 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHALO: Semantic-Aware Distributed LLM Inference in Lossy Edge Network
Jan 16, 2026The deployment of large language models' (LLMs) inference at the edge can facilitate prompt service responsiveness while protecting user privacy. However, it is critically challenged by the resource constraints of a single edge node. Distributed inference has emerged to aggregate and leverage computational resources across multiple devices. Yet, existing methods typically require strict synchronization, which is often infeasible due to the unreliable network conditions. In this paper, we propose HALO, a novel framework that can boost the distributed LLM inference in lossy edge network. The core idea is to enable a relaxed yet effective synchronization by strategically allocating less critical neuron groups to unstable devices, thus avoiding the excessive waiting time incurred by delayed packets. HALO introduces three key mechanisms: (1) a semantic-aware predictor to assess the significance of neuron groups prior to activation. (2) a parallel execution scheme of neuron group loading during the model inference. (3) a load-balancing scheduler that efficiently orchestrates multiple devices with heterogeneous resources. Experimental results from a Raspberry Pi cluster demonstrate that HALO achieves a 3.41x end-to-end speedup for LLaMA-series LLMs under unreliable network conditions. It maintains performance comparable to optimal conditions and significantly outperforms the state-of-the-art in various scenarios.
Shared Representation Learning for High-Dimensional Multi-Task Forecasting under Resource Contention in Cloud-Native Backends
Dec 24, 2025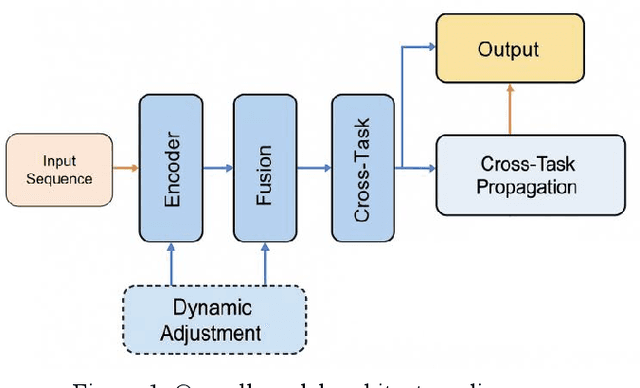
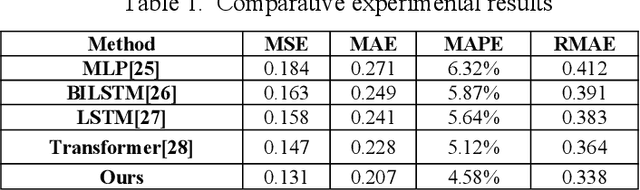
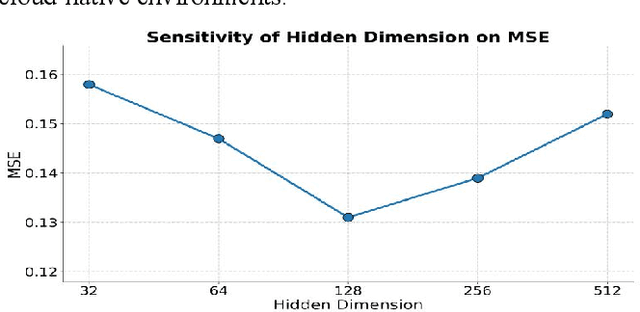
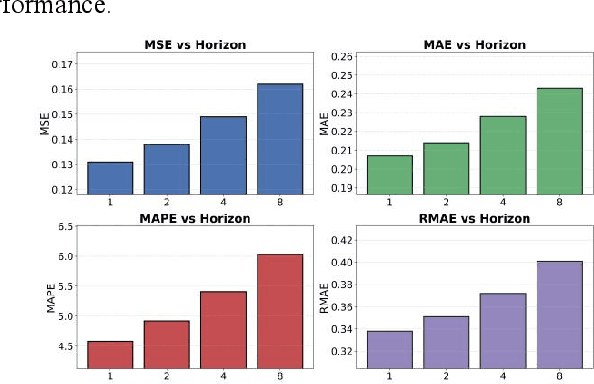
This study proposes a unified forecasting framework for high-dimensional multi-task time series to meet the prediction demands of cloud native backend systems operating under highly dynamic loads, coupled metrics, and parallel tasks. The method builds a shared encoding structure to represent diverse monitoring indicators in a unified manner and employs a state fusion mechanism to capture trend changes and local disturbances across different time scales. A cross-task structural propagation module is introduced to model potential dependencies among nodes, enabling the model to understand complex structural patterns formed by resource contention, link interactions, and changes in service topology. To enhance adaptability to non-stationary behaviors, the framework incorporates a dynamic adjustment mechanism that automatically regulates internal feature flows according to system state changes, ensuring stable predictions in the presence of sudden load shifts, topology drift, and resource jitter. The experimental evaluation compares multiple models across various metrics and verifies the effectiveness of the framework through analyses of hyperparameter sensitivity, environmental sensitivity, and data sensitivity. The results show that the proposed method achieves superior performance on several error metrics and provides more accurate representations of future states under different operating conditions. Overall, the unified forecasting framework offers reliable predictive capability for high-dimensional, multi-task, and strongly dynamic environments in cloud native systems and provides essential technical support for intelligent backend management.
