 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Benchmark Democratization and Carpentry
Dec 12, 2025Benchmarks are a cornerstone of modern machine learning, enabling reproducibility, comparison, and scientific progress. However, AI benchmarks are increasingly complex, requiring dynamic, AI-focused workflows. Rapid evolution in model architectures, scale, datasets, and deployment contexts makes evaluation a moving target. Large language models often memorize static benchmarks, causing a gap between benchmark results and real-world performance. Beyond traditional static benchmarks, continuous adaptive benchmarking frameworks are needed to align scientific assessment with deployment risks. This calls for skills and education in AI Benchmark Carpentry. From our experience with MLCommons, educational initiatives, and programs like the DOE's Trillion Parameter Consortium, key barriers include high resource demands, limited access to specialized hardware, lack of benchmark design expertise, and uncertainty in relating results to application domains. Current benchmarks often emphasize peak performance on top-tier hardware, offering limited guidance for diverse, real-world scenarios. Benchmarking must become dynamic, incorporating evolving models, updated data, and heterogeneous platforms while maintaining transparency, reproducibility, and interpretability. Democratization requires both technical innovation and systematic education across levels, building sustained expertise in benchmark design and use. Benchmarks should support application-relevant comparisons, enabling informed, context-sensitive decisions. Dynamic, inclusive benchmarking will ensure evaluation keeps pace with AI evolution and supports responsible, reproducible, and accessible AI deployment. Community efforts can provide a foundation for AI Benchmark Carpentry.
An MLCommons Scientific Benchmarks Ontology
Nov 06, 2025



Scientific machine learning research spans diverse domains and data modalities, yet existing benchmark efforts remain siloed and lack standardization. This makes novel and transformative applications of machine learning to critical scientific use-cases more fragmented and less clear in pathways to impact. This paper introduces an ontology for scientific benchmarking developed through a unified, community-driven effort that extends the MLCommons ecosystem to cover physics, chemistry, materials science, biology, climate science, and more. Building on prior initiatives such as XAI-BENCH, FastML Science Benchmarks, PDEBench, and the SciMLBench framework, our effort consolidates a large set of disparate benchmarks and frameworks into a single taxonomy of scientific, application, and system-level benchmarks. New benchmarks can be added through an open submission workflow coordinated by the MLCommons Science Working Group and evaluated against a six-category rating rubric that promotes and identifies high-quality benchmarks, enabling stakeholders to select benchmarks that meet their specific needs. The architecture is extensible, supporting future scientific and AI/ML motifs, and we discuss methods for identifying emerging computing patterns for unique scientific workloads. The MLCommons Science Benchmarks Ontology provides a standardized, scalable foundation for reproducible, cross-domain benchmarking in scientific machine learning. A companion webpage for this work has also been developed as the effort evolves: https://mlcommons-science.github.io/benchmark/
Tesserae: Scalable Placement Policies for Deep Learning Workloads
Aug 07, 2025Training deep learning (DL) models has become a dominant workload in data-centers and improving resource utilization is a key goal of DL cluster schedulers. In order to do this, schedulers typically incorporate placement policies that govern where jobs are placed on the cluster. Existing placement policies are either designed as ad-hoc heuristics or incorporated as constraints within a complex optimization problem and thus either suffer from suboptimal performance or poor scalability. Our key insight is that many placement constraints can be formulated as graph matching problems and based on that we design novel placement policies for minimizing job migration overheads and job packing. We integrate these policies into Tesserae and describe how our design leads to a scalable and effective GPU cluster scheduler. Our experimental results show that Tesserae improves average JCT by up to 1.62x and the Makespan by up to 1.15x compared with the existing schedulers.
PGT-I: Scaling Spatiotemporal GNNs with Memory-Efficient Distributed Training
Jul 15, 2025Spatiotemporal graph neural networks (ST-GNNs) are powerful tools for modeling spatial and temporal data dependencies. However, their applications have been limited primarily to small-scale datasets because of memory constraints. While distributed training offers a solution, current frameworks lack support for spatiotemporal models and overlook the properties of spatiotemporal data. Informed by a scaling study on a large-scale workload, we present PyTorch Geometric Temporal Index (PGT-I), an extension to PyTorch Geometric Temporal that integrates distributed data parallel training and two novel strategies: index-batching and distributed-index-batching. Our index techniques exploit spatiotemporal structure to construct snapshots dynamically at runtime, significantly reducing memory overhead, while distributed-index-batching extends this approach by enabling scalable processing across multiple GPUs. Our techniques enable the first-ever training of an ST-GNN on the entire PeMS dataset without graph partitioning, reducing peak memory usage by up to 89\% and achieving up to a 13.1x speedup over standard DDP with 128 GPUs.
Armada: Memory-Efficient Distributed Training of Large-Scale Graph Neural Networks
Feb 25, 2025We study distributed training of Graph Neural Networks (GNNs) on billion-scale graphs that are partitioned across machines. Efficient training in this setting relies on min-edge-cut partitioning algorithms, which minimize cross-machine communication due to GNN neighborhood sampling. Yet, min-edge-cut partitioning over large graphs remains a challenge: State-of-the-art (SoTA) offline methods (e.g., METIS) are effective, but they require orders of magnitude more memory and runtime than GNN training itself, while computationally efficient algorithms (e.g., streaming greedy approaches) suffer from increased edge cuts. Thus, in this work we introduce Armada, a new end-to-end system for distributed GNN training whose key contribution is GREM, a novel min-edge-cut partitioning algorithm that can efficiently scale to large graphs. GREM builds on streaming greedy approaches with one key addition: prior vertex assignments are continuously refined during streaming, rather than frozen after an initial greedy selection. Our theoretical analysis and experimental results show that this refinement is critical to minimizing edge cuts and enables GREM to reach partition quality comparable to METIS but with 8-65x less memory and 8-46x faster. Given a partitioned graph, Armada leverages a new disaggregated architecture for distributed GNN training to further improve efficiency; we find that on common cloud machines, even with zero communication, GNN neighborhood sampling and feature loading bottleneck training. Disaggregation allows Armada to independently allocate resources for these operations and ensure that expensive GPUs remain saturated with computation. We evaluate Armada against SoTA systems for distributed GNN training and find that the disaggregated architecture leads to runtime improvements up to 4.5x and cost reductions up to 3.1x.
LV-XAttn: Distributed Cross-Attention for Long Visual Inputs in Multimodal Large Language Models
Feb 04, 2025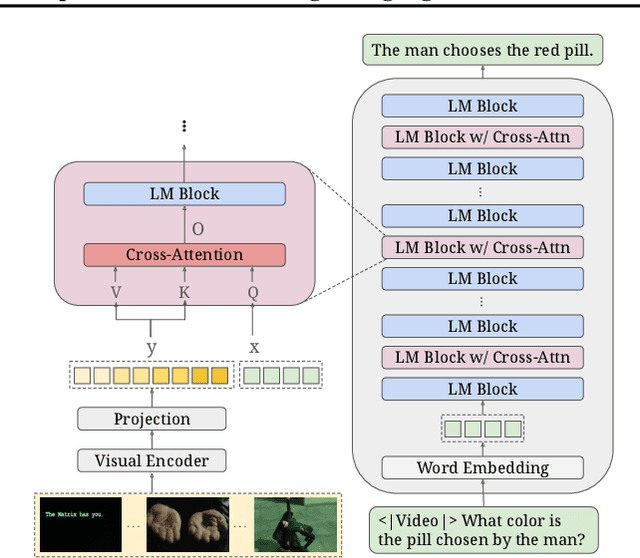


