 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnchorSeg: Language Grounded Query Banks for Reasoning Segmentation
Apr 22, 2026Reasoning segmentation requires models to ground complex, implicit textual queries into precise pixel-level masks. Existing approaches rely on a single segmentation token $\texttt{<SEG>}$, whose hidden state implicitly encodes both semantic reasoning and spatial localization, limiting the model's ability to explicitly disentangle what to segment from where to segment. We introduce AnchorSeg, which reformulates reasoning segmentation as a structured conditional generation process over image tokens, conditioned on language grounded query banks. Instead of compressing all semantic reasoning and spatial localization into a single embedding, AnchorSeg constructs an ordered sequence of query banks: latent reasoning tokens that capture intermediate semantic states, and a segmentation anchor token that provides explicit spatial grounding. We model spatial conditioning as a factorized distribution over image tokens, where the anchor query determines localization signals while contextual queries provide semantic modulation. To bridge token-level predictions and pixel-level supervision, we propose Token--Mask Cycle Consistency (TMCC), a bidirectional training objective that enforces alignment across resolutions. By explicitly decoupling spatial grounding from semantic reasoning through structured language grounded query banks, AnchorSeg achieves state-of-the-art results on ReasonSeg test set (67.7\% gIoU and 68.1\% cIoU). All code and models are publicly available at https://github.com/rui-qian/AnchorSeg.
CoT2-Meta: Budgeted Metacognitive Control for Test-Time Reasoning
Mar 30, 2026Recent test-time reasoning methods improve performance by generating more candidate chains or searching over larger reasoning trees, but they typically lack explicit control over when to expand, what to prune, how to repair, and when to abstain. We introduce CoT2-Meta, a training-free metacognitive reasoning framework that combines object-level chain-of-thought generation with meta-level control over partial reasoning trajectories. The framework integrates four components: strategy-conditioned thought generation, tree-structured search, an online process oracle for step-level reasoning evaluation, and a meta-controller that allocates computation through expansion, pruning, repair, stopping, and fallback decisions. Under matched inference budgets, CoT2-Meta consistently outperforms strong single-path, sampling-based, and search-based baselines, including ReST-MCTS. On the default backbone, it achieves 92.8 EM on MATH, 90.4 accuracy on GPQA, 98.65 EM on GSM8K, 75.8 accuracy on BBEH, 85.6 accuracy on MMMU-Pro, and 48.8 accuracy on HLE, with gains over the strongest non-CoT2-Meta baseline of +3.6, +5.2, +1.15, +2.0, +4.3, and +4.3 points, respectively. Beyond these core results, the framework remains effective across a broader 15-benchmark suite spanning knowledge and QA, multi-hop reasoning, coding, and out-of-distribution evaluation. Additional analyses show better compute scaling, improved calibration, stronger selective prediction, targeted repair behavior, and consistent gains across backbone families. These results suggest that explicit metacognitive control is a practical design principle for reliable and compute-efficient test-time reasoning systems.
Unrewarded Exploration in Large Language Models Reveals Latent Learning from Psychology
Jan 30, 2026Latent learning, classically theorized by Tolman, shows that biological agents (e.g., rats) can acquire internal representations of their environment without rewards, enabling rapid adaptation once rewards are introduced. In contrast, from a cognitive science perspective, reward learning remains overly dependent on external feedback, limiting flexibility and generalization. Although recent advances in the reasoning capabilities of large language models (LLMs), such as OpenAI-o1 and DeepSeek-R1, mark a significant breakthrough, these models still rely primarily on reward-centric reinforcement learning paradigms. Whether and how the well-established phenomenon of latent learning in psychology can inform or emerge within LLMs' training remains largely unexplored. In this work, we present novel findings from our experiments that LLMs also exhibit the latent learning dynamics. During an initial phase of unrewarded exploration, LLMs display modest performance improvements, as this phase allows LLMs to organize task-relevant knowledge without being constrained by reward-driven biases, and performance is further enhanced once rewards are introduced. LLMs post-trained under this two-stage exploration regime ultimately achieve higher competence than those post-trained with reward-based reinforcement learning throughout. Beyond these empirical observations, we also provide theoretical analyses for our experiments explaining why unrewarded exploration yields performance gains, offering a mechanistic account of these dynamics. Specifically, we conducted extensive experiments across multiple model families and diverse task domains to establish the existence of the latent learning dynamics in LLMs.
