 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbedding-Space Data Augmentation to Prevent Membership Inference Attacks in Clinical Time Series Forecasting
Nov 07, 2025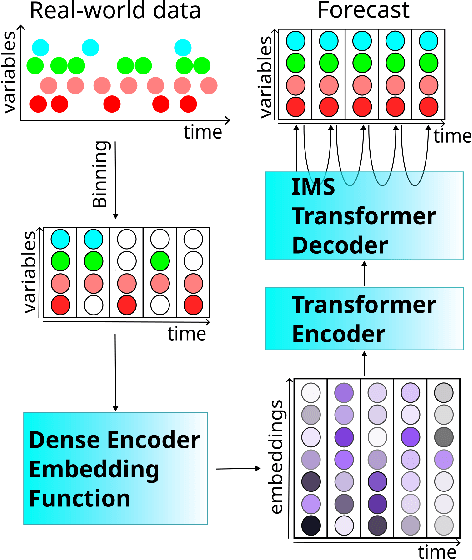
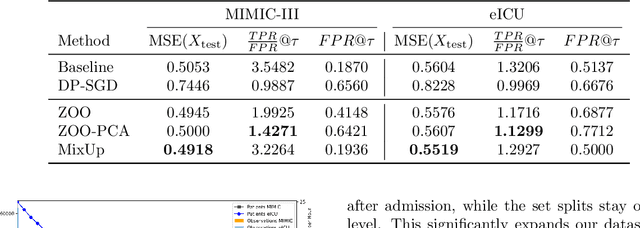
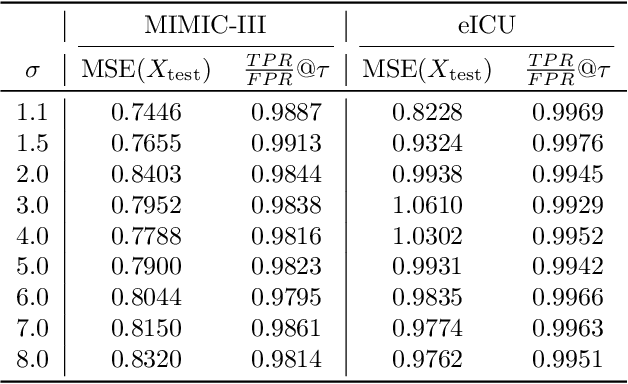
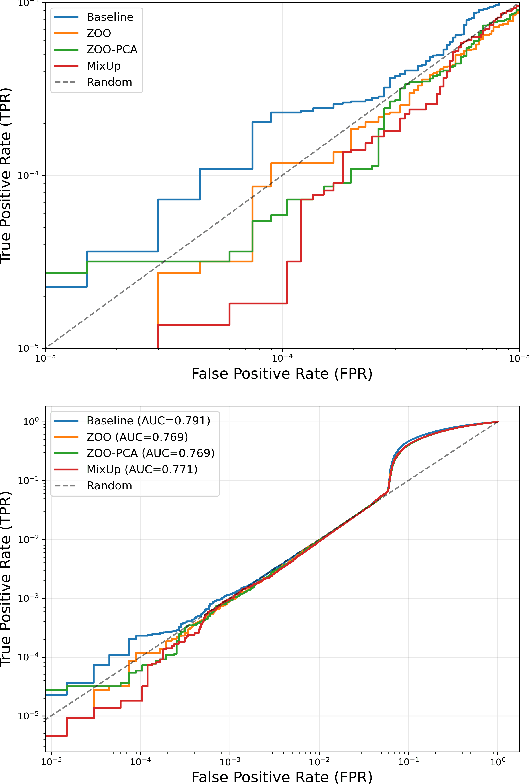
Balancing strong privacy guarantees with high predictive performance is critical for time series forecasting (TSF) tasks involving Electronic Health Records (EHR). In this study, we explore how data augmentation can mitigate Membership Inference Attacks (MIA) on TSF models. We show that retraining with synthetic data can substantially reduce the effectiveness of loss-based MIAs by reducing the attacker's true-positive to false-positive ratio. The key challenge is generating synthetic samples that closely resemble the original training data to confuse the attacker, while also introducing enough novelty to enhance the model's ability to generalize to unseen data. We examine multiple augmentation strategies - Zeroth-Order Optimization (ZOO), a variant of ZOO constrained by Principal Component Analysis (ZOO-PCA), and MixUp - to strengthen model resilience without sacrificing accuracy. Our experimental results show that ZOO-PCA yields the best reductions in TPR/FPR ratio for MIA attacks without sacrificing performance on test data.