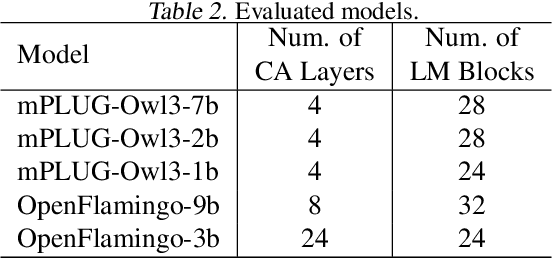
Cross-attention is commonly adopted in multimodal large language models (MLLMs) for integrating visual information into the language backbone. However, in applications with large visual inputs, such as video understanding, processing a large number of visual tokens in cross-attention layers leads to high memory demands and often necessitates distributed computation across multiple GPUs. Existing distributed attention mechanisms face significant communication overheads, making cross-attention layers a critical bottleneck for efficient training and inference of MLLMs. To address this, we propose LV-XAttn, a distributed, exact cross-attention mechanism with minimal communication overhead. We observe that in applications involving large visual inputs the size of the query block is typically much smaller than that of the key-value blocks. Thus, in LV-XAttn we keep the large key-value blocks locally on each GPU and exchange smaller query blocks across GPUs. We also introduce an efficient activation recomputation technique enabling support for longer visual context. We theoretically analyze the communication benefits of LV-XAttn and show that it can achieve speedups for a wide range of models. Our evaluations with mPLUG-Owl3 and OpenFlamingo models find that LV-XAttn achieves up to 5.58$\times$ end-to-end speedup compared to existing approaches.
Scaling Inference-Efficient Language Models
Jan 30, 2025



