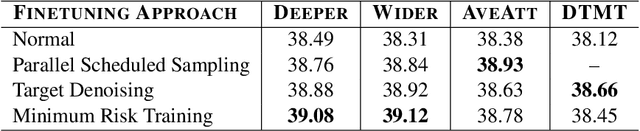
We participate in the WMT 2020 shared news translation task on Chinese to English. Our system is based on the Transformer (Vaswani et al., 2017a) with effective variants and the DTMT (Meng and Zhang, 2019) architecture. In our experiments, we employ data selection, several synthetic data generation approaches (i.e., back-translation, knowledge distillation, and iterative in-domain knowledge transfer), advanced finetuning approaches and self-bleu based model ensemble. Our constrained Chinese to English system achieves 36.9 case-sensitive BLEU score, which is the highest among all submissions.
Testing Untestable Neural Machine Translation: An Industrial Case
Oct 03, 2018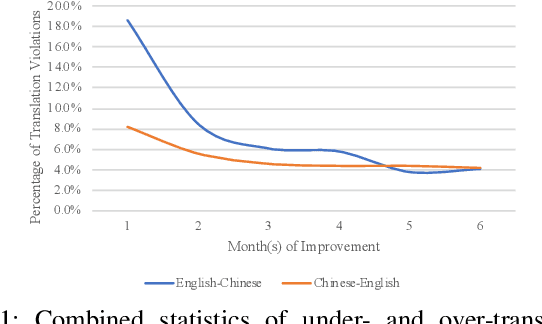
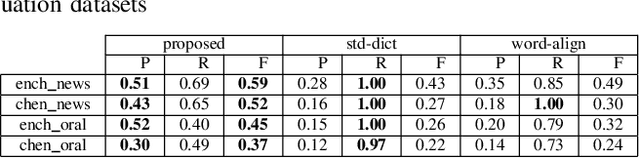

Neural Machine Translation (NMT) has been widely adopted recently due to its advantages compared with the traditional Statistical Machine Translation (SMT). However, an NMT system still often produces translation failures due to the complexity of natural language and sophistication in designing neural networks. While in-house black-box system testing based on reference translations (i.e., examples of valid translations) has been a common practice for NMT quality assurance, an increasingly critical industrial practice, named in-vivo testing, exposes unseen types or instances of translation failures when real users are using a deployed industrial NMT system. To fill the gap of lacking test oracle for in-vivo testing of an NMT system, in this paper, we propose a new approach for automatically identifying translation failures, without requiring reference translations for a translation task; our approach can directly serve as a test oracle for in-vivo testing. Our approach focuses on properties of natural language translation that can be checked systematically and uses information from both the test inputs (i.e., the texts to be translated) and the test outputs (i.e., the translations under inspection) of the NMT system. Our evaluation conducted on real-world datasets shows that our approach can effectively detect targeted property violations as translation failures. Our experiences on deploying our approach in both production and development environments of WeChat (a messenger app with over one billion monthly active users) demonstrate high effectiveness of our approach along with high industry impact.