Cost-TrustFL: Cost-Aware Hierarchical Federated Learning with Lightweight Reputation Evaluation across Multi-Cloud
Dec 23, 2025Federated learning across multi-cloud environments faces critical challenges, including non-IID data distributions, malicious participant detection, and substantial cross-cloud communication costs (egress fees). Existing Byzantine-robust methods focus primarily on model accuracy while overlooking the economic implications of data transfer across cloud providers. This paper presents Cost-TrustFL, a hierarchical federated learning framework that jointly optimizes model performance and communication costs while providing robust defense against poisoning attacks. We propose a gradient-based approximate Shapley value computation method that reduces the complexity from exponential to linear, enabling lightweight reputation evaluation. Our cost-aware aggregation strategy prioritizes intra-cloud communication to minimize expensive cross-cloud data transfers. Experiments on CIFAR-10 and FEMNIST datasets demonstrate that Cost-TrustFL achieves 86.7% accuracy under 30% malicious clients while reducing communication costs by 32% compared to baseline methods. The framework maintains stable performance across varying non-IID degrees and attack intensities, making it practical for real-world multi-cloud deployments.
TDC-Cache: A Trustworthy Decentralized Cooperative Caching Framework for Web3.0
Dec 10, 2025



The rapid growth of Web3.0 is transforming the Internet from a centralized structure to decentralized, which empowers users with unprecedented self-sovereignty over their own data. However, in the context of decentralized data access within Web3.0, it is imperative to cope with efficiency concerns caused by the replication of redundant data, as well as security vulnerabilities caused by data inconsistency. To address these challenges, we develop a Trustworthy Decentralized Cooperative Caching (TDC-Cache) framework for Web3.0 to ensure efficient caching and enhance system resilience against adversarial threats. This framework features a two-layer architecture, wherein the Decentralized Oracle Network (DON) layer serves as a trusted intermediary platform for decentralized caching, bridging the contents from decentralized storage and the content requests from users. In light of the complexity of Web3.0 network topologies and data flows, we propose a Deep Reinforcement Learning-Based Decentralized Caching (DRL-DC) for TDC-Cache to dynamically optimize caching strategies of distributed oracles. Furthermore, we develop a Proof of Cooperative Learning (PoCL) consensus to maintain the consistency of decentralized caching decisions within DON. Experimental results show that, compared with existing approaches, the proposed framework reduces average access latency by 20%, increases the cache hit rate by at most 18%, and improves the average success consensus rate by 10%. Overall, this paper serves as a first foray into the investigation of decentralized caching framework and strategy for Web3.0.
