 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePropagation Structure-Semantic Transfer Learning for Robust Fake News Detection
Apr 27, 2026Fake news generally refers to false information that is spread deliberately to deceive people, which has detrimental social effects. Existing fake news detection methods primarily learn the semantic features from news content or integrate structural features from propagation. However, in practical scenarios, due to the semantic ambiguity of informal language and unreliable user interactive behaviors on social media, there are inherent semantic and structural noises in news content and propagation. Although some recent works consider the effect of irrelevant user interactions in a hybrid-modeling way, they still suffer from the mutual interference between structural noise and semantic noise, leading to limited performance for robust detection. To alleviate this issue, this paper proposes a novel Propagation Structure-Semantic Transfer Learning framework (PSS-TL) for robust fake news detection under a teacher-student architecture. Specifically, we design dual teacher models to learn semantics knowledge and structure knowledge from noisy news content and propagation structure independently. Besides, we design a Multi-channel Knowledge Distillation (MKD) loss to enable the student model to acquire specialized knowledge from the teacher models, thereby avoiding mutual interference. Extensive experiments on two real-world datasets validate the effectiveness and robustness of our method.
Enhancing Multi-Hop Fact Verification with Structured Knowledge-Augmented Large Language Models
Mar 11, 2025
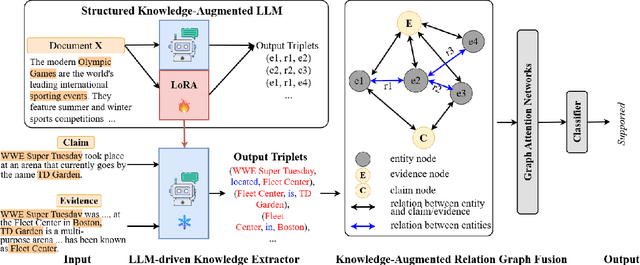
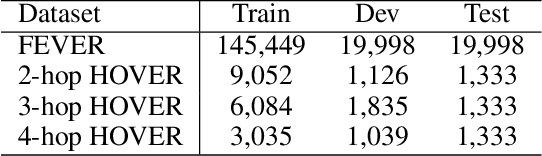
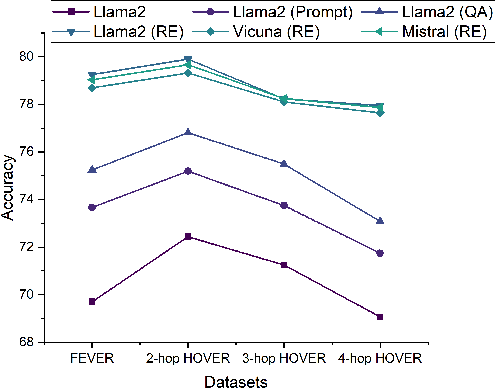
The rapid development of social platforms exacerbates the dissemination of misinformation, which stimulates the research in fact verification. Recent studies tend to leverage semantic features to solve this problem as a single-hop task. However, the process of verifying a claim requires several pieces of evidence with complicated inner logic and relations to verify the given claim in real-world situations. Recent studies attempt to improve both understanding and reasoning abilities to enhance the performance, but they overlook the crucial relations between entities that benefit models to understand better and facilitate the prediction. To emphasize the significance of relations, we resort to Large Language Models (LLMs) considering their excellent understanding ability. Instead of other methods using LLMs as the predictor, we take them as relation extractors, for they do better in understanding rather than reasoning according to the experimental results. Thus, to solve the challenges above, we propose a novel Structured Knowledge-Augmented LLM-based Network (LLM-SKAN) for multi-hop fact verification. Specifically, we utilize an LLM-driven Knowledge Extractor to capture fine-grained information, including entities and their complicated relations. Besides, we leverage a Knowledge-Augmented Relation Graph Fusion module to interact with each node and learn better claim-evidence representations comprehensively. The experimental results on four common-used datasets demonstrate the effectiveness and superiority of our model.
DTSGAN: Learning Dynamic Textures via Spatiotemporal Generative Adversarial Network
Dec 22, 2024



Dynamic texture synthesis aims to generate sequences that are visually similar to a reference video texture and exhibit specific stationary properties in time. In this paper, we introduce a spatiotemporal generative adversarial network (DTSGAN) that can learn from a single dynamic texture by capturing its motion and content distribution. With the pipeline of DTSGAN, a new video sequence is generated from the coarsest scale to the finest one. To avoid mode collapse, we propose a novel strategy for data updates that helps improve the diversity of generated results. Qualitative and quantitative experiments show that our model is able to generate high quality dynamic textures and natural motion.
dsLassoCov: a federated machine learning approach incorporating covariate control
Dec 11, 2024



