 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValidity problems in clinical machine learning by indirect data labeling using consensus definitions
Nov 06, 2023
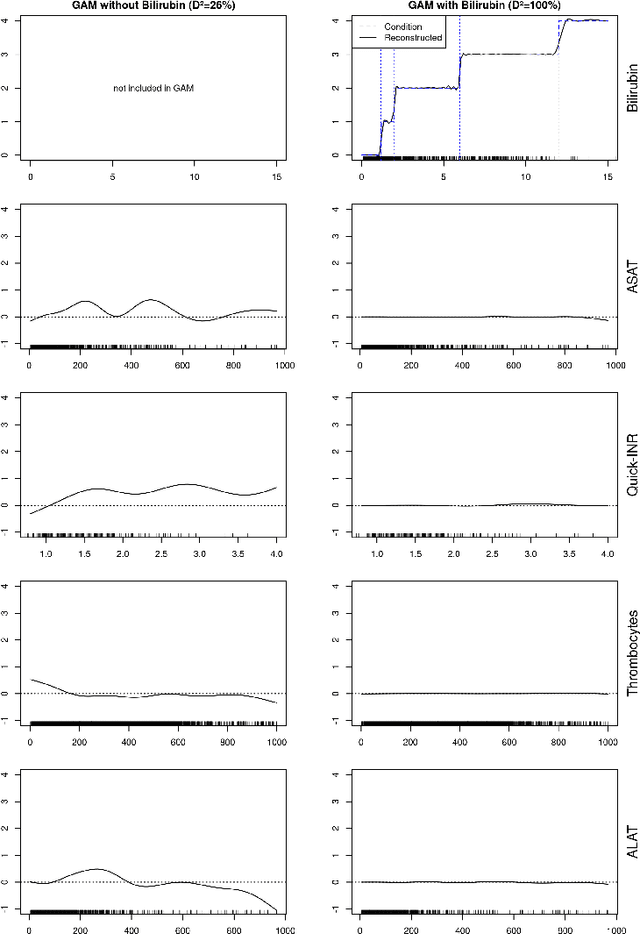

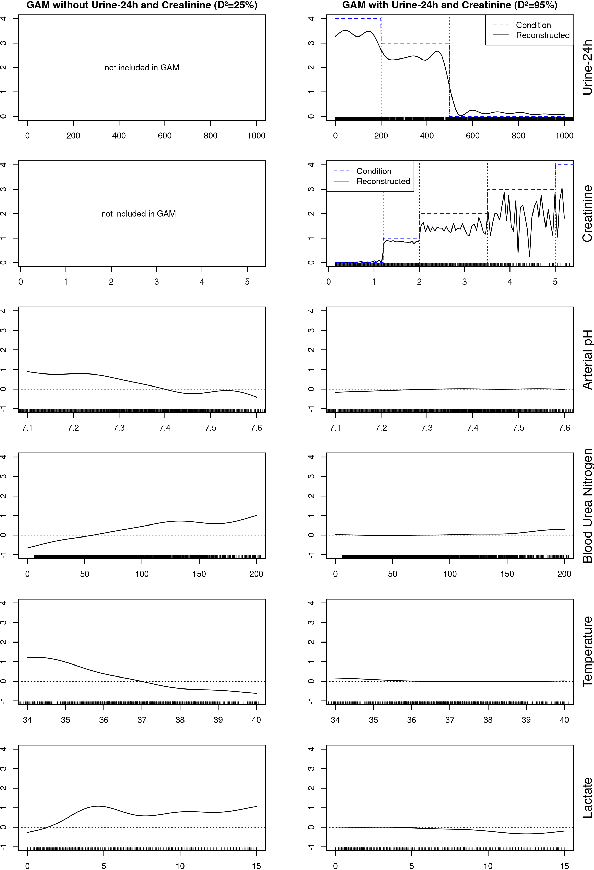
We demonstrate a validity problem of machine learning in the vital application area of disease diagnosis in medicine. It arises when target labels in training data are determined by an indirect measurement, and the fundamental measurements needed to determine this indirect measurement are included in the input data representation. Machine learning models trained on this data will learn nothing else but to exactly reconstruct the known target definition. Such models show perfect performance on similarly constructed test data but will fail catastrophically on real-world examples where the defining fundamental measurements are not or only incompletely available. We present a general procedure allowing identification of problematic datasets and black-box machine learning models trained on them, and exemplify our detection procedure on the task of early prediction of sepsis.