Compositionality in Time Series: A Proof of Concept using Symbolic Dynamics and Compositional Data Augmentation
Aug 28, 2025This work investigates whether time series of natural phenomena can be understood as being generated by sequences of latent states which are ordered in systematic and regular ways. We focus on clinical time series and ask whether clinical measurements can be interpreted as being generated by meaningful physiological states whose succession follows systematic principles. Uncovering the underlying compositional structure will allow us to create synthetic data to alleviate the notorious problem of sparse and low-resource data settings in clinical time series forecasting, and deepen our understanding of clinical data. We start by conceptualizing compositionality for time series as a property of the data generation process, and then study data-driven procedures that can reconstruct the elementary states and composition rules of this process. We evaluate the success of this methods using two empirical tests originating from a domain adaptation perspective. Both tests infer the similarity of the original time series distribution and the synthetic time series distribution from the similarity of expected risk of time series forecasting models trained and tested on original and synthesized data in specific ways. Our experimental results show that the test set performance achieved by training on compositionally synthesized data is comparable to training on original clinical time series data, and that evaluation of models on compositionally synthesized test data shows similar results to evaluating on original test data, outperforming randomization-based data augmentation. An additional downstream evaluation of the prediction task of sequential organ failure assessment (SOFA) scores shows significant performance gains when model training is entirely based on compositionally synthesized data compared to training on original data.
Post-edits Are Preferences Too
Oct 03, 2024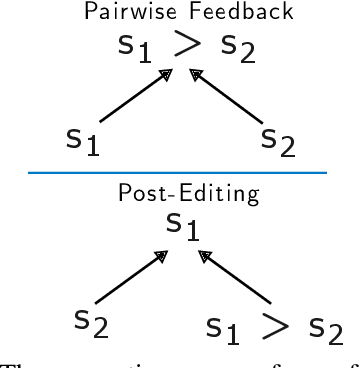
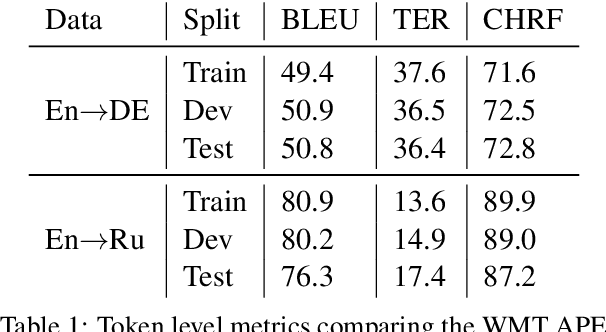
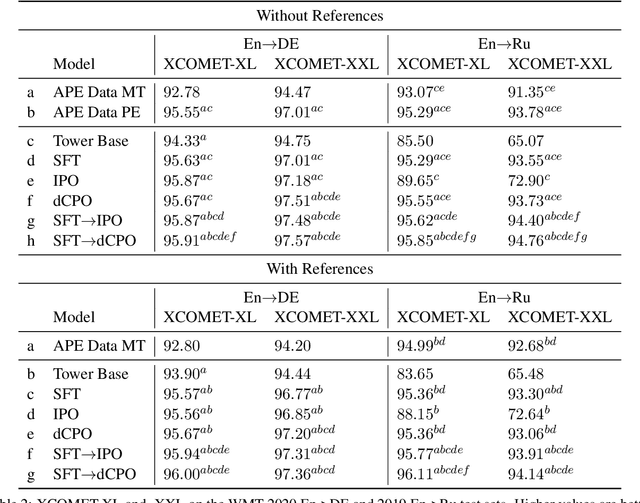
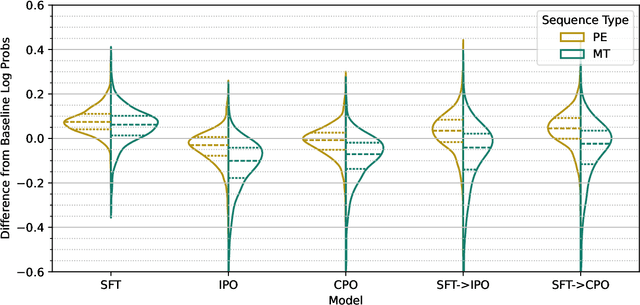
Preference Optimization (PO) techniques are currently one of the state of the art techniques for fine-tuning large language models (LLMs) on pairwise preference feedback from human annotators. However, in machine translation, this sort of feedback can be difficult to solicit. Additionally, Kreutzer et al. (2018) have shown that, for machine translation, pairwise preferences are less reliable than other forms of human feedback, such as 5-point ratings. We examine post-edits to see if they can be a source of reliable human preferences by construction. In PO, a human annotator is shown sequences $s_1$ and $s_2$ and asked for a preference judgment, %$s_1 > s_2$; while for post-editing, editors \emph{create} $s_1$ and know that it should be better than $s_2$. We attempt to use these implicit preferences for PO and show that it helps the model move towards post-edit-like hypotheses and away from machine translation-like hypotheses. Furthermore, we show that best results are obtained by pre-training the model with supervised fine-tuning (SFT) on post-edits in order to promote post-edit-like hypotheses to the top output ranks.