STARC: See-Through-Wall Augmented Reality Framework for Human-Robot Collaboration in Emergency Response
Sep 19, 2025In emergency response missions, first responders must navigate cluttered indoor environments where occlusions block direct line-of-sight, concealing both life-threatening hazards and victims in need of rescue. We present STARC, a see-through AR framework for human-robot collaboration that fuses mobile-robot mapping with responder-mounted LiDAR sensing. A ground robot running LiDAR-inertial odometry performs large-area exploration and 3D human detection, while helmet- or handheld-mounted LiDAR on the responder is registered to the robot's global map via relative pose estimation. This cross-LiDAR alignment enables consistent first-person projection of detected humans and their point clouds - rendered in AR with low latency - into the responder's view. By providing real-time visualization of hidden occupants and hazards, STARC enhances situational awareness and reduces operator risk. Experiments in simulation, lab setups, and tactical field trials confirm robust pose alignment, reliable detections, and stable overlays, underscoring the potential of our system for fire-fighting, disaster relief, and other safety-critical operations. Code and design will be open-sourced upon acceptance.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
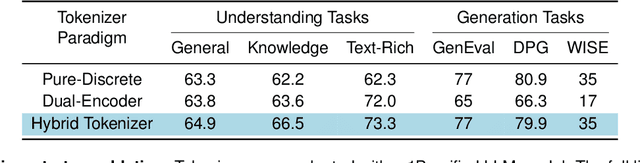
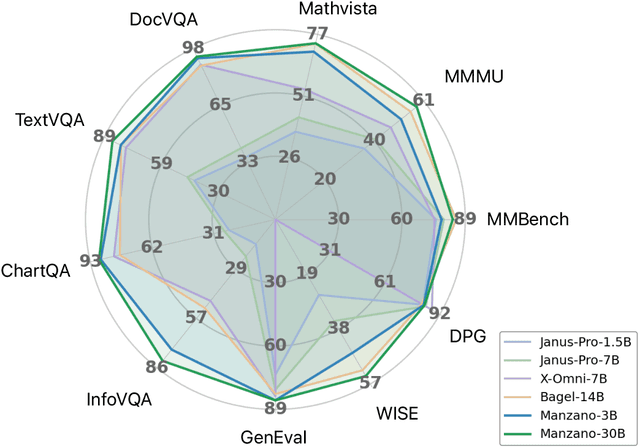
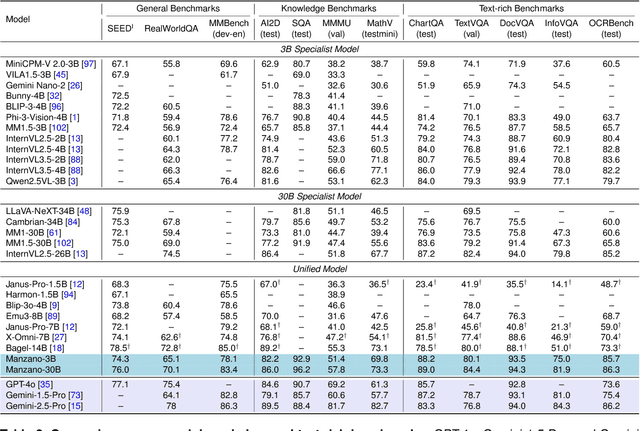
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
Energy-Constrained Navigation for Planetary Rovers under Hybrid RTG-Solar Power
Sep 18, 2025Future planetary exploration rovers must operate for extended durations on hybrid power inputs that combine steady radioisotope thermoelectric generator (RTG) output with variable solar photovoltaic (PV) availability. While energy-aware planning has been studied for aerial and underwater robots under battery limits, few works for ground rovers explicitly model power flow or enforce instantaneous power constraints. Classical terrain-aware planners emphasize slope or traversability, and trajectory optimization methods typically focus on geometric smoothness and dynamic feasibility, neglecting energy feasibility. We present an energy-constrained trajectory planning framework that explicitly integrates physics-based models of translational, rotational, and resistive power with baseline subsystem loads, under hybrid RTG-solar input. By incorporating both cumulative energy budgets and instantaneous power constraints into SE(2)-based polynomial trajectory optimization, the method ensures trajectories that are simultaneously smooth, dynamically feasible, and power-compliant. Simulation results on lunar-like terrain show that our planner generates trajectories with peak power within 0.55 percent of the prescribed limit, while existing methods exceed limits by over 17 percent. This demonstrates a principled and practical approach to energy-aware autonomy for long-duration planetary missions.
