 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeploying Foundation Model Powered Agent Services: A Survey
Dec 18, 2024



Foundation model (FM) powered agent services are regarded as a promising solution to develop intelligent and personalized applications for advancing toward Artificial General Intelligence (AGI). To achieve high reliability and scalability in deploying these agent services, it is essential to collaboratively optimize computational and communication resources, thereby ensuring effective resource allocation and seamless service delivery. In pursuit of this vision, this paper proposes a unified framework aimed at providing a comprehensive survey on deploying FM-based agent services across heterogeneous devices, with the emphasis on the integration of model and resource optimization to establish a robust infrastructure for these services. Particularly, this paper begins with exploring various low-level optimization strategies during inference and studies approaches that enhance system scalability, such as parallelism techniques and resource scaling methods. The paper then discusses several prominent FMs and investigates research efforts focused on inference acceleration, including techniques such as model compression and token reduction. Moreover, the paper also investigates critical components for constructing agent services and highlights notable intelligent applications. Finally, the paper presents potential research directions for developing real-time agent services with high Quality of Service (QoS).
Detached and Interactive Multimodal Learning
Jul 28, 2024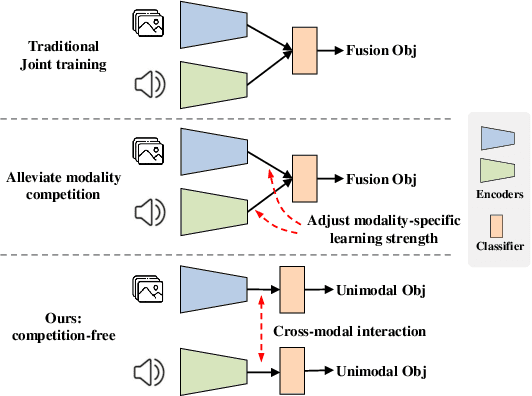

