 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF-Actor: Controllable Conversational Behaviour in Full-Duplex Models
Jan 16, 2026Spoken conversational systems require more than accurate speech generation to have human-like conversations: to feel natural and engaging, they must produce conversational behaviour that adapts dynamically to the context. Current spoken conversational systems, however, rarely allow such customization, limiting their naturalness and usability. In this work, we present the first open, instruction-following full-duplex conversational speech model that can be trained efficiently under typical academic resource constraints. By keeping the audio encoder frozen and finetuning only the language model, our model requires just 2,000 hours of data, without relying on large-scale pretraining or multi-stage optimization. The model can follow explicit instructions to control speaker voice, conversation topic, conversational behaviour (e.g., backchanneling and interruptions), and dialogue initiation. We propose a single-stage training protocol and systematically analyze design choices. Both the model and training code will be released to enable reproducible research on controllable full-duplex speech systems.
From TOWER to SPIRE: Adding the Speech Modality to a Text-Only LLM
Mar 13, 2025Large language models (LLMs) have shown remarkable performance and generalization capabilities across multiple languages and tasks, making them very attractive targets for multi-modality integration (e.g., images or speech). In this work, we extend an existing LLM to the speech modality via speech discretization and continued pre-training. In particular, we are interested in multilingual LLMs, such as TOWER, as their pre-training setting allows us to treat discretized speech input as an additional translation language. The resulting open-source model, SPIRE, is able to transcribe and translate English speech input while maintaining TOWER's original performance on translation-related tasks, showcasing that discretized speech input integration as an additional language is feasible during LLM adaptation. We make our code and models available to the community.
Prepending or Cross-Attention for Speech-to-Text? An Empirical Comparison
Jan 04, 2025



Following the remarkable success of Large Language Models (LLMs) in NLP tasks, there is increasing interest in extending their capabilities to speech -- the most common form in communication. To integrate speech into LLMs, one promising approach is dense feature prepending (DFP) which prepends the projected speech representations to the textual representations, allowing end-to-end training with the speech encoder. However, DFP typically requires connecting a text decoder to a speech encoder. This raises questions about the importance of having a sophisticated speech encoder for DFP, and how its performance compares with a standard encoder-decoder (i.e. cross-attention) architecture. In order to perform a controlled architectural comparison, we train all models from scratch, rather than using large pretrained models, and use comparable data and parameter settings, testing speech-to-text recognition (ASR) and translation (ST) on MuST-C v1.0 and CoVoST2 datasets. We study the influence of a speech encoder in DFP. More importantly, we compare DFP and cross-attention under a variety of configurations, such as CTC compression, sequence-level knowledge distillation, generation speed and GPU memory footprint on monolingual, bilingual and multilingual models. Despite the prevalence of DFP over cross-attention, our overall results do not indicate a clear advantage of DFP.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
Pitfalls and Outlooks in Using COMET
Sep 02, 2024



Since its introduction, the COMET metric has blazed a trail in the machine translation community, given its strong correlation with human judgements of translation quality. Its success stems from being a modified pre-trained multilingual model finetuned for quality assessment. However, it being a machine learning model also gives rise to a new set of pitfalls that may not be widely known. We investigate these unexpected behaviours from three aspects: 1) technical: obsolete software versions and compute precision; 2) data: empty content, language mismatch, and translationese at test time as well as distribution and domain biases in training; 3) usage and reporting: multi-reference support and model referencing in the literature. All of these problems imply that COMET scores is not comparable between papers or even technical setups and we put forward our perspective on fixing each issue. Furthermore, we release the SacreCOMET package that can generate a signature for the software and model configuration as well as an appropriate citation. The goal of this work is to help the community make more sound use of the COMET metric.
Compact Speech Translation Models via Discrete Speech Units Pretraining
Feb 29, 2024

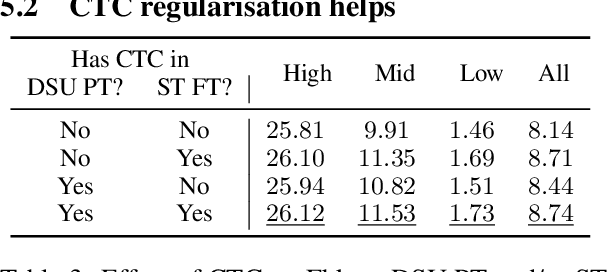

Using Self-Supervised Learning (SSL) as model initialization is now common to obtain strong results in Speech Translation (ST). However, they also impose a large memory footprint, hindering on-device deployment. In this paper, we leverage the SSL models by pretraining smaller models on their Discrete Speech Units (DSU). We pretrain encoder-decoder models on 1) Filterbank-to-DSU and 2) DSU-to-Translation data, and take the encoder from 1) and the decoder from 2) to initialise a new model, finetuning this on limited speech-translation data. The final model becomes compact by using the DSU pretraining to distil the knowledge of the SSL model. Our method has several benefits over using DSU as model inputs, such as shorter inference pipeline and robustness over (DSU) tokenization. In contrast to ASR pretraining, it does not require transcripts, making it applicable to low-resource settings. Evaluation on CoVoST-2 X-En shows that our method is >$0.5$ BLEU better than a ST model that directly finetune the SSL model, given only half the model size, and on a par with ASR pretraining.
Prosody in Cascade and Direct Speech-to-Text Translation: a case study on Korean Wh-Phrases
Feb 01, 2024



