 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-the-Fly Aligned Data Augmentation for Sequence-to-Sequence ASR
Paper and Code
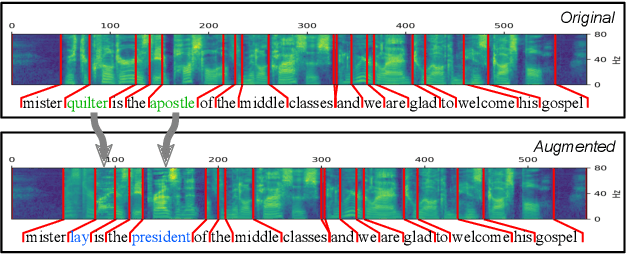
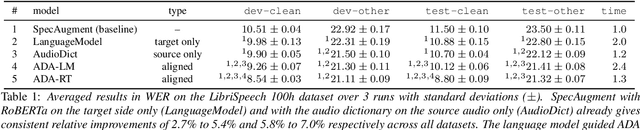
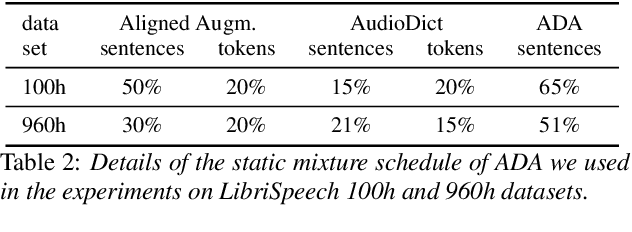

We propose an on-the-fly data augmentation method for automatic speech recognition (ASR) that uses alignment information to generate effective training samples. Our method, called Aligned Data Augmentation (ADA) for ASR, replaces transcribed tokens and the speech representations in an aligned manner to generate previously unseen training pairs. The speech representations are sampled from an audio dictionary that has been extracted from the training corpus and inject speaker variations into the training examples. The transcribed tokens are either predicted by a language model such that the augmented data pairs are semantically close to the original data, or randomly sampled. Both strategies result in training pairs that improve robustness in ASR training. Our experiments on a Seq-to-Seq architecture show that ADA can be applied on top of SpecAugment, and achieves about 9-23% and 4-15% relative improvements in WER over SpecAugment alone on LibriSpeech 100h and LibriSpeech 960h test datasets, respectively.