Machine learning has been widely adopted in biomedical research, fueled by the increasing availability of data. However, integrating datasets across institutions is challenging due to legal restrictions and data governance complexities. Federated learning allows the direct, privacy preserving training of machine learning models using geographically distributed datasets, but faces the challenge of how to appropriately control for covariate effects. The naive implementation of conventional covariate control methods in federated learning scenarios is often impractical due to the substantial communication costs, particularly with high-dimensional data. To address this issue, we introduce dsLassoCov, a machine learning approach designed to control for covariate effects and allow an efficient training in federated learning. In biomedical analysis, this allow the biomarker selection against the confounding effects. Using simulated data, we demonstrate that dsLassoCov can efficiently and effectively manage confounding effects during model training. In our real-world data analysis, we replicated a large-scale Exposome analysis using data from six geographically distinct databases, achieving results consistent with previous studies. By resolving the challenge of covariate control, our proposed approach can accelerate the application of federated learning in large-scale biomedical studies.
Mitigating Knowledge Conflicts in Language Model-Driven Question Answering
Nov 18, 2024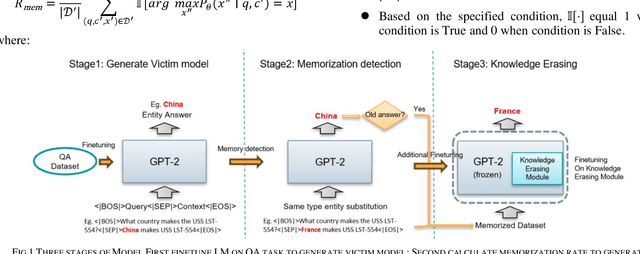


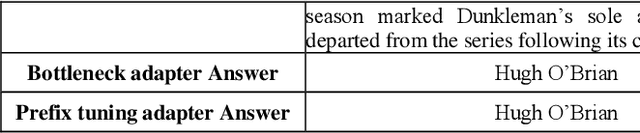
Knowledge-aware sequence to sequence generation tasks such as document question answering and abstract summarization typically requires two types of knowledge: encoded parametric knowledge and retrieved contextual information. Previous work show improper correlation between parametric knowledge and answers in the training set could cause the model ignore input information at test time, resulting in un-desirable model behaviour such as over-stability and hallucination. In this work, we argue that hallucination could be mitigated via explicit correlation between input source and generated content. We focus on a typical example of hallucination, entity-based knowledge conflicts in question answering, where correlation of entities and their description at training time hinders model behaviour during inference.
Artistic Neural Style Transfer Algorithms with Activation Smoothing
Nov 12, 2024



The works of Gatys et al. demonstrated the capability of Convolutional Neural Networks (CNNs) in creating artistic style images. This process of transferring content images in different styles is called Neural Style Transfer (NST). In this paper, we re-implement image-based NST, fast NST, and arbitrary NST. We also explore to utilize ResNet with activation smoothing in NST. Extensive experimental results demonstrate that smoothing transformation can greatly improve the quality of stylization results.
MTLComb: multi-task learning combining regression and classification tasks for joint feature selection
May 16, 2024



Multi-task learning (MTL) is a learning paradigm that enables the simultaneous training of multiple communicating algorithms. Although MTL has been successfully applied to ether regression or classification tasks alone, incorporating mixed types of tasks into a unified MTL framework remains challenging, primarily due to variations in the magnitudes of losses associated with different tasks. This challenge, particularly evident in MTL applications with joint feature selection, often results in biased selections. To overcome this obstacle, we propose a provable loss weighting scheme that analytically determines the optimal weights for balancing regression and classification tasks. This scheme significantly mitigates the otherwise biased feature selection. Building upon this scheme, we introduce MTLComb, an MTL algorithm and software package encompassing optimization procedures, training protocols, and hyperparameter estimation procedures. MTLComb is designed for learning shared predictors among tasks of mixed types. To showcase the efficacy of MTLComb, we conduct tests on both simulated data and biomedical studies pertaining to sepsis and schizophrenia.
Are Large Language Models Good Fact Checkers: A Preliminary Study
Nov 29, 2023



