 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePGT-I: Scaling Spatiotemporal GNNs with Memory-Efficient Distributed Training
Jul 15, 2025Spatiotemporal graph neural networks (ST-GNNs) are powerful tools for modeling spatial and temporal data dependencies. However, their applications have been limited primarily to small-scale datasets because of memory constraints. While distributed training offers a solution, current frameworks lack support for spatiotemporal models and overlook the properties of spatiotemporal data. Informed by a scaling study on a large-scale workload, we present PyTorch Geometric Temporal Index (PGT-I), an extension to PyTorch Geometric Temporal that integrates distributed data parallel training and two novel strategies: index-batching and distributed-index-batching. Our index techniques exploit spatiotemporal structure to construct snapshots dynamically at runtime, significantly reducing memory overhead, while distributed-index-batching extends this approach by enabling scalable processing across multiple GPUs. Our techniques enable the first-ever training of an ST-GNN on the entire PeMS dataset without graph partitioning, reducing peak memory usage by up to 89\% and achieving up to a 13.1x speedup over standard DDP with 128 GPUs.
Dialogue Policies for Confusion Mitigation in Situated HRI
Aug 19, 2022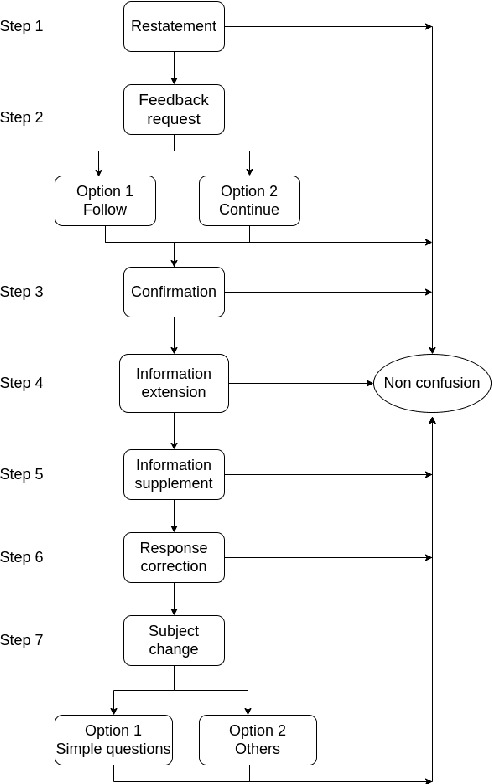
Confusion is a mental state triggered by cognitive disequilibrium that can occur in many types of task-oriented interaction, including Human-Robot Interaction (HRI). People may become confused while interacting with robots due to communicative or even task-centred challenges. To build a smooth and engaging HRI, it is insufficient for an agent to simply detect confusion; instead, the system should aim to mitigate the situation. In light of this, in this paper, we present our approach to a linguistic design of dialogue policies to build a dialogue framework to alleviate interlocutor confusion. We also outline our sketch and discuss challenges with respect to its operationalisation.
