 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGIE-Bench: Towards Grounded Evaluation for Text-Guided Image Editing
May 16, 2025



Editing images using natural language instructions has become a natural and expressive way to modify visual content; yet, evaluating the performance of such models remains challenging. Existing evaluation approaches often rely on image-text similarity metrics like CLIP, which lack precision. In this work, we introduce a new benchmark designed to evaluate text-guided image editing models in a more grounded manner, along two critical dimensions: (i) functional correctness, assessed via automatically generated multiple-choice questions that verify whether the intended change was successfully applied; and (ii) image content preservation, which ensures that non-targeted regions of the image remain visually consistent using an object-aware masking technique and preservation scoring. The benchmark includes over 1000 high-quality editing examples across 20 diverse content categories, each annotated with detailed editing instructions, evaluation questions, and spatial object masks. We conduct a large-scale study comparing GPT-Image-1, the latest flagship in the text-guided image editing space, against several state-of-the-art editing models, and validate our automatic metrics against human ratings. Results show that GPT-Image-1 leads in instruction-following accuracy, but often over-modifies irrelevant image regions, highlighting a key trade-off in the current model behavior. GIE-Bench provides a scalable, reproducible framework for advancing more accurate evaluation of text-guided image editing.
UniVG: A Generalist Diffusion Model for Unified Image Generation and Editing
Mar 16, 2025Text-to-Image (T2I) diffusion models have shown impressive results in generating visually compelling images following user prompts. Building on this, various methods further fine-tune the pre-trained T2I model for specific tasks. However, this requires separate model architectures, training designs, and multiple parameter sets to handle different tasks. In this paper, we introduce UniVG, a generalist diffusion model capable of supporting a diverse range of image generation tasks with a single set of weights. UniVG treats multi-modal inputs as unified conditions to enable various downstream applications, ranging from T2I generation, inpainting, instruction-based editing, identity-preserving generation, and layout-guided generation, to depth estimation and referring segmentation. Through comprehensive empirical studies on data mixing and multi-task training, we provide detailed insights into the training processes and decisions that inform our final designs. For example, we show that T2I generation and other tasks, such as instruction-based editing, can coexist without performance trade-offs, while auxiliary tasks like depth estimation and referring segmentation enhance image editing. Notably, our model can even outperform some task-specific models on their respective benchmarks, marking a significant step towards a unified image generation model.
DiT-Air: Revisiting the Efficiency of Diffusion Model Architecture Design in Text to Image Generation
Mar 13, 2025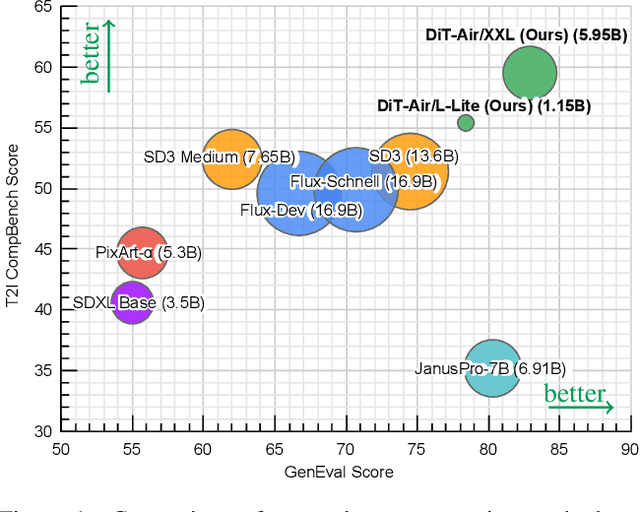



In this work, we empirically study Diffusion Transformers (DiTs) for text-to-image generation, focusing on architectural choices, text-conditioning strategies, and training protocols. We evaluate a range of DiT-based architectures--including PixArt-style and MMDiT variants--and compare them with a standard DiT variant which directly processes concatenated text and noise inputs. Surprisingly, our findings reveal that the performance of standard DiT is comparable with those specialized models, while demonstrating superior parameter-efficiency, especially when scaled up. Leveraging the layer-wise parameter sharing strategy, we achieve a further reduction of 66% in model size compared to an MMDiT architecture, with minimal performance impact. Building on an in-depth analysis of critical components such as text encoders and Variational Auto-Encoders (VAEs), we introduce DiT-Air and DiT-Air-Lite. With supervised and reward fine-tuning, DiT-Air achieves state-of-the-art performance on GenEval and T2I CompBench, while DiT-Air-Lite remains highly competitive, surpassing most existing models despite its compact size.
