 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRing-lite: Scalable Reasoning via C3PO-Stabilized Reinforcement Learning for LLMs
Jun 18, 2025We present Ring-lite, a Mixture-of-Experts (MoE)-based large language model optimized via reinforcement learning (RL) to achieve efficient and robust reasoning capabilities. Built upon the publicly available Ling-lite model, a 16.8 billion parameter model with 2.75 billion activated parameters, our approach matches the performance of state-of-the-art (SOTA) small-scale reasoning models on challenging benchmarks (e.g., AIME, LiveCodeBench, GPQA-Diamond) while activating only one-third of the parameters required by comparable models. To accomplish this, we introduce a joint training pipeline integrating distillation with RL, revealing undocumented challenges in MoE RL training. First, we identify optimization instability during RL training, and we propose Constrained Contextual Computation Policy Optimization(C3PO), a novel approach that enhances training stability and improves computational throughput via algorithm-system co-design methodology. Second, we empirically demonstrate that selecting distillation checkpoints based on entropy loss for RL training, rather than validation metrics, yields superior performance-efficiency trade-offs in subsequent RL training. Finally, we develop a two-stage training paradigm to harmonize multi-domain data integration, addressing domain conflicts that arise in training with mixed dataset. We will release the model, dataset, and code.
SHARP: Synthesizing High-quality Aligned Reasoning Problems for Large Reasoning Models Reinforcement Learning
May 21, 2025Training large reasoning models (LRMs) with reinforcement learning in STEM domains is hindered by the scarcity of high-quality, diverse, and verifiable problem sets. Existing synthesis methods, such as Chain-of-Thought prompting, often generate oversimplified or uncheckable data, limiting model advancement on complex tasks. To address these challenges, we introduce SHARP, a unified approach to Synthesizing High-quality Aligned Reasoning Problems for LRMs reinforcement learning with verifiable rewards (RLVR). SHARP encompasses a strategic set of self-alignment principles -- targeting graduate and Olympiad-level difficulty, rigorous logical consistency, and unambiguous, verifiable answers -- and a structured three-phase framework (Alignment, Instantiation, Inference) that ensures thematic diversity and fine-grained control over problem generation. We implement SHARP by leveraging a state-of-the-art LRM to infer and verify challenging STEM questions, then employ a reinforcement learning loop to refine the model's reasoning through verifiable reward signals. Experiments on benchmarks such as GPQA demonstrate that SHARP-augmented training substantially outperforms existing methods, markedly improving complex reasoning accuracy and pushing LRM performance closer to expert-level proficiency. Our contributions include the SHARP strategy, framework design, end-to-end implementation, and experimental evaluation of its effectiveness in elevating LRM reasoning capabilities.
Every FLOP Counts: Scaling a 300B Mixture-of-Experts LING LLM without Premium GPUs
Mar 07, 2025



In this technical report, we tackle the challenges of training large-scale Mixture of Experts (MoE) models, focusing on overcoming cost inefficiency and resource limitations prevalent in such systems. To address these issues, we present two differently sized MoE large language models (LLMs), namely Ling-Lite and Ling-Plus (referred to as "Bailing" in Chinese, spelled B\v{a}il\'ing in Pinyin). Ling-Lite contains 16.8 billion parameters with 2.75 billion activated parameters, while Ling-Plus boasts 290 billion parameters with 28.8 billion activated parameters. Both models exhibit comparable performance to leading industry benchmarks. This report offers actionable insights to improve the efficiency and accessibility of AI development in resource-constrained settings, promoting more scalable and sustainable technologies. Specifically, to reduce training costs for large-scale MoE models, we propose innovative methods for (1) optimization of model architecture and training processes, (2) refinement of training anomaly handling, and (3) enhancement of model evaluation efficiency. Additionally, leveraging high-quality data generated from knowledge graphs, our models demonstrate superior capabilities in tool use compared to other models. Ultimately, our experimental findings demonstrate that a 300B MoE LLM can be effectively trained on lower-performance devices while achieving comparable performance to models of a similar scale, including dense and MoE models. Compared to high-performance devices, utilizing a lower-specification hardware system during the pre-training phase demonstrates significant cost savings, reducing computing costs by approximately 20%. The models can be accessed at https://huggingface.co/inclusionAI.
Mix Data or Merge Models? Balancing the Helpfulness, Honesty, and Harmlessness of Large Language Model via Model Merging
Feb 13, 2025
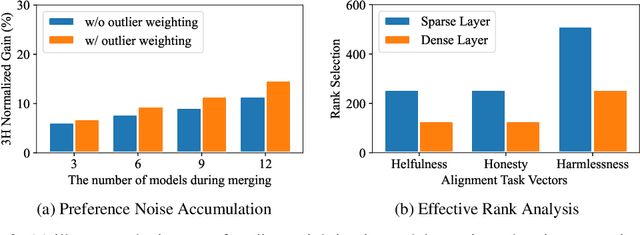