Speech-to-Text Translation (S2TT) has typically been addressed with cascade systems, where speech recognition systems generate a transcription that is subsequently passed to a translation model. While there has been a growing interest in developing direct speech translation systems to avoid propagating errors and losing non-verbal content, prior work in direct S2TT has struggled to conclusively establish the advantages of integrating the acoustic signal directly into the translation process. This work proposes using contrastive evaluation to quantitatively measure the ability of direct S2TT systems to disambiguate utterances where prosody plays a crucial role. Specifically, we evaluated Korean-English translation systems on a test set containing wh-phrases, for which prosodic features are necessary to produce translations with the correct intent, whether it's a statement, a yes/no question, a wh-question, and more. Our results clearly demonstrate the value of direct translation systems over cascade translation models, with a notable 12.9% improvement in overall accuracy in ambiguous cases, along with up to a 15.6% increase in F1 scores for one of the major intent categories. To the best of our knowledge, this work stands as the first to provide quantitative evidence that direct S2TT models can effectively leverage prosody. The code for our evaluation is openly accessible and freely available for review and utilisation.
Make More of Your Data: Minimal Effort Data Augmentation for Automatic Speech Recognition and Translation
Oct 27, 2022Data augmentation is a technique to generate new training data based on existing data. We evaluate the simple and cost-effective method of concatenating the original data examples to build new training instances. Continued training with such augmented data is able to improve off-the-shelf Transformer and Conformer models that were optimized on the original data only. We demonstrate considerable improvements on the LibriSpeech-960h test sets (WER 2.83 and 6.87 for test-clean and test-other), which carry over to models combined with shallow fusion (WER 2.55 and 6.27). Our method of continued training also leads to improvements of up to 0.9 WER on the ASR part of CoVoST-2 for four non English languages, and we observe that the gains are highly dependent on the size of the original training data. We compare different concatenation strategies and found that our method does not need speaker information to achieve its improvements. Finally, we demonstrate on two datasets that our methods also works for speech translation tasks.
Analyzing the Use of Influence Functions for Instance-Specific Data Filtering in Neural Machine Translation
Oct 24, 2022Customer feedback can be an important signal for improving commercial machine translation systems. One solution for fixing specific translation errors is to remove the related erroneous training instances followed by re-training of the machine translation system, which we refer to as instance-specific data filtering. Influence functions (IF) have been shown to be effective in finding such relevant training examples for classification tasks such as image classification, toxic speech detection and entailment task. Given a probing instance, IF find influential training examples by measuring the similarity of the probing instance with a set of training examples in gradient space. In this work, we examine the use of influence functions for Neural Machine Translation (NMT). We propose two effective extensions to a state of the art influence function and demonstrate on the sub-problem of copied training examples that IF can be applied more generally than handcrafted regular expressions.
Sample, Translate, Recombine: Leveraging Audio Alignments for Data Augmentation in End-to-end Speech Translation
Mar 16, 2022


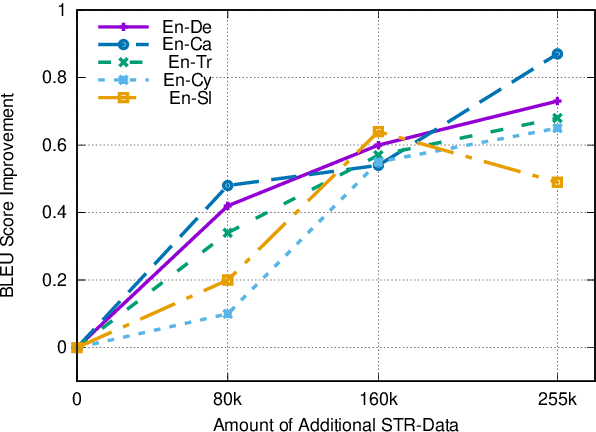
End-to-end speech translation relies on data that pair source-language speech inputs with corresponding translations into a target language. Such data are notoriously scarce, making synthetic data augmentation by back-translation or knowledge distillation a necessary ingredient of end-to-end training. In this paper, we present a novel approach to data augmentation that leverages audio alignments, linguistic properties, and translation. First, we augment a transcription by sampling from a suffix memory that stores text and audio data. Second, we translate the augmented transcript. Finally, we recombine concatenated audio segments and the generated translation. Besides training an MT-system, we only use basic off-the-shelf components without fine-tuning. While having similar resource demands as knowledge distillation, adding our method delivers consistent improvements of up to 0.9 and 1.1 BLEU points on five language pairs on CoVoST 2 and on two language pairs on Europarl-ST, respectively.