STARC: See-Through-Wall Augmented Reality Framework for Human-Robot Collaboration in Emergency Response
Sep 19, 2025In emergency response missions, first responders must navigate cluttered indoor environments where occlusions block direct line-of-sight, concealing both life-threatening hazards and victims in need of rescue. We present STARC, a see-through AR framework for human-robot collaboration that fuses mobile-robot mapping with responder-mounted LiDAR sensing. A ground robot running LiDAR-inertial odometry performs large-area exploration and 3D human detection, while helmet- or handheld-mounted LiDAR on the responder is registered to the robot's global map via relative pose estimation. This cross-LiDAR alignment enables consistent first-person projection of detected humans and their point clouds - rendered in AR with low latency - into the responder's view. By providing real-time visualization of hidden occupants and hazards, STARC enhances situational awareness and reduces operator risk. Experiments in simulation, lab setups, and tactical field trials confirm robust pose alignment, reliable detections, and stable overlays, underscoring the potential of our system for fire-fighting, disaster relief, and other safety-critical operations. Code and design will be open-sourced upon acceptance.
Energy-Constrained Navigation for Planetary Rovers under Hybrid RTG-Solar Power
Sep 18, 2025Future planetary exploration rovers must operate for extended durations on hybrid power inputs that combine steady radioisotope thermoelectric generator (RTG) output with variable solar photovoltaic (PV) availability. While energy-aware planning has been studied for aerial and underwater robots under battery limits, few works for ground rovers explicitly model power flow or enforce instantaneous power constraints. Classical terrain-aware planners emphasize slope or traversability, and trajectory optimization methods typically focus on geometric smoothness and dynamic feasibility, neglecting energy feasibility. We present an energy-constrained trajectory planning framework that explicitly integrates physics-based models of translational, rotational, and resistive power with baseline subsystem loads, under hybrid RTG-solar input. By incorporating both cumulative energy budgets and instantaneous power constraints into SE(2)-based polynomial trajectory optimization, the method ensures trajectories that are simultaneously smooth, dynamically feasible, and power-compliant. Simulation results on lunar-like terrain show that our planner generates trajectories with peak power within 0.55 percent of the prescribed limit, while existing methods exceed limits by over 17 percent. This demonstrates a principled and practical approach to energy-aware autonomy for long-duration planetary missions.
DVDP: An End-to-End Policy for Mobile Robot Visual Docking with RGB-D Perception
Sep 16, 2025Automatic docking has long been a significant challenge in the field of mobile robotics. Compared to other automatic docking methods, visual docking methods offer higher precision and lower deployment costs, making them an efficient and promising choice for this task. However, visual docking methods impose strict requirements on the robot's initial position at the start of the docking process. To overcome the limitations of current vision-based methods, we propose an innovative end-to-end visual docking method named DVDP(direct visual docking policy). This approach requires only a binocular RGB-D camera installed on the mobile robot to directly output the robot's docking path, achieving end-to-end automatic docking. Furthermore, we have collected a large-scale dataset of mobile robot visual automatic docking dataset through a combination of virtual and real environments using the Unity 3D platform and actual mobile robot setups. We developed a series of evaluation metrics to quantify the performance of the end-to-end visual docking method. Extensive experiments, including benchmarks against leading perception backbones adapted into our framework, demonstrate that our method achieves superior performance. Finally, real-world deployment on the SCOUT Mini confirmed DVDP's efficacy, with our model generating smooth, feasible docking trajectories that meet physical constraints and reach the target pose.