Early Prediction of Causes (not Effects) in Healthcare by Long-Term Clinical Time Series Forecasting
Aug 07, 2024Machine learning for early syndrome diagnosis aims to solve the intricate task of predicting a ground truth label that most often is the outcome (effect) of a medical consensus definition applied to observed clinical measurements (causes), given clinical measurements observed several hours before. Instead of focusing on the prediction of the future effect, we propose to directly predict the causes via time series forecasting (TSF) of clinical variables and determine the effect by applying the gold standard consensus definition to the forecasted values. This method has the invaluable advantage of being straightforwardly interpretable to clinical practitioners, and because model training does not rely on a particular label anymore, the forecasted data can be used to predict any consensus-based label. We exemplify our method by means of long-term TSF with Transformer models, with a focus on accurate prediction of sparse clinical variables involved in the SOFA-based Sepsis-3 definition and the new Simplified Acute Physiology Score (SAPS-II) definition. Our experiments are conducted on two datasets and show that contrary to recent proposals which advocate set function encoders for time series and direct multi-step decoders, best results are achieved by a combination of standard dense encoders with iterative multi-step decoders. The key for success of iterative multi-step decoding can be attributed to its ability to capture cross-variate dependencies and to a student forcing training strategy that teaches the model to rely on its own previous time step predictions for the next time step prediction.
Prompting Large Language Models with Human Error Markings for Self-Correcting Machine Translation
Jun 04, 2024


While large language models (LLMs) pre-trained on massive amounts of unpaired language data have reached the state-of-the-art in machine translation (MT) of general domain texts, post-editing (PE) is still required to correct errors and to enhance term translation quality in specialized domains. In this paper we present a pilot study of enhancing translation memories (TM) produced by PE (source segments, machine translations, and reference translations, henceforth called PE-TM) for the needs of correct and consistent term translation in technical domains. We investigate a light-weight two-step scenario where, at inference time, a human translator marks errors in the first translation step, and in a second step a few similar examples are extracted from the PE-TM to prompt an LLM. Our experiment shows that the additional effort of augmenting translations with human error markings guides the LLM to focus on a correction of the marked errors, yielding consistent improvements over automatic PE (APE) and MT from scratch.