Recently, Large Language Models (LLMs) have drawn significant attention due to their outstanding reasoning capabilities and extensive knowledge repository, positioning them as superior in handling various natural language processing tasks compared to other language models. In this paper, we present a preliminary investigation into the potential of LLMs in fact-checking. This study aims to comprehensively evaluate various LLMs in tackling specific fact-checking subtasks, systematically evaluating their capabilities, and conducting a comparative analysis of their performance against pre-trained and state-of-the-art low-parameter models. Experiments demonstrate that LLMs achieve competitive performance compared to other small models in most scenarios. However, they encounter challenges in effectively handling Chinese fact verification and the entirety of the fact-checking pipeline due to language inconsistencies and hallucinations. These findings underscore the need for further exploration and research to enhance the proficiency of LLMs as reliable fact-checkers, unveiling the potential capability of LLMs and the possible challenges in fact-checking tasks.
Can Large Language Models Understand Content and Propagation for Misinformation Detection: An Empirical Study
Nov 21, 2023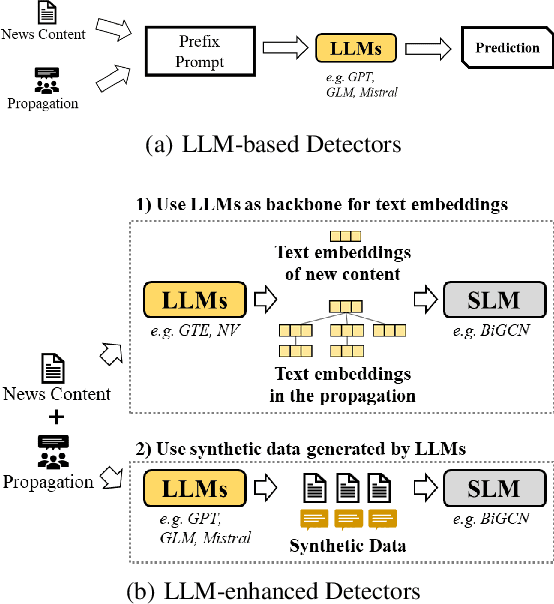
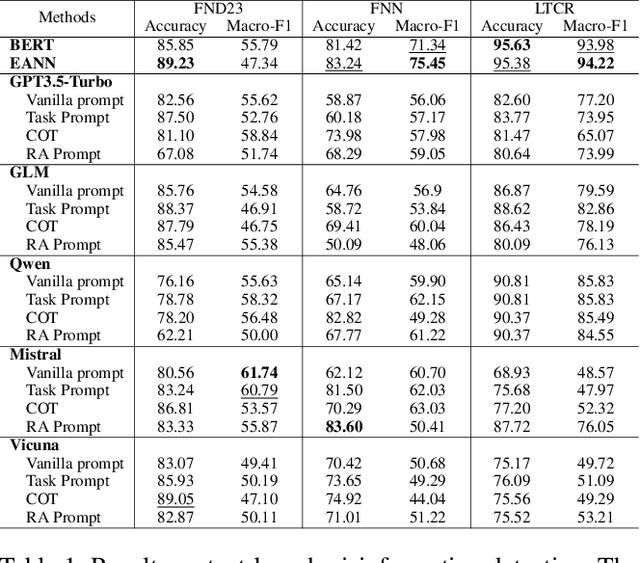
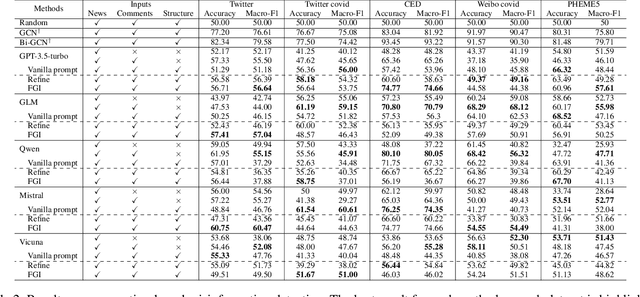
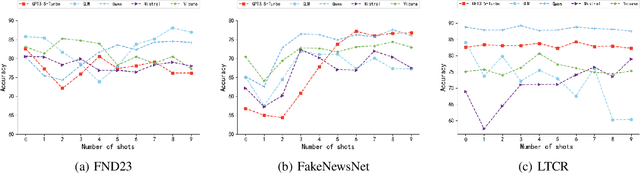
Large Language Models (LLMs) have garnered significant attention for their powerful ability in natural language understanding and reasoning. In this paper, we present a comprehensive empirical study to explore the performance of LLMs on misinformation detection tasks. This study stands as the pioneering investigation into the understanding capabilities of multiple LLMs regarding both content and propagation across social media platforms. Our empirical studies on five misinformation detection datasets show that LLMs with diverse prompts achieve comparable performance in text-based misinformation detection but exhibit notably constrained capabilities in comprehending propagation structure compared to existing models in propagation-based misinformation detection. Besides, we further design four instruction-tuned strategies to enhance LLMs for both content and propagation-based misinformation detection. These strategies boost LLMs to actively learn effective features from multiple instances or hard instances, and eliminate irrelevant propagation structures, thereby achieving better detection performance. Extensive experiments further demonstrate LLMs would play a better capacity in content and propagation structure under these proposed strategies and achieve promising detection performance. These findings highlight the potential ability of LLMs to detect misinformation.
Att-KGCN: Tourist Attractions Recommendation System by using Attention mechanism and Knowledge Graph Convolution Network
Jul 03, 2023The recommendation algorithm based on knowledge graphs is at a relatively mature stage. However, there are still some problems in the recommendation of specific areas. For example, in the tourism field, selecting suitable tourist attraction attributes process is complicated as the recommendation basis for tourist attractions. In this paper, we propose the improved Attention Knowledge Graph Convolution Network model, named ($Att-KGCN$), which automatically discovers the neighboring entities of the target scenic spot semantically. The attention layer aggregates relatively similar locations and represents them with an adjacent vector. Then, according to the tourist's preferred choices, the model predicts the probability of similar spots as a recommendation system. A knowledge graph dataset of tourist attractions used based on tourism data on Socotra Island-Yemen. Through experiments, it is verified that the Attention Knowledge Graph Convolution Network has a good effect on the recommendation of tourist attractions and can make more recommendations for tourists' choices.