 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseX: AI Defeats Physics Approaches on Protein-Ligand Cross Docking
May 03, 2025Recently, significant progress has been made in protein-ligand docking, especially in modern deep learning methods, and some benchmarks were proposed, e.g., PoseBench, Plinder. However, these benchmarks suffer from less practical evaluation setups (e.g., blind docking, self docking), or heavy framework that involves training, raising challenges to assess docking methods efficiently. To fill this gap, we proposed PoseX, an open-source benchmark focusing on self-docking and cross-docking, to evaluate the algorithmic advances practically and comprehensively. Specifically, first, we curate a new evaluation dataset with 718 entries for self docking and 1,312 for cross docking; second, we incorporate 22 docking methods across three methodological categories, including (1) traditional physics-based methods (e.g., Schr\"odinger Glide), (2) AI docking methods (e.g., DiffDock), (3) AI co-folding methods (e.g., AlphaFold3); third, we design a relaxation method as post-processing to minimize conformation energy and refine binding pose; fourth, we released a leaderboard to rank submitted models in real time. We draw some key insights via extensive experiments: (1) AI-based approaches have already surpassed traditional physics-based approaches in overall docking accuracy (RMSD). The longstanding generalization issues that have plagued AI molecular docking have been significantly alleviated in the latest models. (2) The stereochemical deficiencies of AI-based approaches can be greatly alleviated with post-processing relaxation. Combining AI docking methods with the enhanced relaxation method achieves the best performance to date. (3) AI co-folding methods commonly face ligand chirality issues, which cannot be resolved by relaxation. The code, curated dataset and leaderboard are released at https://github.com/CataAI/PoseX.
Chats-Grid: An Iterative Retrieval Q&A Optimization Scheme Leveraging Large Model and Retrieval Enhancement Generation in smart grid
Feb 21, 2025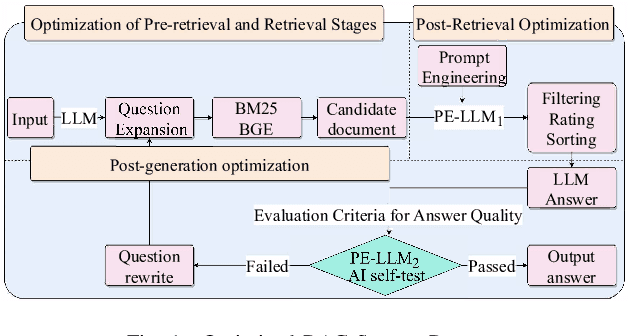
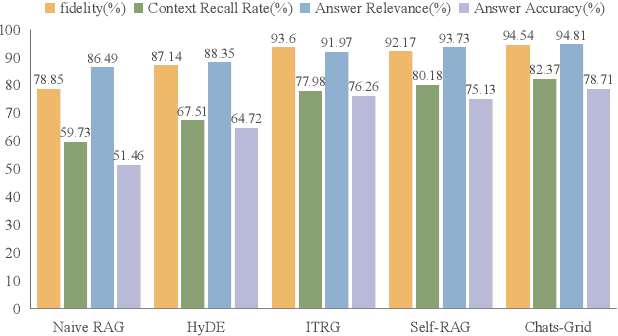
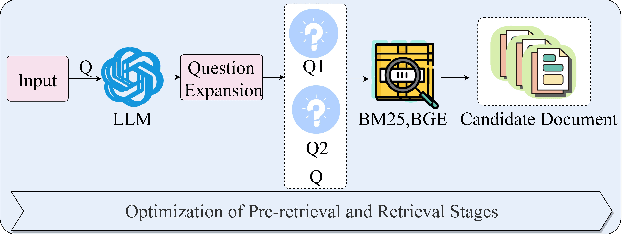

With rapid advancements in artificial intelligence, question-answering (Q&A) systems have become essential in intelligent search engines, virtual assistants, and customer service platforms. However, in dynamic domains like smart grids, conventional retrieval-augmented generation(RAG) Q&A systems face challenges such as inadequate retrieval quality, irrelevant responses, and inefficiencies in handling large-scale, real-time data streams. This paper proposes an optimized iterative retrieval-based Q&A framework called Chats-Grid tailored for smart grid environments. In the pre-retrieval phase, Chats-Grid advanced query expansion ensures comprehensive coverage of diverse data sources, including sensor readings, meter records, and control system parameters. During retrieval, Best Matching 25(BM25) sparse retrieval and BAAI General Embedding(BGE) dense retrieval in Chats-Grid are combined to process vast, heterogeneous datasets effectively. Post-retrieval, a fine-tuned large language model uses prompt engineering to assess relevance, filter irrelevant results, and reorder documents based on contextual accuracy. The model further generates precise, context-aware answers, adhering to quality criteria and employing a self-checking mechanism for enhanced reliability. Experimental results demonstrate Chats-Grid's superiority over state-of-the-art methods in fidelity, contextual recall, relevance, and accuracy by 2.37%, 2.19%, and 3.58% respectively. This framework advances smart grid management by improving decision-making and user interactions, fostering resilient and adaptive smart grid infrastructures.
Detached and Interactive Multimodal Learning
Jul 28, 2024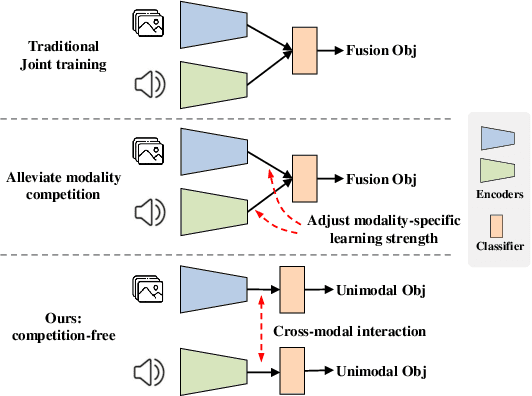