AeroDuo: Aerial Duo for UAV-based Vision and Language Navigation
Aug 21, 2025Aerial Vision-and-Language Navigation (VLN) is an emerging task that enables Unmanned Aerial Vehicles (UAVs) to navigate outdoor environments using natural language instructions and visual cues. However, due to the extended trajectories and complex maneuverability of UAVs, achieving reliable UAV-VLN performance is challenging and often requires human intervention or overly detailed instructions. To harness the advantages of UAVs' high mobility, which could provide multi-grained perspectives, while maintaining a manageable motion space for learning, we introduce a novel task called Dual-Altitude UAV Collaborative VLN (DuAl-VLN). In this task, two UAVs operate at distinct altitudes: a high-altitude UAV responsible for broad environmental reasoning, and a low-altitude UAV tasked with precise navigation. To support the training and evaluation of the DuAl-VLN, we construct the HaL-13k, a dataset comprising 13,838 collaborative high-low UAV demonstration trajectories, each paired with target-oriented language instructions. This dataset includes both unseen maps and an unseen object validation set to systematically evaluate the model's generalization capabilities across novel environments and unfamiliar targets. To consolidate their complementary strengths, we propose a dual-UAV collaborative VLN framework, AeroDuo, where the high-altitude UAV integrates a multimodal large language model (Pilot-LLM) for target reasoning, while the low-altitude UAV employs a lightweight multi-stage policy for navigation and target grounding. The two UAVs work collaboratively and only exchange minimal coordinate information to ensure efficiency.
CoST: Efficient Collaborative Perception From Unified Spatiotemporal Perspective
Aug 01, 2025Collaborative perception shares information among different agents and helps solving problems that individual agents may face, e.g., occlusions and small sensing range. Prior methods usually separate the multi-agent fusion and multi-time fusion into two consecutive steps. In contrast, this paper proposes an efficient collaborative perception that aggregates the observations from different agents (space) and different times into a unified spatio-temporal space simultanesouly. The unified spatio-temporal space brings two benefits, i.e., efficient feature transmission and superior feature fusion. 1) Efficient feature transmission: each static object yields a single observation in the spatial temporal space, and thus only requires transmission only once (whereas prior methods re-transmit all the object features multiple times). 2) superior feature fusion: merging the multi-agent and multi-time fusion into a unified spatial-temporal aggregation enables a more holistic perspective, thereby enhancing perception performance in challenging scenarios. Consequently, our Collaborative perception with Spatio-temporal Transformer (CoST) gains improvement in both efficiency and accuracy. Notably, CoST is not tied to any specific method and is compatible with a majority of previous methods, enhancing their accuracy while reducing the transmission bandwidth.
LLaVA-ST: A Multimodal Large Language Model for Fine-Grained Spatial-Temporal Understanding
Jan 14, 2025Recent advancements in multimodal large language models (MLLMs) have shown promising results, yet existing approaches struggle to effectively handle both temporal and spatial localization simultaneously. This challenge stems from two key issues: first, incorporating spatial-temporal localization introduces a vast number of coordinate combinations, complicating the alignment of linguistic and visual coordinate representations; second, encoding fine-grained temporal and spatial information during video feature compression is inherently difficult. To address these issues, we propose LLaVA-ST, a MLLM for fine-grained spatial-temporal multimodal understanding. In LLaVA-ST, we propose Language-Aligned Positional Embedding, which embeds the textual coordinate special token into the visual space, simplifying the alignment of fine-grained spatial-temporal correspondences. Additionally, we design the Spatial-Temporal Packer, which decouples the feature compression of temporal and spatial resolutions into two distinct point-to-region attention processing streams. Furthermore, we propose ST-Align dataset with 4.3M training samples for fine-grained spatial-temporal multimodal understanding. With ST-align, we present a progressive training pipeline that aligns the visual and textual feature through sequential coarse-to-fine stages.Additionally, we introduce an ST-Align benchmark to evaluate spatial-temporal interleaved fine-grained understanding tasks, which include Spatial-Temporal Video Grounding (STVG) , Event Localization and Captioning (ELC) and Spatial Video Grounding (SVG). LLaVA-ST achieves outstanding performance on 11 benchmarks requiring fine-grained temporal, spatial, or spatial-temporal interleaving multimodal understanding. Our code, data and benchmark will be released at Our code, data and benchmark will be released at https://github.com/appletea233/LLaVA-ST .