STIV: Scalable Text and Image Conditioned Video Generation
Dec 10, 2024The field of video generation has made remarkable advancements, yet there remains a pressing need for a clear, systematic recipe that can guide the development of robust and scalable models. In this work, we present a comprehensive study that systematically explores the interplay of model architectures, training recipes, and data curation strategies, culminating in a simple and scalable text-image-conditioned video generation method, named STIV. Our framework integrates image condition into a Diffusion Transformer (DiT) through frame replacement, while incorporating text conditioning via a joint image-text conditional classifier-free guidance. This design enables STIV to perform both text-to-video (T2V) and text-image-to-video (TI2V) tasks simultaneously. Additionally, STIV can be easily extended to various applications, such as video prediction, frame interpolation, multi-view generation, and long video generation, etc. With comprehensive ablation studies on T2I, T2V, and TI2V, STIV demonstrate strong performance, despite its simple design. An 8.7B model with 512 resolution achieves 83.1 on VBench T2V, surpassing both leading open and closed-source models like CogVideoX-5B, Pika, Kling, and Gen-3. The same-sized model also achieves a state-of-the-art result of 90.1 on VBench I2V task at 512 resolution. By providing a transparent and extensible recipe for building cutting-edge video generation models, we aim to empower future research and accelerate progress toward more versatile and reliable video generation solutions.
T2V-Turbo: Breaking the Quality Bottleneck of Video Consistency Model with Mixed Reward Feedback
May 29, 2024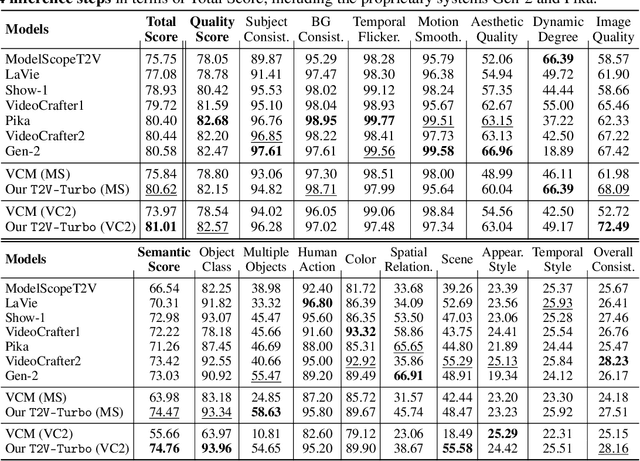
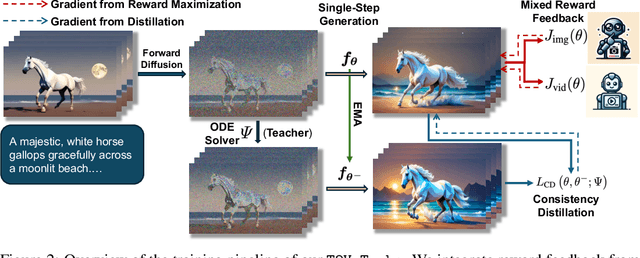
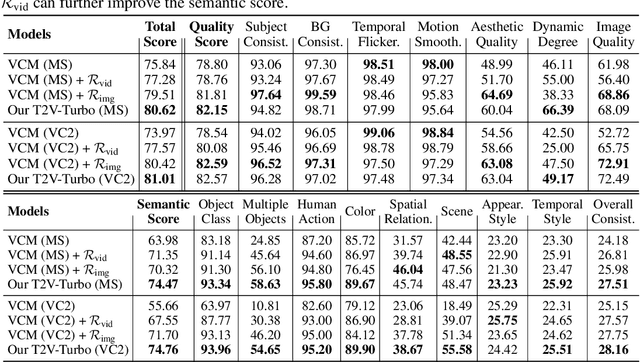
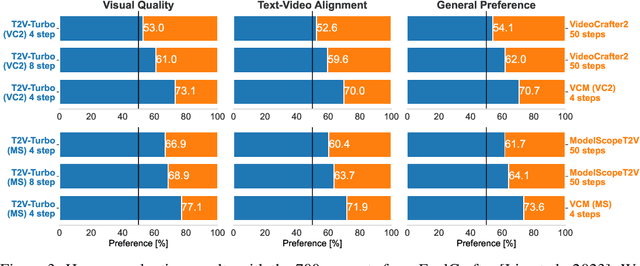
Diffusion-based text-to-video (T2V) models have achieved significant success but continue to be hampered by the slow sampling speed of their iterative sampling processes. To address the challenge, consistency models have been proposed to facilitate fast inference, albeit at the cost of sample quality. In this work, we aim to break the quality bottleneck of a video consistency model (VCM) to achieve $\textbf{both fast and high-quality video generation}$. We introduce T2V-Turbo, which integrates feedback from a mixture of differentiable reward models into the consistency distillation (CD) process of a pre-trained T2V model. Notably, we directly optimize rewards associated with single-step generations that arise naturally from computing the CD loss, effectively bypassing the memory constraints imposed by backpropagating gradients through an iterative sampling process. Remarkably, the 4-step generations from our T2V-Turbo achieve the highest total score on VBench, even surpassing Gen-2 and Pika. We further conduct human evaluations to corroborate the results, validating that the 4-step generations from our T2V-Turbo are preferred over the 50-step DDIM samples from their teacher models, representing more than a tenfold acceleration while improving video generation quality.