CogStream: Context-guided Streaming Video Question Answering
Jun 12, 2025



Despite advancements in Video Large Language Models (Vid-LLMs) improving multimodal understanding, challenges persist in streaming video reasoning due to its reliance on contextual information. Existing paradigms feed all available historical contextual information into Vid-LLMs, resulting in a significant computational burden for visual data processing. Furthermore, the inclusion of irrelevant context distracts models from key details. This paper introduces a challenging task called Context-guided Streaming Video Reasoning (CogStream), which simulates real-world streaming video scenarios, requiring models to identify the most relevant historical contextual information to deduce answers for questions about the current stream. To support CogStream, we present a densely annotated dataset featuring extensive and hierarchical question-answer pairs, generated by a semi-automatic pipeline. Additionally, we present CogReasoner as a baseline model. It efficiently tackles this task by leveraging visual stream compression and historical dialogue retrieval. Extensive experiments prove the effectiveness of this method. Code will be released soon.
Seed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
FA-BARF: Frequency Adapted Bundle-Adjusting Neural Radiance Fields
Mar 15, 2025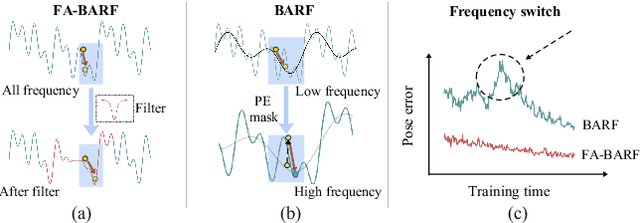
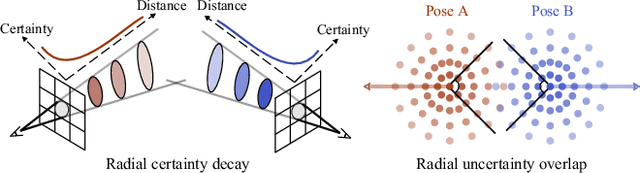
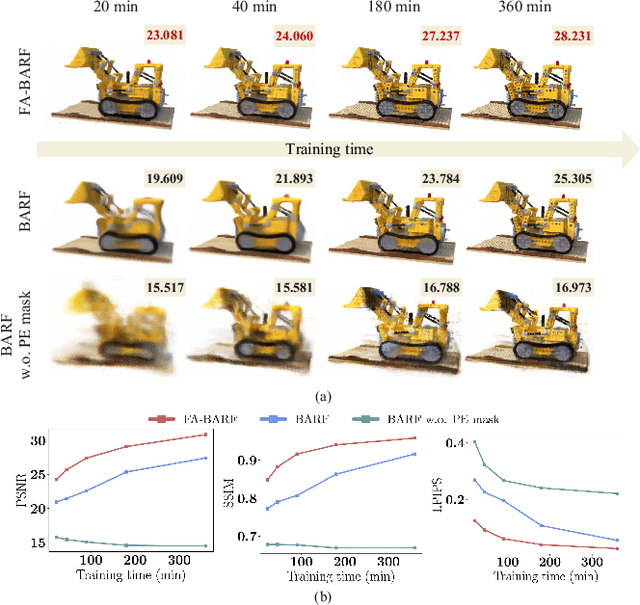
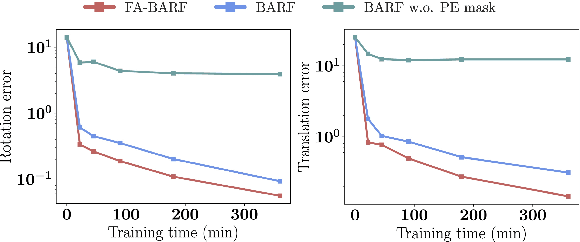
Neural Radiance Fields (NeRF) have exhibited highly effective performance for photorealistic novel view synthesis recently. However, the key limitation it meets is the reliance on a hand-crafted frequency annealing strategy to recover 3D scenes with imperfect camera poses. The strategy exploits a temporal low-pass filter to guarantee convergence while decelerating the joint optimization of implicit scene reconstruction and camera registration. In this work, we introduce the Frequency Adapted Bundle Adjusting Radiance Field (FA-BARF), substituting the temporal