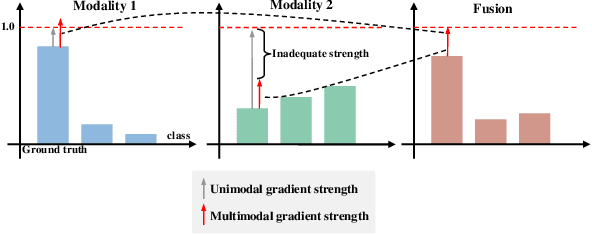
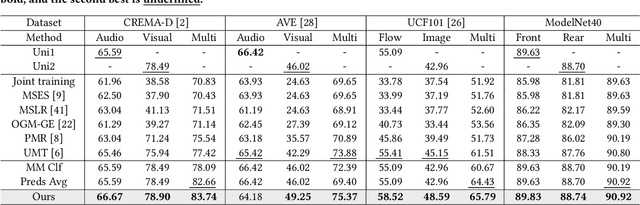
Recently, Multimodal Learning (MML) has gained significant interest as it compensates for single-modality limitations through comprehensive complementary information within multimodal data. However, traditional MML methods generally use the joint learning framework with a uniform learning objective that can lead to the modality competition issue, where feedback predominantly comes from certain modalities, limiting the full potential of others. In response to this challenge, this paper introduces DI-MML, a novel detached MML framework designed to learn complementary information across modalities under the premise of avoiding modality competition. Specifically, DI-MML addresses competition by separately training each modality encoder with isolated learning objectives. It further encourages cross-modal interaction via a shared classifier that defines a common feature space and employing a dimension-decoupled unidirectional contrastive (DUC) loss to facilitate modality-level knowledge transfer. Additionally, to account for varying reliability in sample pairs, we devise a certainty-aware logit weighting strategy to effectively leverage complementary information at the instance level during inference. Extensive experiments conducted on audio-visual, flow-image, and front-rear view datasets show the superior performance of our proposed method. The code is released at https://github.com/fanyunfeng-bit/DI-MML.
Client-wise Modality Selection for Balanced Multi-modal Federated Learning
Dec 31, 2023Selecting proper clients to participate in the iterative federated learning (FL) rounds is critical to effectively harness a broad range of distributed datasets. Existing client selection methods simply consider the variability among FL clients with uni-modal data, however, have yet to consider clients with multi-modalities. We reveal that traditional client selection scheme in MFL may suffer from a severe modality-level bias, which impedes the collaborative exploitation of multi-modal data, leading to insufficient local data exploration and global aggregation. To tackle this challenge, we propose a Client-wise Modality Selection scheme for MFL (CMSFed) that can comprehensively utilize information from each modality via avoiding such client selection bias caused by modality imbalance. Specifically, in each MFL round, the local data from different modalities are selectively employed to participate in local training and aggregation to mitigate potential modality imbalance of the global model. To approximate the fully aggregated model update in a balanced way, we introduce a novel local training loss function to enhance the weak modality and align the divergent feature spaces caused by inconsistent modality adoption strategies for different clients simultaneously. Then, a modality-level gradient decoupling method is designed to derive respective submodular functions to maintain the gradient diversity during the selection progress and balance MFL according to local modality imbalance in each iteration. Our extensive experiments showcase the superiority of CMSFed over baselines and its effectiveness in multi-modal data exploitation.
Balanced Multi-modal Federated Learning via Cross-Modal Infiltration
Dec 31, 2023Federated learning (FL) underpins advancements in privacy-preserving distributed computing by collaboratively training neural networks without exposing clients' raw data. Current FL paradigms primarily focus on uni-modal data, while exploiting the knowledge from distributed multimodal data remains largely unexplored. Existing multimodal FL (MFL) solutions are mainly designed for statistical or modality heterogeneity from the input side, however, have yet to solve the fundamental issue,"modality imbalance", in distributed conditions, which can lead to inadequate information exploitation and heterogeneous knowledge aggregation on different modalities.In this paper, we propose a novel Cross-Modal Infiltration Federated Learning (FedCMI) framework that effectively alleviates modality imbalance and knowledge heterogeneity via knowledge transfer from the global dominant modality. To avoid the loss of information in the weak modality due to merely imitating the behavior of dominant modality, we design the two-projector module to integrate the knowledge from dominant modality while still promoting the local feature exploitation of weak modality. In addition, we introduce a class-wise temperature adaptation scheme to achieve fair performance across different classes. Extensive experiments over popular datasets are conducted and give us a gratifying confirmation of the proposed framework for fully exploring the information of each modality in MFL.
Offline-Online Class-incremental Continual Learning via Dual-prototype Self-augment and Refinement
Mar 20, 2023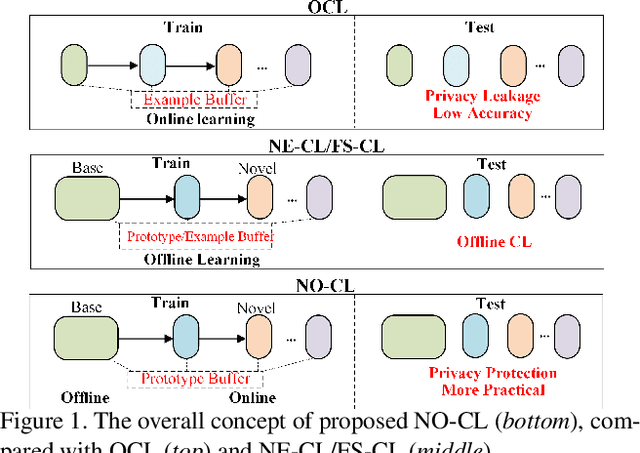

