 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Introducing Context Information in Lifelong Sequential Modeling using Temporal Convolutional Networks
Feb 18, 2025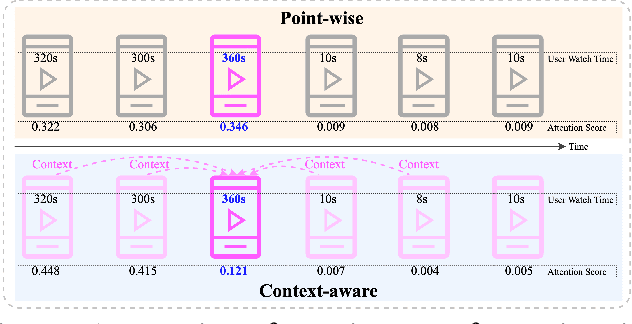
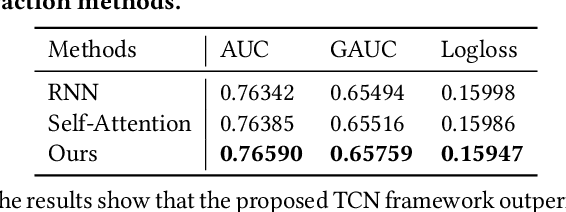
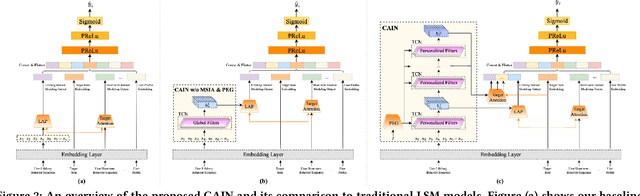
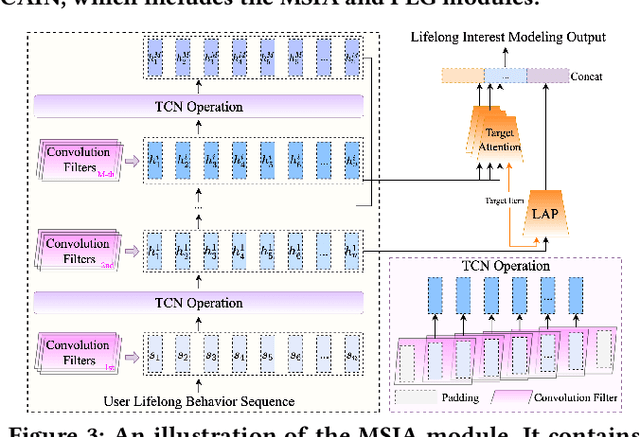
The importance of lifelong sequential modeling (LSM) is growing in the realm of social media recommendation systems. A key component in this process is the attention module, which derives interest representations with respect to candidate items from the sequence. Typically, attention modules function in a point-wise fashion, concentrating only on the relevance of individual items in the sequence to the candidate item. However, the context information in the neighboring items that is useful for more accurately evaluating the significance of each item has not been taken into account. In this study, we introduce a novel network which employs the Temporal Convolutional Network (TCN) to generate context-aware representations for each item throughout the lifelong sequence. These improved representations are then utilized in the attention module to produce context-aware interest representations. Expanding on this TCN framework, we present a enhancement module which includes multiple TCN layers and their respective attention modules to capture interest representations across different context scopes. Additionally, we also incorporate a lightweight sub-network to create convolution filters based on users' basic profile features. These personalized filters are then applied in the TCN layers instead of the original global filters to produce more user-specific representations. We performed experiments on both a public dataset and a proprietary dataset. The findings indicate that the proposed network surpasses existing methods in terms of prediction accuracy and online performance metrics.
Spatio-Temporal Contrastive Learning Enhanced GNNs for Session-based Recommendation
Sep 23, 2022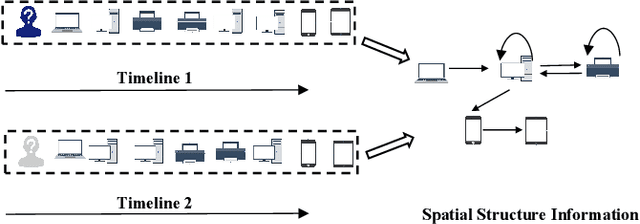
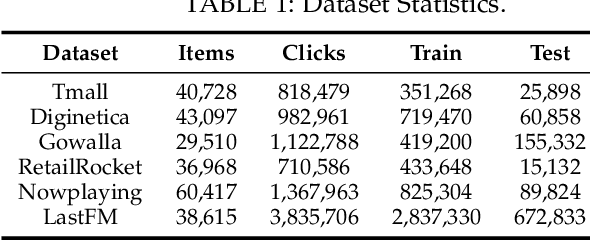

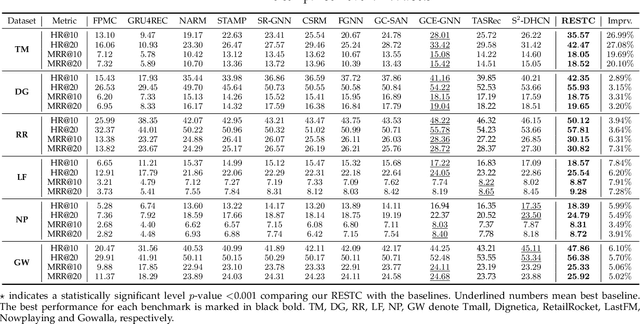
Session-based recommendation (SBR) systems aim to utilize the user's short-term behavior sequence to predict the next item without the detailed user profile. Most recent works try to model the user preference by treating the sessions as between-item transition graphs and utilize various graph neural networks (GNNs) to encode the representations of pair-wise relations among items and their neighbors. Some of the existing GNN-based models mainly focus on aggregating information from the view of spatial graph structure, which ignores the temporal relations within neighbors of an item during message passing and the information loss results in a sub-optimal problem. Other works embrace this challenge by incorporating additional temporal information but lack sufficient interaction between the spatial and temporal patterns. To address this issue, inspired by the uniformity and alignment properties of contrastive learning techniques, we propose a novel framework called Session-based Recommendation with Spatio-Temporal Contrastive Learning Enhanced GNNs (RESTC). The idea is to supplement the GNN-based main supervised recommendation task with the temporal representation via an auxiliary cross-view contrastive learning mechanism. Furthermore, a novel global collaborative filtering graph (CFG) embedding is leveraged to enhance the spatial view in the main task. Extensive experiments demonstrate the significant performance of RESTC compared with the state-of-the-art baselines e.g., with an improvement as much as 27.08% gain on HR@20 and 20.10% gain on MRR@20.