 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgedsLassoCov: a federated machine learning approach incorporating covariate control
Dec 11, 2024Machine learning has been widely adopted in biomedical research, fueled by the increasing availability of data. However, integrating datasets across institutions is challenging due to legal restrictions and data governance complexities. Federated learning allows the direct, privacy preserving training of machine learning models using geographically distributed datasets, but faces the challenge of how to appropriately control for covariate effects. The naive implementation of conventional covariate control methods in federated learning scenarios is often impractical due to the substantial communication costs, particularly with high-dimensional data. To address this issue, we introduce dsLassoCov, a machine learning approach designed to control for covariate effects and allow an efficient training in federated learning. In biomedical analysis, this allow the biomarker selection against the confounding effects. Using simulated data, we demonstrate that dsLassoCov can efficiently and effectively manage confounding effects during model training. In our real-world data analysis, we replicated a large-scale Exposome analysis using data from six geographically distinct databases, achieving results consistent with previous studies. By resolving the challenge of covariate control, our proposed approach can accelerate the application of federated learning in large-scale biomedical studies.
MTLComb: multi-task learning combining regression and classification tasks for joint feature selection
May 16, 2024



Multi-task learning (MTL) is a learning paradigm that enables the simultaneous training of multiple communicating algorithms. Although MTL has been successfully applied to ether regression or classification tasks alone, incorporating mixed types of tasks into a unified MTL framework remains challenging, primarily due to variations in the magnitudes of losses associated with different tasks. This challenge, particularly evident in MTL applications with joint feature selection, often results in biased selections. To overcome this obstacle, we propose a provable loss weighting scheme that analytically determines the optimal weights for balancing regression and classification tasks. This scheme significantly mitigates the otherwise biased feature selection. Building upon this scheme, we introduce MTLComb, an MTL algorithm and software package encompassing optimization procedures, training protocols, and hyperparameter estimation procedures. MTLComb is designed for learning shared predictors among tasks of mixed types. To showcase the efficacy of MTLComb, we conduct tests on both simulated data and biomedical studies pertaining to sepsis and schizophrenia.
Leveraging Implicit Expert Knowledge for Non-Circular Machine Learning in Sepsis Prediction
Sep 20, 2019
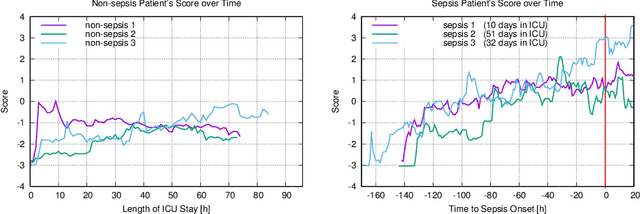


Sepsis is the leading cause of death in non-coronary intensive care units. Moreover, a delay of antibiotic treatment of patients with severe sepsis by only few hours is associated with increased mortality. This insight makes accurate models for early prediction of sepsis a key task in machine learning for healthcare. Previous approaches have achieved high AUROC by learning from electronic health records where sepsis labels were defined automatically following established clinical criteria. We argue that the practice of incorporating the clinical criteria that are used to automatically define ground truth sepsis labels as features of severity scoring models is inherently circular and compromises the validity of the proposed approaches. We propose to create an independent ground truth for sepsis research by exploiting implicit knowledge of clinical practitioners via an electronic questionnaire which records attending physicians' daily judgements of patients' sepsis status. We show that despite its small size, our dataset allows to achieve state-of-the-art AUROC scores. An inspection of learned weights for standardized features of the linear model lets us infer potentially surprising feature contributions and allows to interpret seemingly counterintuitive findings.