Make More of Your Data: Minimal Effort Data Augmentation for Automatic Speech Recognition and Translation
Oct 27, 2022Data augmentation is a technique to generate new training data based on existing data. We evaluate the simple and cost-effective method of concatenating the original data examples to build new training instances. Continued training with such augmented data is able to improve off-the-shelf Transformer and Conformer models that were optimized on the original data only. We demonstrate considerable improvements on the LibriSpeech-960h test sets (WER 2.83 and 6.87 for test-clean and test-other), which carry over to models combined with shallow fusion (WER 2.55 and 6.27). Our method of continued training also leads to improvements of up to 0.9 WER on the ASR part of CoVoST-2 for four non English languages, and we observe that the gains are highly dependent on the size of the original training data. We compare different concatenation strategies and found that our method does not need speaker information to achieve its improvements. Finally, we demonstrate on two datasets that our methods also works for speech translation tasks.
Sample, Translate, Recombine: Leveraging Audio Alignments for Data Augmentation in End-to-end Speech Translation
Mar 16, 2022


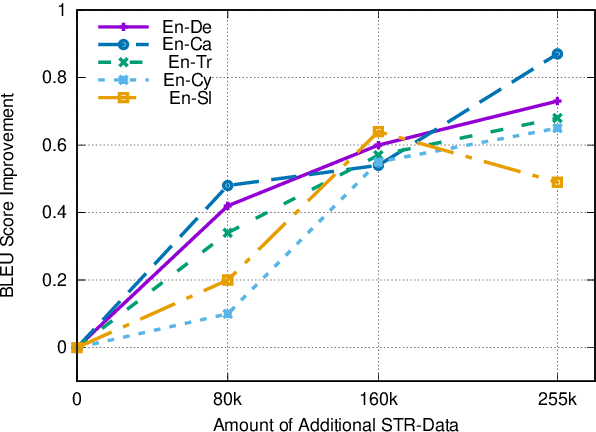
End-to-end speech translation relies on data that pair source-language speech inputs with corresponding translations into a target language. Such data are notoriously scarce, making synthetic data augmentation by back-translation or knowledge distillation a necessary ingredient of end-to-end training. In this paper, we present a novel approach to data augmentation that leverages audio alignments, linguistic properties, and translation. First, we augment a transcription by sampling from a suffix memory that stores text and audio data. Second, we translate the augmented transcript. Finally, we recombine concatenated audio segments and the generated translation. Besides training an MT-system, we only use basic off-the-shelf components without fine-tuning. While having similar resource demands as knowledge distillation, adding our method delivers consistent improvements of up to 0.9 and 1.1 BLEU points on five language pairs on CoVoST 2 and on two language pairs on Europarl-ST, respectively.
On-the-Fly Aligned Data Augmentation for Sequence-to-Sequence ASR
Apr 03, 2021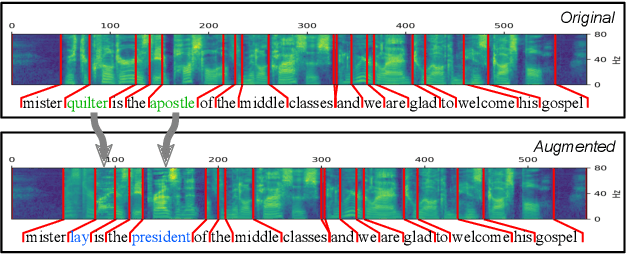
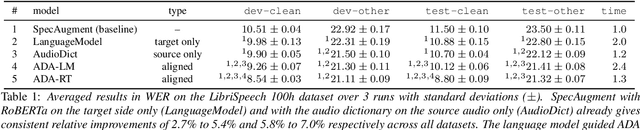
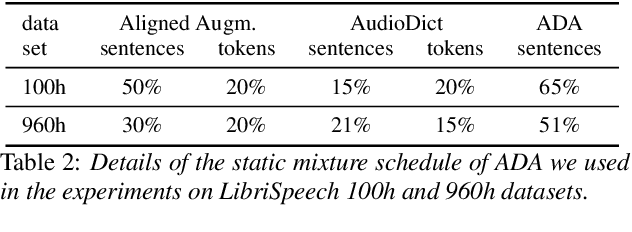

We propose an on-the-fly data augmentation method for automatic speech recognition (ASR) that uses alignment information to generate effective training samples. Our method, called Aligned Data Augmentation (ADA) for ASR, replaces transcribed tokens and the speech representations in an aligned manner to generate previously unseen training pairs. The speech representations are sampled from an audio dictionary that has been extracted from the training corpus and inject speaker variations into the training examples. The transcribed tokens are either predicted by a language model such that the augmented data pairs are semantically close to the original data, or randomly sampled. Both strategies result in training pairs that improve robustness in ASR training. Our experiments on a Seq-to-Seq architecture show that ADA can be applied on top of SpecAugment, and achieves about 9-23% and 4-15% relative improvements in WER over SpecAugment alone on LibriSpeech 100h and LibriSpeech 960h test datasets, respectively.