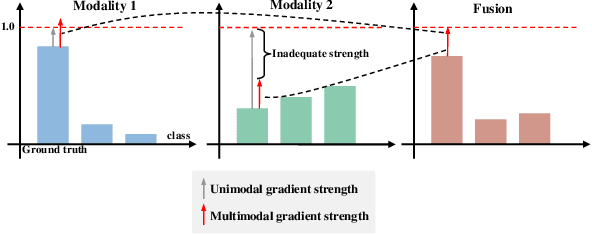
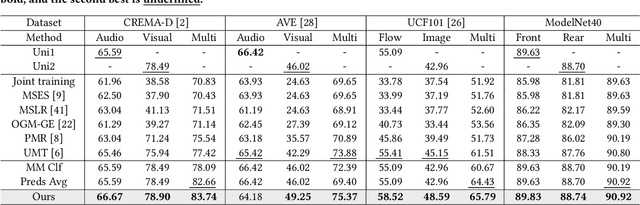
Recently, Multimodal Learning (MML) has gained significant interest as it compensates for single-modality limitations through comprehensive complementary information within multimodal data. However, traditional MML methods generally use the joint learning framework with a uniform learning objective that can lead to the modality competition issue, where feedback predominantly comes from certain modalities, limiting the full potential of others. In response to this challenge, this paper introduces DI-MML, a novel detached MML framework designed to learn complementary information across modalities under the premise of avoiding modality competition. Specifically, DI-MML addresses competition by separately training each modality encoder with isolated learning objectives. It further encourages cross-modal interaction via a shared classifier that defines a common feature space and employing a dimension-decoupled unidirectional contrastive (DUC) loss to facilitate modality-level knowledge transfer. Additionally, to account for varying reliability in sample pairs, we devise a certainty-aware logit weighting strategy to effectively leverage complementary information at the instance level during inference. Extensive experiments conducted on audio-visual, flow-image, and front-rear view datasets show the superior performance of our proposed method. The code is released at https://github.com/fanyunfeng-bit/DI-MML.
CLAMBER: A Benchmark of Identifying and Clarifying Ambiguous Information Needs in Large Language Models
May 20, 2024



Large language models (LLMs) are increasingly used to meet user information needs, but their effectiveness in dealing with user queries that contain various types of ambiguity remains unknown, ultimately risking user trust and satisfaction. To this end, we introduce CLAMBER, a benchmark for evaluating LLMs using a well-organized taxonomy. Building upon the taxonomy, we construct ~12K high-quality data to assess the strengths, weaknesses, and potential risks of various off-the-shelf LLMs. Our findings indicate the limited practical utility of current LLMs in identifying and clarifying ambiguous user queries, even enhanced by chain-of-thought (CoT) and few-shot prompting. These techniques may result in overconfidence in LLMs and yield only marginal enhancements in identifying ambiguity. Furthermore, current LLMs fall short in generating high-quality clarifying questions due to a lack of conflict resolution and inaccurate utilization of inherent knowledge. In this paper, CLAMBER presents a guidance and promotes further research on proactive and trustworthy LLMs. Our dataset is available at https://github.com/zt991211/CLAMBER
AUTODIFF: Autoregressive Diffusion Modeling for Structure-based Drug Design
Apr 03, 2024Structure-based drug design (SBDD), which aims to generate molecules that can bind tightly to the target protein, is an essential problem in drug discovery, and previous approaches have achieved initial success. However, most existing methods still suffer from invalid local structure or unrealistic conformation issues, which are mainly due to the poor leaning of bond angles or torsional angles. To alleviate these problems, we propose AUTODIFF, a diffusion-based fragment-wise autoregressive generation model. Specifically, we design a novel molecule assembly strategy named conformal motif that preserves the conformation of local structures of molecules first, then we encode the interaction of the protein-ligand complex with an SE(3)-equivariant convolutional network and generate molecules motif-by-motif with diffusion modeling. In addition, we also improve the evaluation framework of SBDD by constraining the molecular weights of the generated molecules in the same range, together with some new metrics, which make the evaluation more fair and practical. Extensive experiments on CrossDocked2020 demonstrate that our approach outperforms the existing models in generating realistic molecules with valid structures and conformations while maintaining high binding affinity.