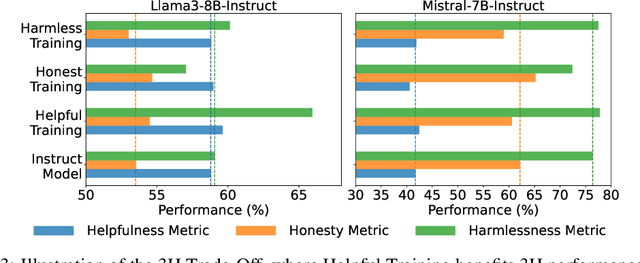
Achieving balanced alignment of large language models (LLMs) in terms of Helpfulness, Honesty, and Harmlessness (3H optimization) constitutes a cornerstone of responsible AI, with existing methods like data mixture strategies facing limitations including reliance on expert knowledge and conflicting optimization signals. While model merging offers a promising alternative by integrating specialized models, its potential for 3H optimization remains underexplored. This paper establishes the first comprehensive benchmark for model merging in 3H-aligned LLMs, systematically evaluating 15 methods (12 training-free merging and 3 data mixture techniques) across 10 datasets associated with 5 annotation dimensions, 2 LLM families, and 2 training paradigms. Our analysis reveals three pivotal insights: (i) previously overlooked collaborative/conflicting relationships among 3H dimensions, (ii) the consistent superiority of model merging over data mixture approaches in balancing alignment trade-offs, and (iii) the critical role of parameter-level conflict resolution through redundant component pruning and outlier mitigation. Building on these findings, we propose R-TSVM, a Reweighting-enhanced Task Singular Vector Merging method that incorporates outlier-aware parameter weighting and sparsity-adaptive rank selection strategies adapted to the heavy-tailed parameter distribution and sparsity for LLMs, further improving LLM alignment across multiple evaluations. We release our trained models for further exploration.
CARE: A Clue-guided Assistant for CSRs to Read User Manuals
Aug 07, 2024



It is time-saving to build a reading assistant for customer service representations (CSRs) when reading user manuals, especially information-rich ones. Current solutions don't fit the online custom service scenarios well due to the lack of attention to user questions and possible responses. Hence, we propose to develop a time-saving and careful reading assistant for CSRs, named CARE. It can help the CSRs quickly find proper responses from the user manuals via explicit clue chains. Specifically, each of the clue chains is formed by inferring over the user manuals, starting from the question clue aligned with the user question and ending at a possible response. To overcome the shortage of supervised data, we adopt the self-supervised strategy for model learning. The offline experiment shows that CARE is efficient in automatically inferring accurate responses from the user manual. The online experiment further demonstrates the superiority of CARE to reduce CSRs' reading burden and keep high service quality, in particular with >35% decrease in time spent and keeping a >0.75 ICC score.
CLAMBER: A Benchmark of Identifying and Clarifying Ambiguous Information Needs in Large Language Models
May 20, 2024



Large language models (LLMs) are increasingly used to meet user information needs, but their effectiveness in dealing with user queries that contain various types of ambiguity remains unknown, ultimately risking user trust and satisfaction. To this end, we introduce CLAMBER, a benchmark for evaluating LLMs using a well-organized taxonomy. Building upon the taxonomy, we construct ~12K high-quality data to assess the strengths, weaknesses, and potential risks of various off-the-shelf LLMs. Our findings indicate the limited practical utility of current LLMs in identifying and clarifying ambiguous user queries, even enhanced by chain-of-thought (CoT) and few-shot prompting. These techniques may result in overconfidence in LLMs and yield only marginal enhancements in identifying ambiguity. Furthermore, current LLMs fall short in generating high-quality clarifying questions due to a lack of conflict resolution and inaccurate utilization of inherent knowledge. In this paper, CLAMBER presents a guidance and promotes further research on proactive and trustworthy LLMs. Our dataset is available at https://github.com/zt991211/CLAMBER
STYLE: Improving Domain Transferability of Asking Clarification Questions in Large Language Model Powered Conversational Agents
May 20, 2024Equipping a conversational search engine with strategies regarding when to ask clarification questions is becoming increasingly important across various domains. Attributing to the context understanding capability of LLMs and their access to domain-specific sources of knowledge, LLM-based clarification strategies feature rapid transfer to various domains in a post-hoc manner. However, they still struggle to deliver promising performance on unseen domains, struggling to achieve effective domain transferability. We take the first step to investigate this issue and existing methods tend to produce one-size-fits-all strategies across diverse domains, limiting their search effectiveness. In response, we introduce a novel method, called Style, to achieve effective domain transferability. Our experimental results indicate that Style bears strong domain transferability, resulting in an average search performance improvement of ~10% on four unseen domains.