From Text to Pixel: Advancing Long-Context Understanding in MLLMs
May 23, 2024



The rapid progress in Multimodal Large Language Models (MLLMs) has significantly advanced their ability to process and understand complex visual and textual information. However, the integration of multiple images and extensive textual contexts remains a challenge due to the inherent limitation of the models' capacity to handle long input sequences efficiently. In this paper, we introduce SEEKER, a multimodal large language model designed to tackle this issue. SEEKER aims to optimize the compact encoding of long text by compressing the text sequence into the visual pixel space via images, enabling the model to handle long text within a fixed token-length budget efficiently. Our empirical experiments on six long-context multimodal tasks demonstrate that SEEKER can leverage fewer image tokens to convey the same amount of textual information compared with the OCR-based approach, and is more efficient in understanding long-form multimodal input and generating long-form textual output, outperforming all existing proprietary and open-source MLLMs by large margins.
Ferret-v2: An Improved Baseline for Referring and Grounding with Large Language Models
Apr 11, 2024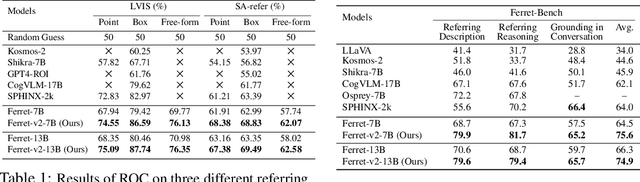
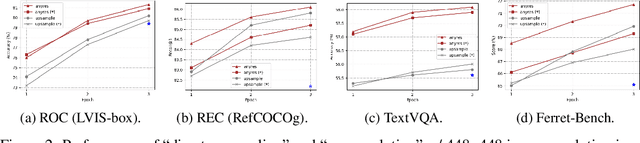
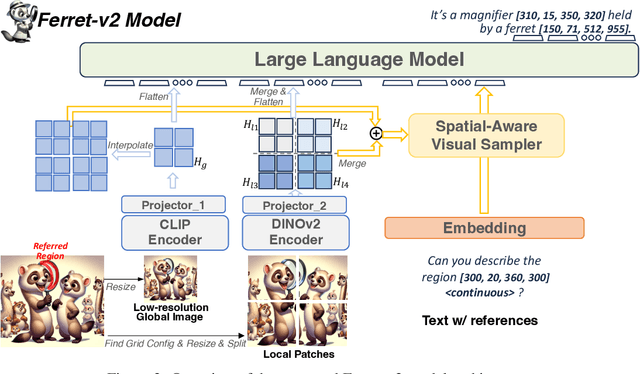
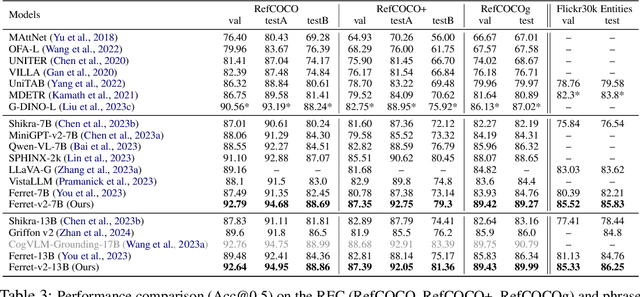
While Ferret seamlessly integrates regional understanding into the Large Language Model (LLM) to facilitate its referring and grounding capability, it poses certain limitations: constrained by the pre-trained fixed visual encoder and failed to perform well on broader tasks. In this work, we unveil Ferret-v2, a significant upgrade to Ferret, with three key designs. (1) Any resolution grounding and referring: A flexible approach that effortlessly handles higher image resolution, improving the model's ability to process and understand images in greater detail. (2) Multi-granularity visual encoding: By integrating the additional DINOv2 encoder, the model learns better and diverse underlying contexts for global and fine-grained visual information. (3) A three-stage training paradigm: Besides image-caption alignment, an additional stage is proposed for high-resolution dense alignment before the final instruction tuning. Experiments show that Ferret-v2 provides substantial improvements over Ferret and other state-of-the-art methods, thanks to its high-resolution scaling and fine-grained visual processing.