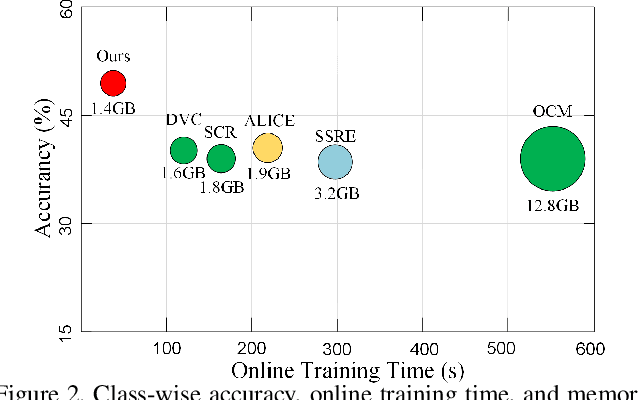

This paper investigates a new, practical, but challenging problem named Offline-Online Class-incremental Continual Learning (O$^2$CL), which aims to preserve the discernibility of pre-trained (i.e., offline) base classes without buffering data examples, and efficiently learn novel classes continuously in a single-pass (i.e., online) data stream. The challenges of this task are mainly two-fold: 1) Both base and novel classes suffer from severe catastrophic forgetting as no previous samples are available for replay. 2) As the online data can only be observed once, there is no way to fully re-train the whole model, e.g., re-calibrate the decision boundaries via prototype alignment or feature distillation. In this paper, we propose a novel Dual-prototype Self-augment and Refinement method (DSR) for O$^2$CL problem, which consists of two strategies: 1) Dual class prototypes: Inner and hyper-dimensional prototypes are exploited to utilize the pre-trained information and obtain robust quasi-orthogonal representations rather than example buffers for both privacy preservation and memory reduction. 2) Self-augment and refinement: Instead of updating the whole network, we jointly optimize the extra projection module with the self-augment inner prototypes from base and novel classes, gradually refining the hyper-dimensional prototypes to obtain accurate decision boundaries for learned classes. Extensive experiments demonstrate the effectiveness and superiority of the proposed DSR in O$^2$CL.
DualMix: Unleashing the Potential of Data Augmentation for Online Class-Incremental Learning
Mar 14, 2023



Online Class-Incremental (OCI) learning has sparked new approaches to expand the previously trained model knowledge from sequentially arriving data streams with new classes. Unfortunately, OCI learning can suffer from catastrophic forgetting (CF) as the decision boundaries for old classes can become inaccurate when perturbated by new ones. Existing literature have applied the data augmentation (DA) to alleviate the model forgetting, while the role of DA in OCI has not been well understood so far. In this paper, we theoretically show that augmented samples with lower correlation to the original data are more effective in preventing forgetting. However, aggressive augmentation may also reduce the consistency between data and corresponding labels, which motivates us to exploit proper DA to boost the OCI performance and prevent the CF problem. We propose the Enhanced Mixup (EnMix) method that mixes the augmented samples and their labels simultaneously, which is shown to enhance the sample diversity while maintaining strong consistency with corresponding labels. Further, to solve the class imbalance problem, we design an Adaptive Mixup (AdpMix) method to calibrate the decision boundaries by mixing samples from both old and new classes and dynamically adjusting the label mixing ratio. Our approach is demonstrated to be effective on several benchmark datasets through extensive experiments, and it is shown to be compatible with other replay-based techniques.
PMR: Prototypical Modal Rebalance for Multimodal Learning
Nov 14, 2022



Multimodal learning (MML) aims to jointly exploit the common priors of different modalities to compensate for their inherent limitations. However, existing MML methods often optimize a uniform objective for different modalities, leading to the notorious "modality imbalance" problem and counterproductive MML performance. To address the problem, some existing methods modulate the learning pace based on the fused modality, which is dominated by the better modality and eventually results in a limited improvement on the worse modal. To better exploit the features of multimodal, we propose Prototypical Modality Rebalance (PMR) to perform stimulation on the particular slow-learning modality without interference from other modalities. Specifically, we introduce the prototypes that represent general features for each class, to build the non-parametric classifiers for uni-modal performance evaluation. Then, we try to accelerate the slow-learning modality by enhancing its clustering toward prototypes. Furthermore, to alleviate the suppression from the dominant modality, we introduce a prototype-based entropy regularization term during the early training stage to prevent premature convergence. Besides, our method only relies on the representations of each modality and without restrictions from model structures and fusion methods, making it with great application potential for various scenarios.