Validity problems in clinical machine learning by indirect data labeling using consensus definitions
Nov 06, 2023
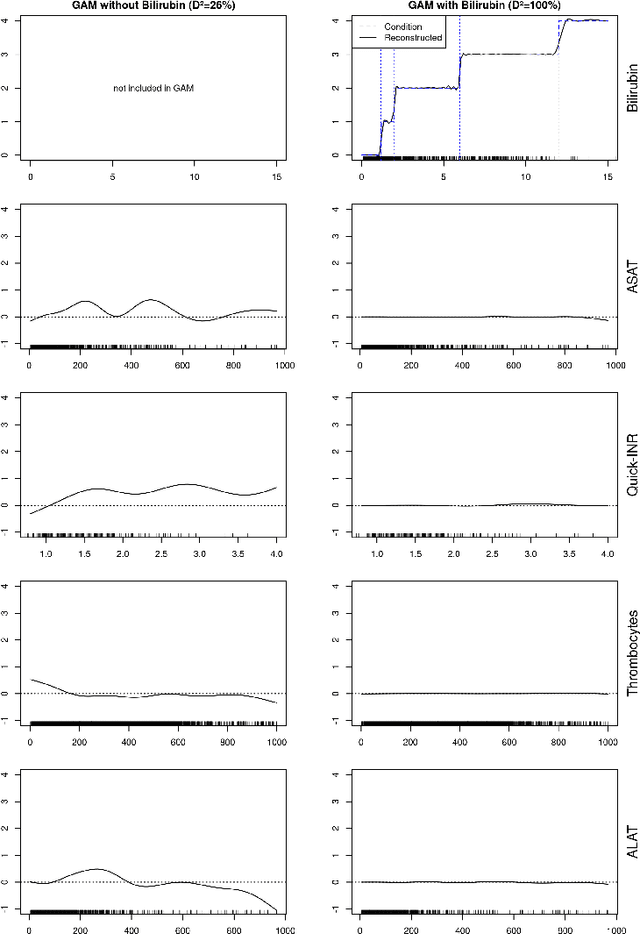

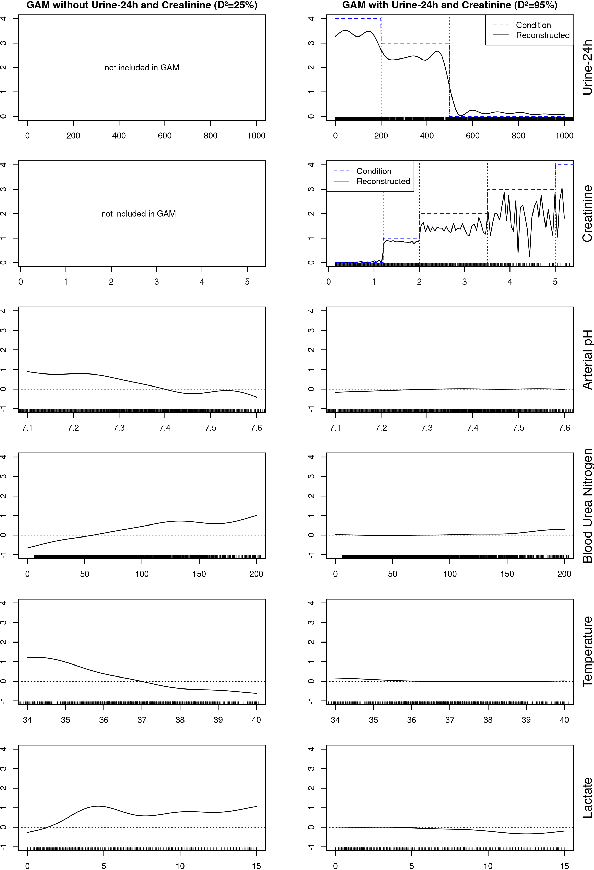
We demonstrate a validity problem of machine learning in the vital application area of disease diagnosis in medicine. It arises when target labels in training data are determined by an indirect measurement, and the fundamental measurements needed to determine this indirect measurement are included in the input data representation. Machine learning models trained on this data will learn nothing else but to exactly reconstruct the known target definition. Such models show perfect performance on similarly constructed test data but will fail catastrophically on real-world examples where the defining fundamental measurements are not or only incompletely available. We present a general procedure allowing identification of problematic datasets and black-box machine learning models trained on them, and exemplify our detection procedure on the task of early prediction of sepsis.