Guiding Instruction-based Image Editing via Multimodal Large Language Models
Sep 29, 2023Instruction-based image editing improves the controllability and flexibility of image manipulation via natural commands without elaborate descriptions or regional masks. However, human instructions are sometimes too brief for current methods to capture and follow. Multimodal large language models (MLLMs) show promising capabilities in cross-modal understanding and visual-aware response generation via LMs. We investigate how MLLMs facilitate edit instructions and present MLLM-Guided Image Editing (MGIE). MGIE learns to derive expressive instructions and provides explicit guidance. The editing model jointly captures this visual imagination and performs manipulation through end-to-end training. We evaluate various aspects of Photoshop-style modification, global photo optimization, and local editing. Extensive experimental results demonstrate that expressive instructions are crucial to instruction-based image editing, and our MGIE can lead to a notable improvement in automatic metrics and human evaluation while maintaining competitive inference efficiency.
VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View
Jul 12, 2023
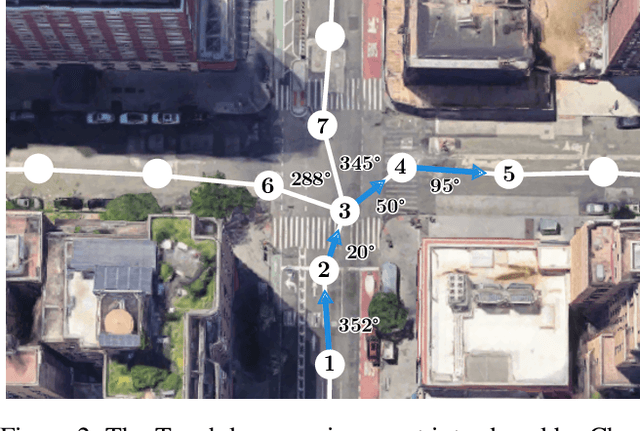
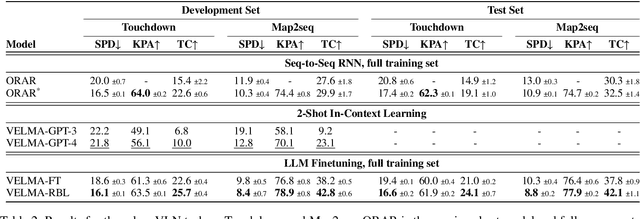
Incremental decision making in real-world environments is one of the most challenging tasks in embodied artificial intelligence. One particularly demanding scenario is Vision and Language Navigation~(VLN) which requires visual and natural language understanding as well as spatial and temporal reasoning capabilities. The embodied agent needs to ground its understanding of navigation instructions in observations of a real-world environment like Street View. Despite the impressive results of LLMs in other research areas, it is an ongoing problem of how to best connect them with an interactive visual environment. In this work, we propose VELMA, an embodied LLM agent that uses a verbalization of the trajectory and of visual environment observations as contextual prompt for the next action. Visual information is verbalized by a pipeline that extracts landmarks from the human written navigation instructions and uses CLIP to determine their visibility in the current panorama view. We show that VELMA is able to successfully follow navigation instructions in Street View with only two in-context examples. We further finetune the LLM agent on a few thousand examples and achieve 25%-30% relative improvement in task completion over the previous state-of-the-art for two datasets.