Scaling laws are powerful tools to predict the performance of large language models. However, current scaling laws fall short of accounting for inference costs. In this work, we first show that model architecture affects inference latency, where models of the same size can have up to 3.5x difference in latency. To tackle this challenge, we modify the Chinchilla scaling laws to co-optimize the model parameter count, the number of training tokens, and the model architecture. Due to the reason that models of similar training loss exhibit gaps in downstream evaluation, we also propose a novel method to train inference-efficient models based on the revised scaling laws. We perform extensive empirical studies to fit and evaluate our inference-aware scaling laws. We vary model parameters from 80M to 1B, training tokens from 1.6B to 30B, and model shapes, training a total of 63 models. Guided by our inference-efficient scaling law and model selection method, we release the Morph-1B model, which improves inference latency by 1.8x while maintaining accuracy on downstream tasks compared to open-source models, pushing the Pareto frontier of accuracy-latency tradeoff.
Incremental IVF Index Maintenance for Streaming Vector Search
Nov 01, 2024


The prevalence of vector similarity search in modern machine learning applications and the continuously changing nature of data processed by these applications necessitate efficient and effective index maintenance techniques for vector search indexes. Designed primarily for static workloads, existing vector search indexes degrade in search quality and performance as the underlying data is updated unless costly index reconstruction is performed. To address this, we introduce Ada-IVF, an incremental indexing methodology for Inverted File (IVF) indexes. Ada-IVF consists of 1) an adaptive maintenance policy that decides which index partitions are problematic for performance and should be repartitioned and 2) a local re-clustering mechanism that determines how to repartition them. Compared with state-of-the-art dynamic IVF index maintenance strategies, Ada-IVF achieves an average of 2x and up to 5x higher update throughput across a range of benchmark workloads.
GraphSnapShot: Graph Machine Learning Acceleration with Fast Storage and Retrieval
Jun 25, 2024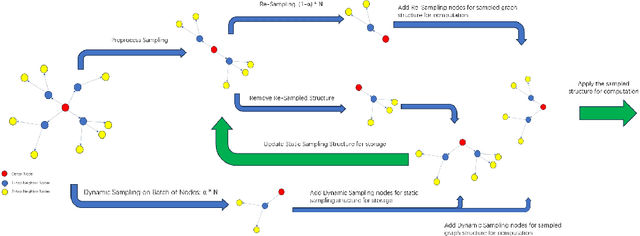
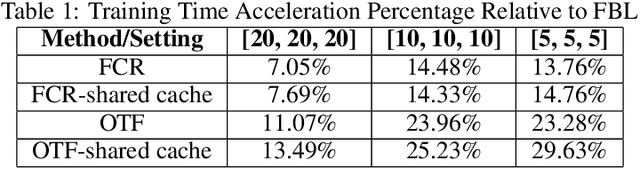
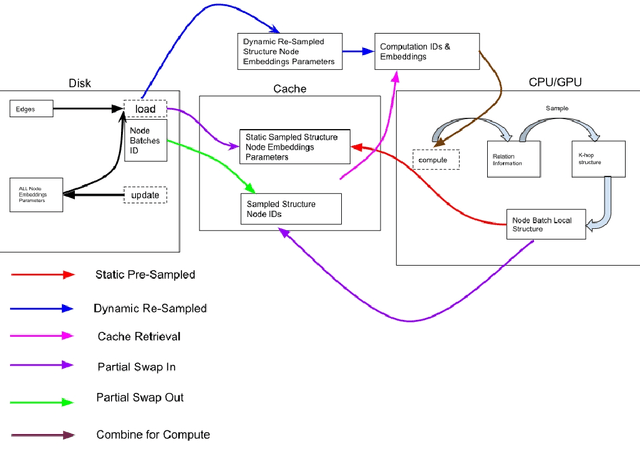

In our recent research, we have developed a framework called GraphSnapShot, which has been proven an useful tool for graph learning acceleration. GraphSnapShot is a framework for fast cache, storage, retrieval and computation for graph learning. It can quickly store and update the local topology of graph structure and allows us to track patterns in the structure of graph networks, just like take snapshots of the graphs. In experiments, GraphSnapShot shows efficiency, it can achieve up to 30% training acceleration and 73% memory reduction for lossless graph ML training compared to current baselines such as dgl.This technique is particular useful for large dynamic graph learning tasks such as social media analysis and recommendation systems to process complex relationships between entities.
CHAI: Clustered Head Attention for Efficient LLM Inference
Mar 12, 2024



Large Language Models (LLMs) with hundreds of billions of parameters have transformed the field of machine learning. However, serving these models at inference time is both compute and memory intensive, where a single request can require multiple GPUs and tens of Gigabytes of memory. Multi-Head Attention is one of the key components of LLMs, which can account for over 50% of LLMs memory and compute requirement. We observe that there is a high amount of redundancy across heads on which tokens they pay attention to. Based on this insight, we propose Clustered Head Attention (CHAI). CHAI combines heads with a high amount of correlation for self-attention at runtime, thus reducing both memory and compute. In our experiments, we show that CHAI is able to reduce the memory requirements for storing K,V cache by up to 21.4% and inference time latency by up to 1.73x without any fine-tuning required. CHAI achieves this with a maximum 3.2% deviation in accuracy across 3 different models (i.e. OPT-66B, LLAMA-7B, LLAMA-33B) and 5 different evaluation datasets.