Text-to-OverpassQL: A Natural Language Interface for Complex Geodata Querying of OpenStreetMap
Aug 30, 2023We present Text-to-OverpassQL, a task designed to facilitate a natural language interface for querying geodata from OpenStreetMap (OSM). The Overpass Query Language (OverpassQL) allows users to formulate complex database queries and is widely adopted in the OSM ecosystem. Generating Overpass queries from natural language input serves multiple use-cases. It enables novice users to utilize OverpassQL without prior knowledge, assists experienced users with crafting advanced queries, and enables tool-augmented large language models to access information stored in the OSM database. In order to assess the performance of current sequence generation models on this task, we propose OverpassNL, a dataset of 8,352 queries with corresponding natural language inputs. We further introduce task specific evaluation metrics and ground the evaluation of the Text-to-OverpassQL task by executing the queries against the OSM database. We establish strong baselines by finetuning sequence-to-sequence models and adapting large language models with in-context examples. The detailed evaluation reveals strengths and weaknesses of the considered learning strategies, laying the foundations for further research into the Text-to-OverpassQL task.
Improving End-to-End Speech Translation by Imitation-Based Knowledge Distillation with Synthetic Transcripts
Jul 17, 2023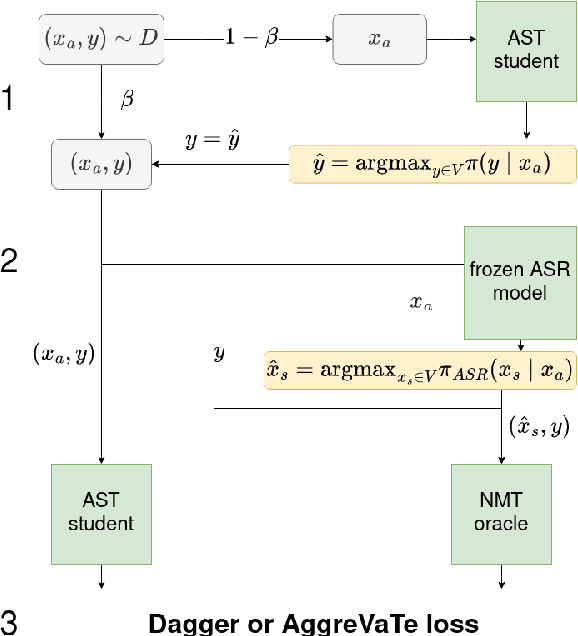
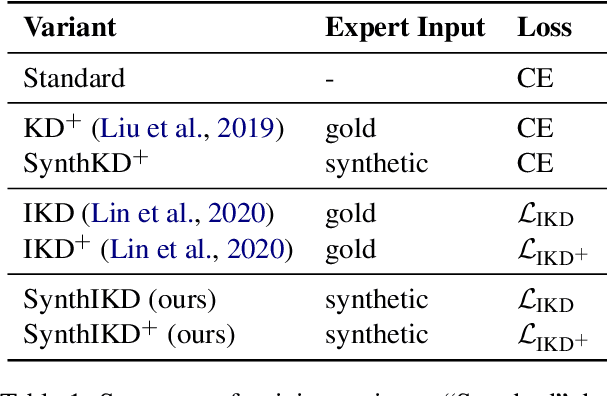

End-to-end automatic speech translation (AST) relies on data that combines audio inputs with text translation outputs. Previous work used existing large parallel corpora of transcriptions and translations in a knowledge distillation (KD) setup to distill a neural machine translation (NMT) into an AST student model. While KD allows using larger pretrained models, the reliance of previous KD approaches on manual audio transcripts in the data pipeline restricts the applicability of this framework to AST. We present an imitation learning approach where a teacher NMT system corrects the errors of an AST student without relying on manual transcripts. We show that the NMT teacher can recover from errors in automatic transcriptions and is able to correct erroneous translations of the AST student, leading to improvements of about 4 BLEU points over the standard AST end-to-end baseline on the English-German CoVoST-2 and MuST-C datasets, respectively. Code and data are publicly available.\footnote{\url{https://github.com/HubReb/imitkd_ast/releases/tag/v1.1}}
* IWSLT 2023, corrected version
Enhancing Supervised Learning with Contrastive Markings in Neural Machine Translation Training
Jul 17, 2023Supervised learning in Neural Machine Translation (NMT) typically follows a teacher forcing paradigm where reference tokens constitute the conditioning context in the model's prediction, instead of its own previous predictions. In order to alleviate this lack of exploration in the space of translations, we present a simple extension of standard maximum likelihood estimation by a contrastive marking objective. The additional training signals are extracted automatically from reference translations by comparing the system hypothesis against the reference, and used for up/down-weighting correct/incorrect tokens. The proposed new training procedure requires one additional translation pass over the training set per epoch, and does not alter the standard inference setup. We show that training with contrastive markings yields improvements on top of supervised learning, and is especially useful when learning from postedits where contrastive markings indicate human error corrections to the original hypotheses. Code is publicly released.