Cascaded Models With Cyclic Feedback For Direct Speech Translation
Oct 21, 2020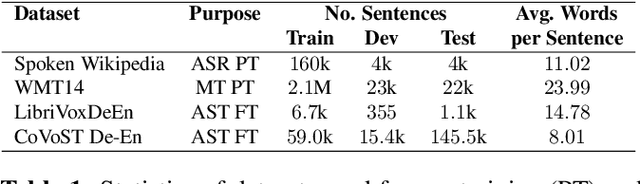



Direct speech translation describes a scenario where only speech inputs and corresponding translations are available. Such data are notoriously limited. We present a technique that allows cascades of automatic speech recognition (ASR) and machine translation (MT) to exploit in-domain direct speech translation data in addition to out-of-domain MT and ASR data. After pre-training MT and ASR, we use a feedback cycle where the downstream performance of the MT system is used as a signal to improve the ASR system by self-training, and the MT component is fine-tuned on multiple ASR outputs, making it more tolerant towards spelling variations. A comparison to end-to-end speech translation using components of identical architecture and the same data shows gains of up to 3.8 BLEU points on LibriVoxDeEn and up to 5.1 BLEU points on CoVoST for German-to-English speech translation.
Leveraging Implicit Expert Knowledge for Non-Circular Machine Learning in Sepsis Prediction
Sep 20, 2019
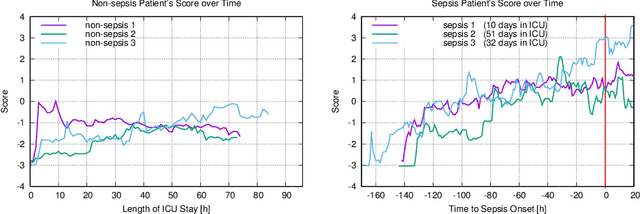


Sepsis is the leading cause of death in non-coronary intensive care units. Moreover, a delay of antibiotic treatment of patients with severe sepsis by only few hours is associated with increased mortality. This insight makes accurate models for early prediction of sepsis a key task in machine learning for healthcare. Previous approaches have achieved high AUROC by learning from electronic health records where sepsis labels were defined automatically following established clinical criteria. We argue that the practice of incorporating the clinical criteria that are used to automatically define ground truth sepsis labels as features of severity scoring models is inherently circular and compromises the validity of the proposed approaches. We propose to create an independent ground truth for sepsis research by exploiting implicit knowledge of clinical practitioners via an electronic questionnaire which records attending physicians' daily judgements of patients' sepsis status. We show that despite its small size, our dataset allows to achieve state-of-the-art AUROC scores. An inspection of learned weights for standardized features of the linear model lets us infer potentially surprising feature contributions and allows to interpret seemingly counterintuitive findings.
Interactive-Predictive Neural Machine Translation through Reinforcement and Imitation
Jul 05, 2019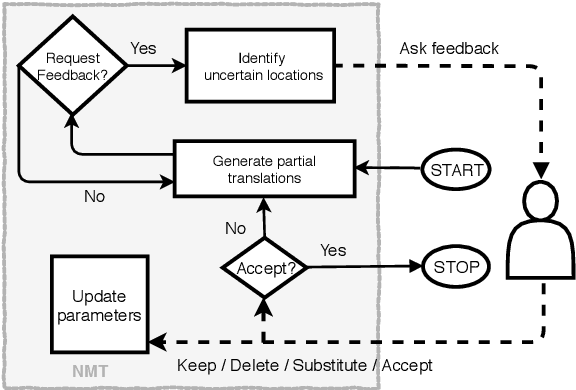

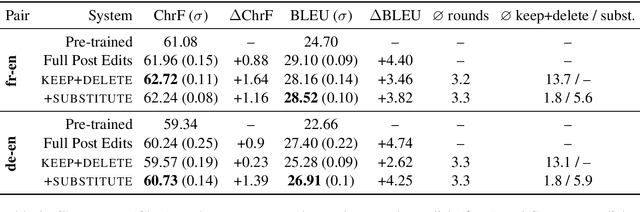
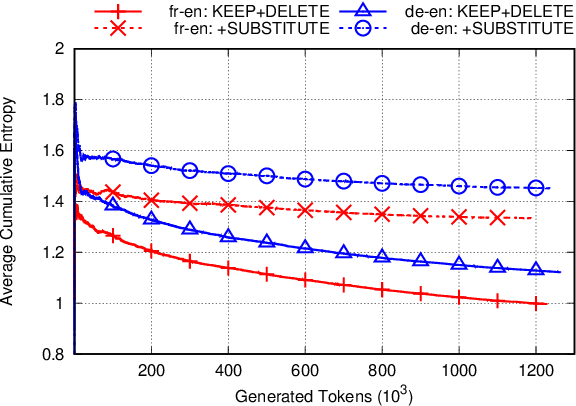
We propose an interactive-predictive neural machine translation framework for easier model personalization using reinforcement and imitation learning. During the interactive translation process, the user is asked for feedback on uncertain locations identified by the system. Responses are weak feedback in the form of "keep" and "delete" edits, and expert demonstrations in the form of "substitute" edits. Conditioning on the collected feedback, the system creates alternative translations via constrained beam search. In simulation experiments on two language pairs our systems get close to the performance of supervised training with much less human effort.