Detecting Interlocutor Confusion in Situated Human-Avatar Dialogue: A Pilot Study
Jun 06, 2022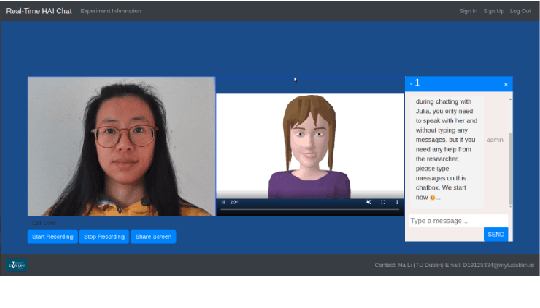
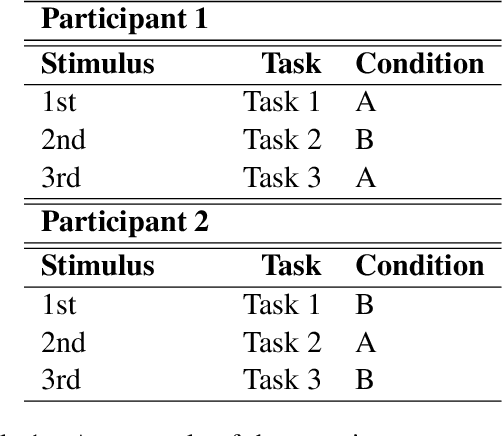
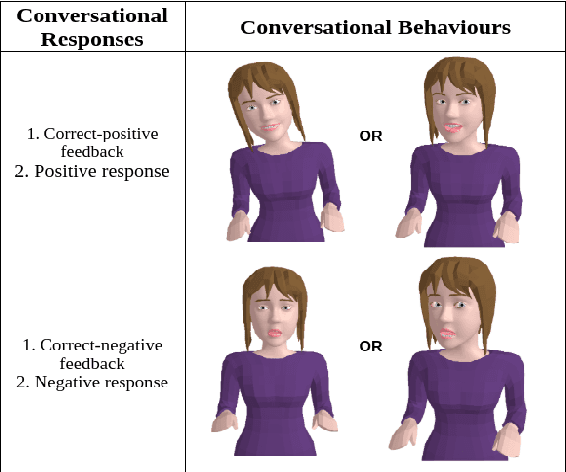

In order to enhance levels of engagement with conversational systems, our long term research goal seeks to monitor the confusion state of a user and adapt dialogue policies in response to such user confusion states. To this end, in this paper, we present our initial research centred on a user-avatar dialogue scenario that we have developed to study the manifestation of confusion and in the long term its mitigation. We present a new definition of confusion that is particularly tailored to the requirements of intelligent conversational system development for task-oriented dialogue. We also present the details of our Wizard-of-Oz based data collection scenario wherein users interacted with a conversational avatar and were presented with stimuli that were in some cases designed to invoke a confused state in the user. Post study analysis of this data is also presented. Here, three pre-trained deep learning models were deployed to estimate base emotion, head pose and eye gaze. Despite a small pilot study group, our analysis demonstrates a significant relationship between these indicators and confusion states. We understand this as a useful step forward in the automated analysis of the pragmatics of dialogue.
Transferring Studies Across Embodiments: A Case Study in Confusion Detection
Jun 03, 2022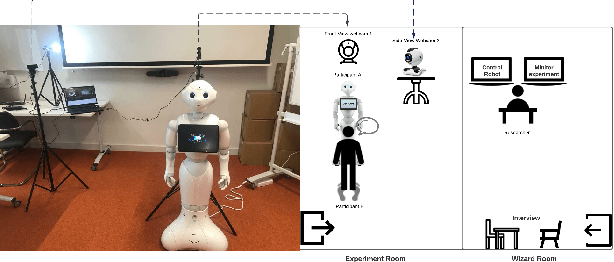

Human-robot studies are expensive to conduct and difficult to control, and as such researchers sometimes turn to human-avatar interaction in the hope of faster and cheaper data collection that can be transferred to the robot domain. In terms of our work, we are particularly interested in the challenge of detecting and modelling user confusion in interaction, and as part of this research programme, we conducted situated dialogue studies to investigate users' reactions in confusing scenarios that we give in both physical and virtual environments. In this paper, we present a combined review of these studies and the results that we observed across these two embodiments. For the physical embodiment, we used a Pepper Robot, while for the virtual modality, we used a 3D avatar. Our study shows that despite attitudinal differences and technical control limitations, there were a number of similarities detected in user behaviour and self-reporting results across embodiment options. This work suggests that, while avatar interaction is no true substitute for robot interaction studies, sufficient care in study design may allow well executed human-avatar studies to supplement more challenging human-robot studies.