Photoswap: Personalized Subject Swapping in Images
May 29, 2023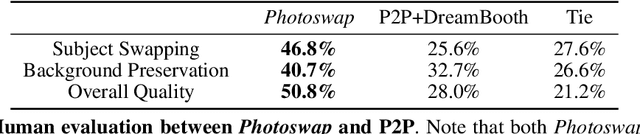
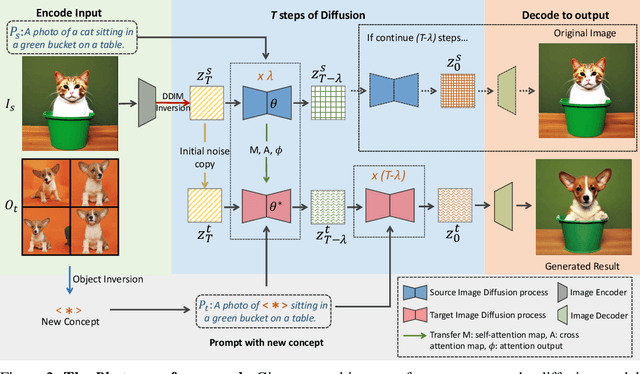
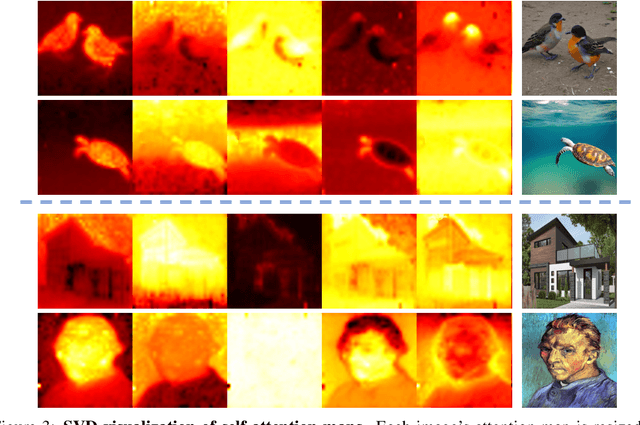
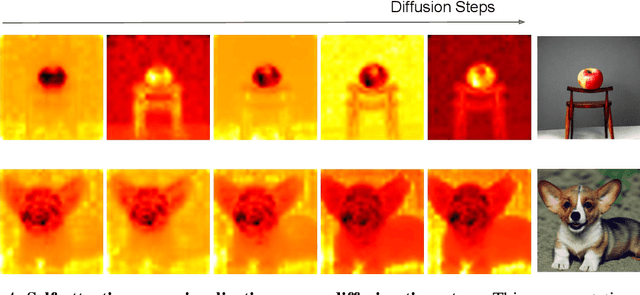
In an era where images and visual content dominate our digital landscape, the ability to manipulate and personalize these images has become a necessity. Envision seamlessly substituting a tabby cat lounging on a sunlit window sill in a photograph with your own playful puppy, all while preserving the original charm and composition of the image. We present Photoswap, a novel approach that enables this immersive image editing experience through personalized subject swapping in existing images. Photoswap first learns the visual concept of the subject from reference images and then swaps it into the target image using pre-trained diffusion models in a training-free manner. We establish that a well-conceptualized visual subject can be seamlessly transferred to any image with appropriate self-attention and cross-attention manipulation, maintaining the pose of the swapped subject and the overall coherence of the image. Comprehensive experiments underscore the efficacy and controllability of Photoswap in personalized subject swapping. Furthermore, Photoswap significantly outperforms baseline methods in human ratings across subject swapping, background preservation, and overall quality, revealing its vast application potential, from entertainment to professional editing.