low-pass filter for a frequency-adapted spatial low-pass filter to address the decelerating problem. We establish a theoretical framework to interpret the relationship between position encoding of NeRF and camera registration and show that our frequency-adapted filter can mitigate frequency fluctuation caused by the temporal filter. Furthermore, we show that applying a spatial low-pass filter in NeRF can optimize camera poses productively through radial uncertainty overlaps among various views. Extensive experiments show that FA-BARF can accelerate the joint optimization process under little perturbations in object-centric scenes and recover real-world scenes with unknown camera poses. This implies wider possibilities for NeRF applied in dense 3D mapping and reconstruction under real-time requirements. The code will be released upon paper acceptance.
DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation
Mar 13, 2025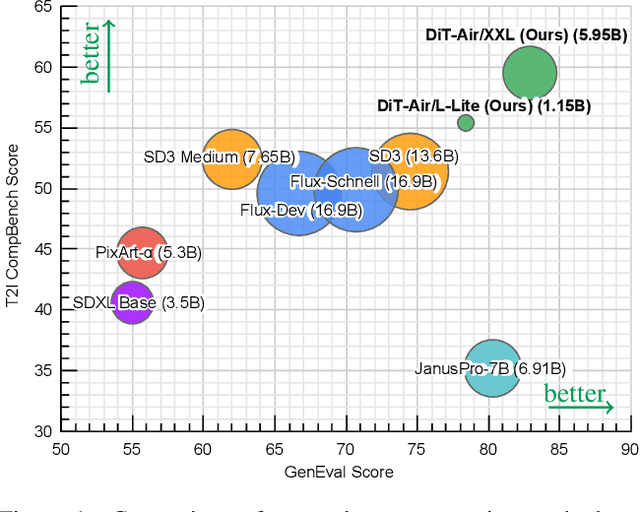



In this work, we empirically study Diffusion Transformers (DiTs) for text-to-image generation, focusing on architectural choices, text-conditioning strategies, and training protocols. We evaluate a range of DiT-based architectures--including PixArt-style and MMDiT variants--and compare them with a standard DiT variant which directly processes concatenated text and noise inputs. Surprisingly, our findings reveal that the performance of standard DiT is comparable with those specialized models, while demonstrating superior parameter-efficiency, especially when scaled up. Leveraging the layer-wise parameter sharing strategy, we achieve a further reduction of 66% in model size compared to an MMDiT architecture, with minimal performance impact. Building on an in-depth analysis of critical components such as text encoders and Variational Auto-Encoders (VAEs), we introduce DiT-Air and DiT-Air-Lite. With supervised and reward fine-tuning, DiT-Air achieves state-of-the-art performance on GenEval and T2I CompBench, while DiT-Air-Lite remains highly competitive, surpassing most existing models despite its compact size.