Multimodal Pivots for Image Caption Translation
Jun 13, 2016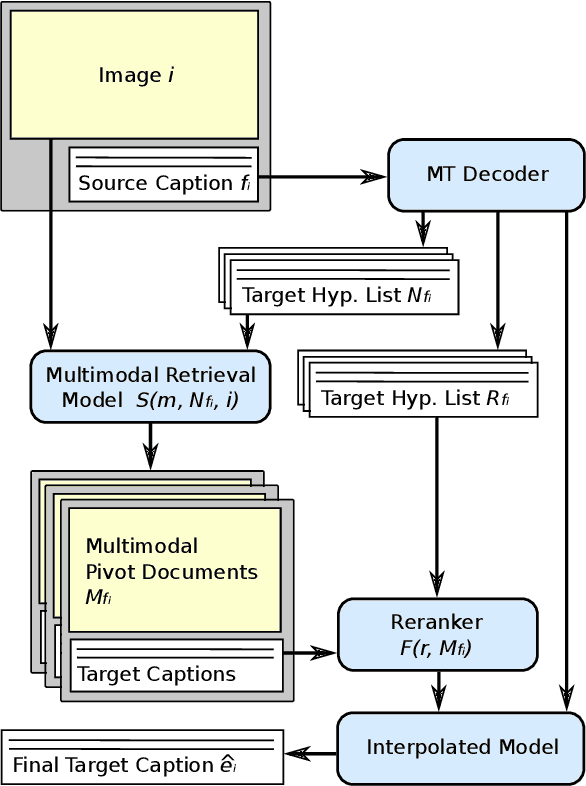
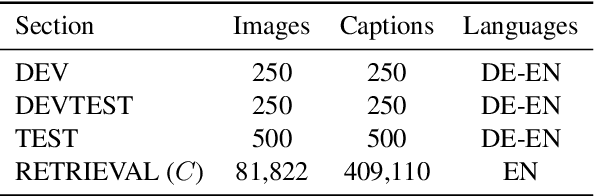
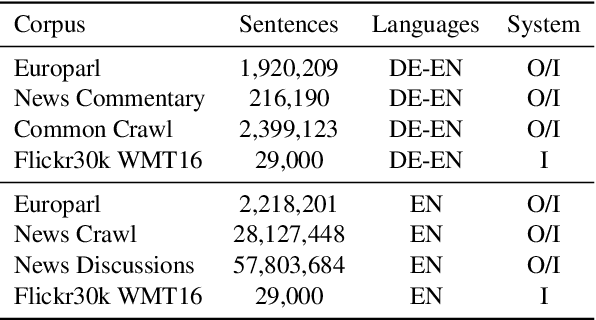
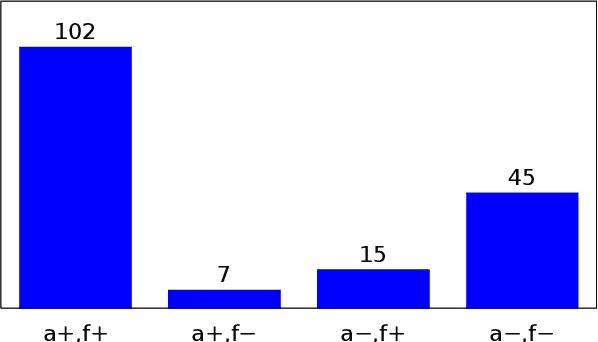
We present an approach to improve statistical machine translation of image descriptions by multimodal pivots defined in visual space. The key idea is to perform image retrieval over a database of images that are captioned in the target language, and use the captions of the most similar images for crosslingual reranking of translation outputs. Our approach does not depend on the availability of large amounts of in-domain parallel data, but only relies on available large datasets of monolingually captioned images, and on state-of-the-art convolutional neural networks to compute image similarities. Our experimental evaluation shows improvements of 1 BLEU point over strong baselines.