Self-Supervised Learning for Invariant Representations from Multi-Spectral and SAR Images
May 04, 2022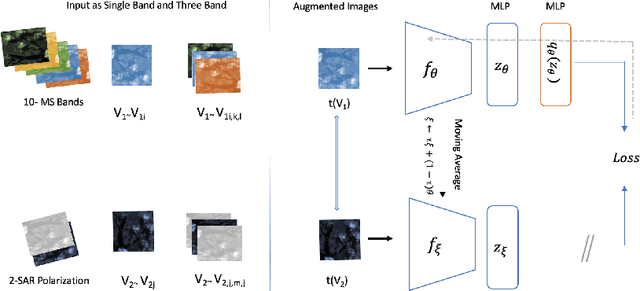
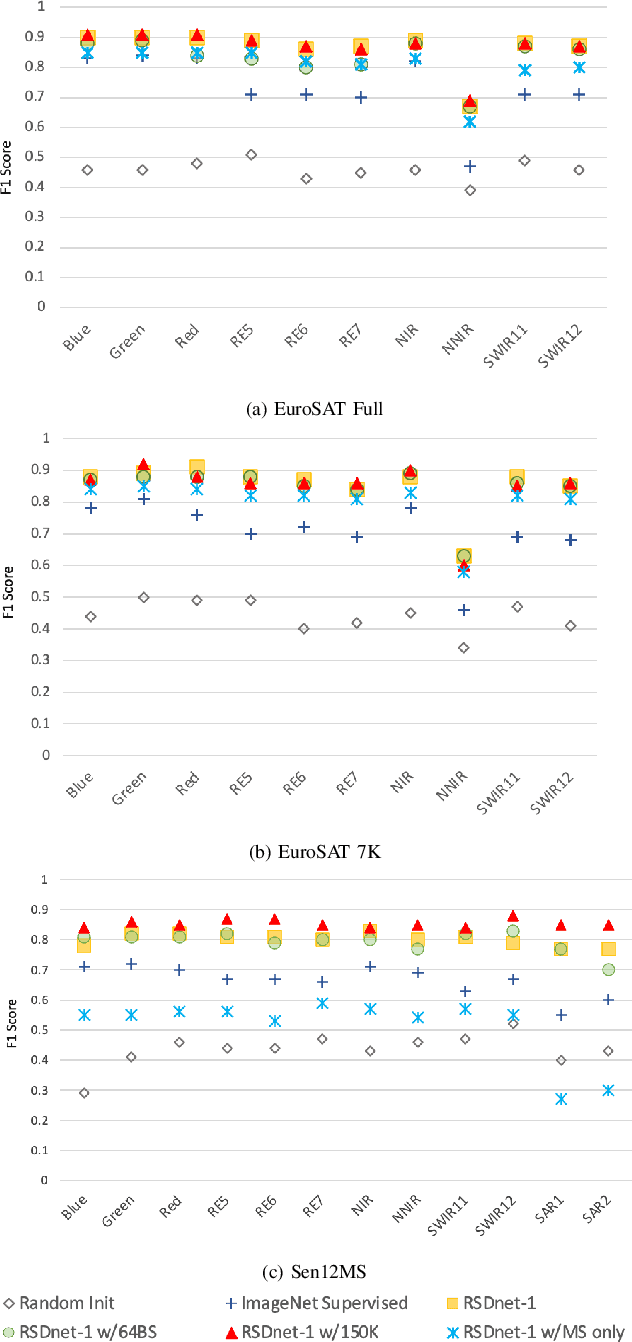
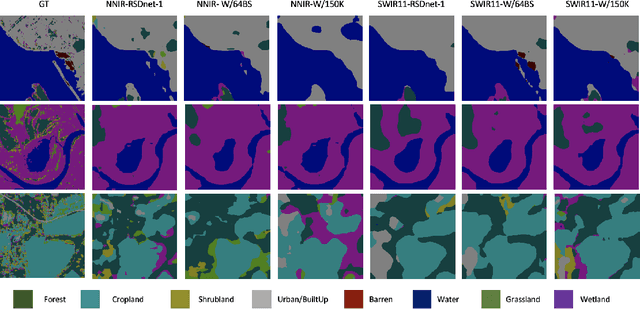
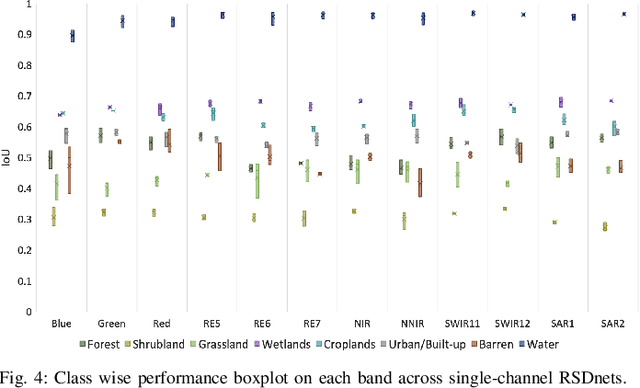
Self-Supervised learning (SSL) has become the new state-of-art in several domain classification and segmentation tasks. Of these, one popular category in SSL is distillation networks such as BYOL. This work proposes RSDnet, which applies the distillation network (BYOL) in the remote sensing (RS) domain where data is non-trivially different from natural RGB images. Since Multi-spectral (MS) and synthetic aperture radar (SAR) sensors provide varied spectral and spatial resolution information, we utilised them as an implicit augmentation to learn invariant feature embeddings. In order to learn RS based invariant features with SSL, we trained RSDnet in two ways, i.e., single channel feature learning and three channel feature learning. This work explores the usefulness of single channel feature learning from random MS and SAR bands compared to the common notion of using three or more bands. In our linear evaluation, these single channel features reached a 0.92 F1 score on the EuroSAT classification task and 59.6 mIoU on the DFC segmentation task for certain single bands. We also compared our results with ImageNet weights and showed that the RS based SSL model outperforms the supervised ImageNet based model. We further explored the usefulness of multi-modal data compared to single modality data, and it is shown that utilising MS and SAR data learn better invariant representations than utilising only MS data.
Data-Driven Reinforcement Learning for Virtual Character Animation Control