VELMA: Verbalization Embodiment of LLM Agents for Vision and Language Navigation in Street View
Jul 12, 2023
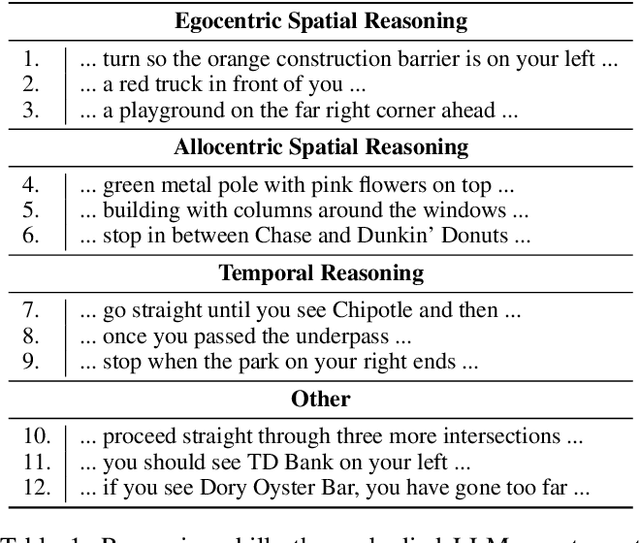
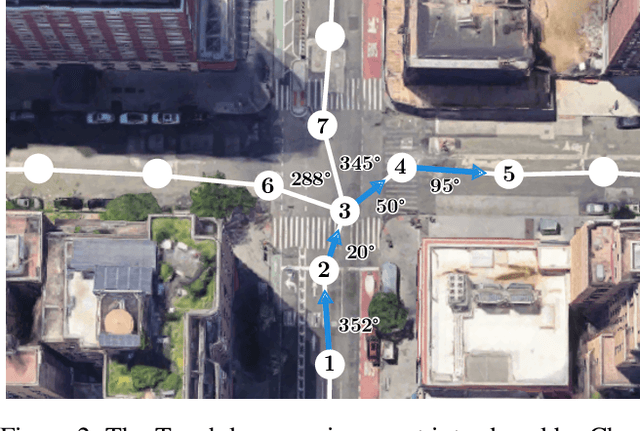
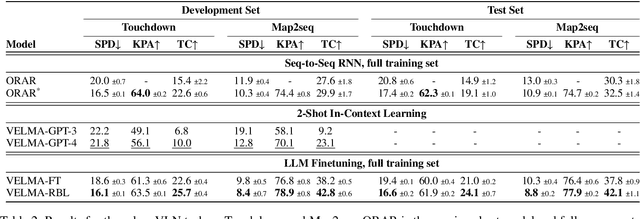
Incremental decision making in real-world environments is one of the most challenging tasks in embodied artificial intelligence. One particularly demanding scenario is Vision and Language Navigation~(VLN) which requires visual and natural language understanding as well as spatial and temporal reasoning capabilities. The embodied agent needs to ground its understanding of navigation instructions in observations of a real-world environment like Street View. Despite the impressive results of LLMs in other research areas, it is an ongoing problem of how to best connect them with an interactive visual environment. In this work, we propose VELMA, an embodied LLM agent that uses a verbalization of the trajectory and of visual environment observations as contextual prompt for the next action. Visual information is verbalized by a pipeline that extracts landmarks from the human written navigation instructions and uses CLIP to determine their visibility in the current panorama view. We show that VELMA is able to successfully follow navigation instructions in Street View with only two in-context examples. We further finetune the LLM agent on a few thousand examples and achieve 25%-30% relative improvement in task completion over the previous state-of-the-art for two datasets.