 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStep-Tagging: Toward controlling the generation of Language Reasoning Models through step monitoring
Dec 16, 2025The field of Language Reasoning Models (LRMs) has been very active over the past few years with advances in training and inference techniques enabling LRMs to reason longer, and more accurately. However, a growing body of studies show that LRMs are still inefficient, over-generating verification and reflection steps. To address this challenge, we introduce the Step-Tagging framework, a lightweight sentence-classifier enabling real-time annotation of the type of reasoning steps that an LRM is generating. To monitor reasoning behaviors, we introduced ReasonType: a novel taxonomy of reasoning steps. Building on this framework, we demonstrated that online monitoring of the count of specific steps can produce effective interpretable early stopping criteria of LRM inferences. We evaluate the Step-tagging framework on three open-source reasoning models across standard benchmark datasets: MATH500, GSM8K, AIME and non-mathematical tasks (GPQA and MMLU-Pro). We achieve 20 to 50\% token reduction while maintaining comparable accuracy to standard generation, with largest gains observed on more computation-heavy tasks. This work offers a novel way to increase control over the generation of LRMs, and a new tool to study behaviors of LRMs.
Iterative Layer Pruning for Efficient Translation Inference
Oct 26, 2025Large language models (LLMs) have transformed many areas of natural language processing, including machine translation. However, efficient deployment of LLMs remains challenging due to their intensive computational requirements. In this paper, we address this challenge and present our submissions to the Model Compression track at the Conference on Machine Translation (WMT 2025). In our experiments, we investigate iterative layer pruning guided by layer importance analysis. We evaluate this method using the Aya-Expanse-8B model for translation from Czech to German, and from English to Egyptian Arabic. Our approach achieves substantial reductions in model size and inference time, while maintaining the translation quality of the baseline models.
* WMT 2025
Pre-Hoc Predictions in AutoML: Leveraging LLMs to Enhance Model Selection and Benchmarking for Tabular datasets
Oct 02, 2025The field of AutoML has made remarkable progress in post-hoc model selection, with libraries capable of automatically identifying the most performing models for a given dataset. Nevertheless, these methods often rely on exhaustive hyperparameter searches, where methods automatically train and test different types of models on the target dataset. Contrastingly, pre-hoc prediction emerges as a promising alternative, capable of bypassing exhaustive search through intelligent pre-selection of models. Despite its potential, pre-hoc prediction remains under-explored in the literature. This paper explores the intersection of AutoML and pre-hoc model selection by leveraging traditional models and Large Language Model (LLM) agents to reduce the search space of AutoML libraries. By relying on dataset descriptions and statistical information, we reduce the AutoML search space. Our methodology is applied to the AWS AutoGluon portfolio dataset, a state-of-the-art AutoML benchmark containing 175 tabular classification datasets available on OpenML. The proposed approach offers a shift in AutoML workflows, significantly reducing computational overhead, while still selecting the best model for the given dataset.
Active Learning and Transfer Learning for Anomaly Detection in Time-Series Data
Aug 05, 2025



This paper examines the effectiveness of combining active learning and transfer learning for anomaly detection in cross-domain time-series data. Our results indicate that there is an interaction between clustering and active learning and in general the best performance is achieved using a single cluster (in other words when clustering is not applied). Also, we find that adding new samples to the training set using active learning does improve model performance but that in general, the rate of improvement is slower than the results reported in the literature suggest. We attribute this difference to an improved experimental design where distinct data samples are used for the sampling and testing pools. Finally, we assess the ceiling performance of transfer learning in combination with active learning across several datasets and find that performance does initially improve but eventually begins to tail off as more target points are selected for inclusion in training. This tail-off in performance may indicate that the active learning process is doing a good job of sequencing data points for selection, pushing the less useful points towards the end of the selection process and that this tail-off occurs when these less useful points are eventually added. Taken together our results indicate that active learning is effective but that the improvement in model performance follows a linear flat function concerning the number of points selected and labelled.
Extending TWIG: Zero-Shot Predictive Hyperparameter Selection for KGEs based on Graph Structure
Dec 19, 2024Knowledge Graphs (KGs) have seen increasing use across various domains -- from biomedicine and linguistics to general knowledge modelling. In order to facilitate the analysis of knowledge graphs, Knowledge Graph Embeddings (KGEs) have been developed to automatically analyse KGs and predict new facts based on the information in a KG, a task called "link prediction". Many existing studies have documented that the structure of a KG, KGE model components, and KGE hyperparameters can significantly change how well KGEs perform and what relationships they are able to learn. Recently, the Topologically-Weighted Intelligence Generation (TWIG) model has been proposed as a solution to modelling how each of these elements relate. In this work, we extend the previous research on TWIG and evaluate its ability to simulate the output of the KGE model ComplEx in the cross-KG setting. Our results are twofold. First, TWIG is able to summarise KGE performance on a wide range of hyperparameter settings and KGs being learned, suggesting that it represents a general knowledge of how to predict KGE performance from KG structure. Second, we show that TWIG can successfully predict hyperparameter performance on unseen KGs in the zero-shot setting. This second observation leads us to propose that, with additional research, optimal hyperparameter selection for KGE models could be determined in a pre-hoc manner using TWIG-like methods, rather than by using a full hyperparameter search.
A Survey on Knowledge Graph Structure and Knowledge Graph Embeddings
Dec 13, 2024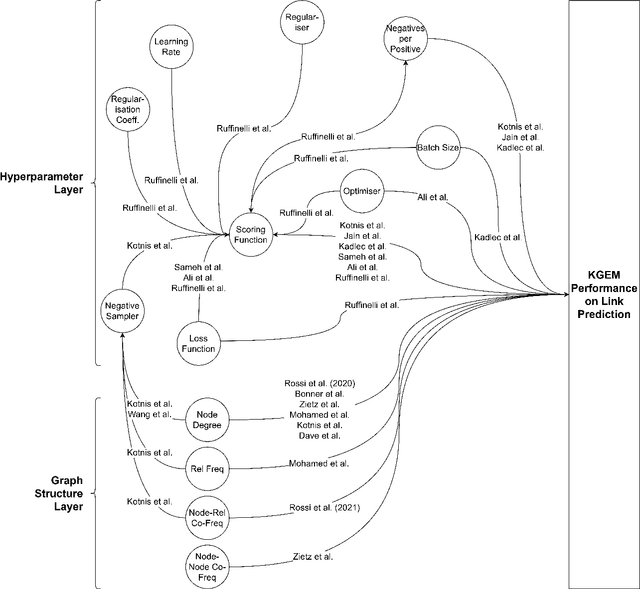
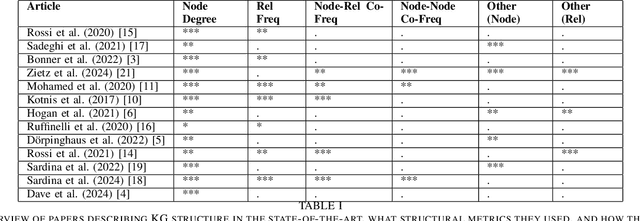