Apr 13, 2021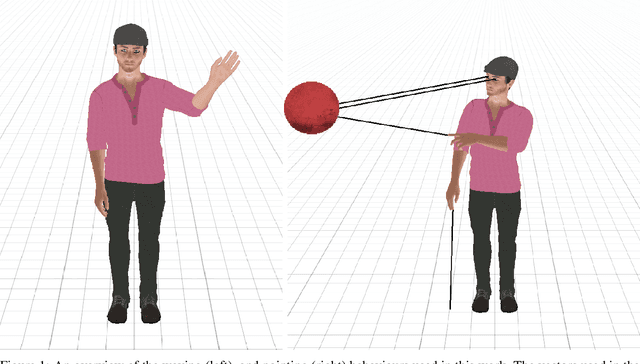
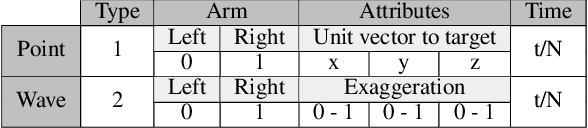
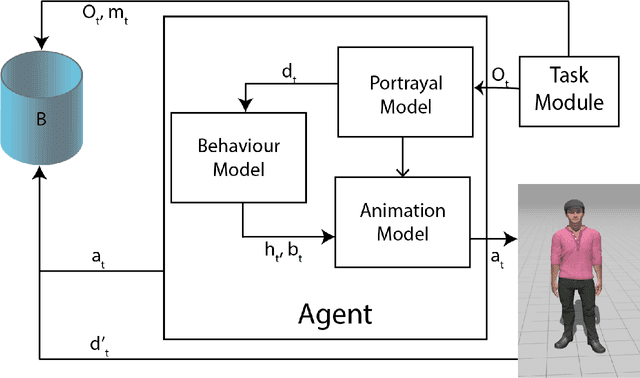
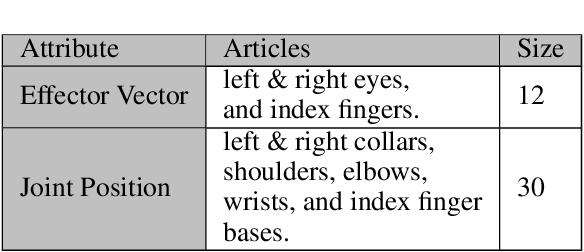
Virtual character animation control is a problem for which Reinforcement Learning (RL) is a viable approach. While current work have applied RL effectively to portray physics-based skills, social behaviours are challenging to design reward functions for, due to their lack of physical interaction with the world. On the other hand, data-driven implementations for these skills have been limited to supervised learning methods which require extensive training data and carry constraints on generalisability. In this paper, we propose RLAnimate, a novel data-driven deep RL approach to address this challenge, where we combine the strengths of RL together with an ability to learn from a motion dataset when creating agents. We formalise a mathematical structure for training agents by refining the conceptual roles of elements such as agents, environments, states and actions, in a way that leverages attributes of the character animation domain and model-based RL. An agent trained using our approach learns versatile animation dynamics to portray multiple behaviours, using an iterative RL training process, which becomes aware of valid behaviours via representations learnt from motion capture clips. We demonstrate, by training agents that portray realistic pointing and waving behaviours, that our approach requires a significantly lower training time, and substantially fewer sample episodes to be generated during training relative to state-of-the-art physics-based RL methods. Also, compared to existing supervised learning-based animation agents, RLAnimate needs a limited dataset of motion clips to generate representations of valid behaviours during training.
