 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransferring Studies Across Embodiments: A Case Study in Confusion Detection
Paper and Code
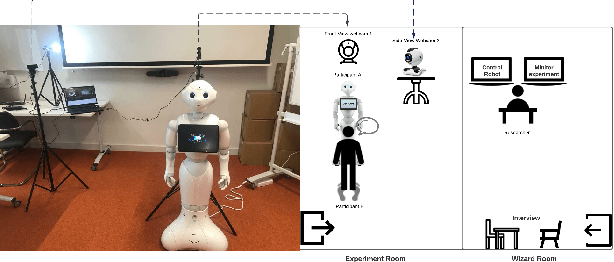

Human-robot studies are expensive to conduct and difficult to control, and as such researchers sometimes turn to human-avatar interaction in the hope of faster and cheaper data collection that can be transferred to the robot domain. In terms of our work, we are particularly interested in the challenge of detecting and modelling user confusion in interaction, and as part of this research programme, we conducted situated dialogue studies to investigate users' reactions in confusing scenarios that we give in both physical and virtual environments. In this paper, we present a combined review of these studies and the results that we observed across these two embodiments. For the physical embodiment, we used a Pepper Robot, while for the virtual modality, we used a 3D avatar. Our study shows that despite attitudinal differences and technical control limitations, there were a number of similarities detected in user behaviour and self-reporting results across embodiment options. This work suggests that, while avatar interaction is no true substitute for robot interaction studies, sufficient care in study design may allow well executed human-avatar studies to supplement more challenging human-robot studies.