Beef Cattle Instance Segmentation Using Fully Convolutional Neural Network
Sep 20, 2018

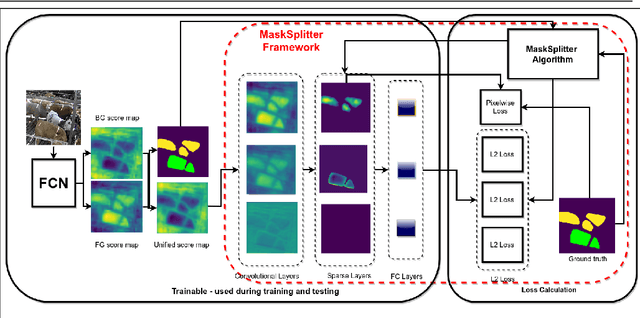

We present an instance segmentation algorithm trained and applied to a CCTV recording of beef cattle during a winter finishing period. A fully convolutional network was transformed into an instance segmentation network that learns to label each instance of an animal separately. We introduce a conceptually simple framework that the network uses to output a single prediction for every animal. These results are a contribution towards behaviour analysis in winter finishing beef cattle for early detection of animal welfare-related problems.
Bootstrapping Labelled Dataset Construction for Cow Tracking and Behavior Analysis
Mar 30, 2017
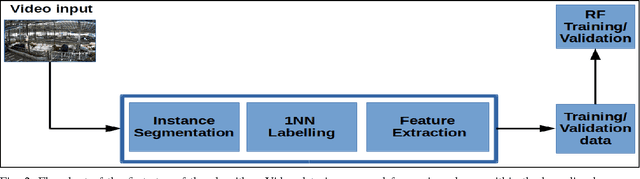


This paper introduces a new approach to the long-term tracking of an object in a challenging environment. The object is a cow and the environment is an enclosure in a cowshed. Some of the key challenges in this domain are a cluttered background, low contrast and high similarity between moving objects which greatly reduces the efficiency of most existing approaches, including those based on background subtraction. Our approach is split into object localization, instance segmentation, learning and tracking stages. Our solution is compared to a range of semi-supervised object tracking algorithms and we show that the performance is strong and well suited to subsequent analysis. We present our solution as a first step towards broader tracking and behavior monitoring for cows in precision agriculture with the ultimate objective of early detection of lameness.