Knowledge Graphs (KGs) and their machine learning counterpart, Knowledge Graph Embedding Models (KGEMs), have seen ever-increasing use in a wide variety of academic and applied settings. In particular, KGEMs are typically applied to KGs to solve the link prediction task; i.e. to predict new facts in the domain of a KG based on existing, observed facts. While this approach has been shown substantial power in many end-use cases, it remains incompletely characterised in terms of how KGEMs react differently to KG structure. This is of particular concern in light of recent studies showing that KG structure can be a significant source of bias as well as partially determinant of overall KGEM performance. This paper seeks to address this gap in the state-of-the-art. This paper provides, to the authors' knowledge, the first comprehensive survey exploring established relationships of Knowledge Graph Embedding Models and Graph structure in the literature. It is the hope of the authors that this work will inspire further studies in this area, and contribute to a more holistic understanding of KGs, KGEMs, and the link prediction task.
BIS: NL2SQL Service Evaluation Benchmark for Business Intelligence Scenarios
Oct 30, 2024



NL2SQL (Natural Language to Structured Query Language) transformation has seen wide adoption in Business Intelligence (BI) applications in recent years. However, existing NL2SQL benchmarks are not suitable for production BI scenarios, as they are not designed for common business intelligence questions. To address this gap, we have developed a new benchmark focused on typical NL questions in industrial BI scenarios. We discuss the challenges of constructing a BI-focused benchmark and the shortcomings of existing benchmarks. Additionally, we introduce question categories in our benchmark that reflect common BI inquiries. Lastly, we propose two novel semantic similarity evaluation metrics for assessing NL2SQL capabilities in BI applications and services.
A framework for measuring the training efficiency of a neural architecture
Sep 12, 2024Measuring Efficiency in neural network system development is an open research problem. This paper presents an experimental framework to measure the training efficiency of a neural architecture. To demonstrate our approach, we analyze the training efficiency of Convolutional Neural Networks and Bayesian equivalents on the MNIST and CIFAR-10 tasks. Our results show that training efficiency decays as training progresses and varies across different stopping criteria for a given neural model and learning task. We also find a non-linear relationship between training stopping criteria, training Efficiency, model size, and training Efficiency. Furthermore, we illustrate the potential confounding effects of overtraining on measuring the training efficiency of a neural architecture. Regarding relative training efficiency across different architectures, our results indicate that CNNs are more efficient than BCNNs on both datasets. More generally, as a learning task becomes more complex, the relative difference in training efficiency between different architectures becomes more pronounced.
Safety-Driven Deep Reinforcement Learning Framework for Cobots: A Sim2Real Approach
Jul 02, 2024



This study presents a novel methodology incorporating safety constraints into a robotic simulation during the training of deep reinforcement learning (DRL). The framework integrates specific parts of the safety requirements, such as velocity constraints, as specified by ISO 10218, directly within the DRL model that becomes a part of the robot's learning algorithm. The study then evaluated the efficiency of these safety constraints by subjecting the DRL model to various scenarios, including grasping tasks with and without obstacle avoidance. The validation process involved comprehensive simulation-based testing of the DRL model's responses to potential hazards and its compliance. Also, the performance of the system is carried out by the functional safety standards IEC 61508 to determine the safety integrity level. The study indicated a significant improvement in the safety performance of the robotic system. The proposed DRL model anticipates and mitigates hazards while maintaining operational efficiency. This study was validated in a testbed with a collaborative robotic arm with safety sensors and assessed with metrics such as the average number of safety violations, obstacle avoidance, and the number of successful grasps. The proposed approach outperforms the conventional method by a 16.5% average success rate on the tested scenarios in the simulations and 2.5% in the testbed without safety violations. The project repository is available at https://github.com/ammar-n-abbas/sim2real-ur-gym-gazebo.
CoBT: Collaborative Programming of Behaviour Trees from One Demonstration for Robot Manipulation
Apr 10, 2024



Mass customization and shorter manufacturing cycles are becoming more important among small and medium-sized companies. However, classical industrial robots struggle to cope with product variation and dynamic environments. In this paper, we present CoBT, a collaborative programming by demonstration framework for generating reactive and modular behavior trees. CoBT relies on a single demonstration and a combination of data-driven machine learning methods with logic-based declarative learning to learn a task, thus eliminating the need for programming expertise or long development times. The proposed framework is experimentally validated on 7 manipulation tasks and we show that CoBT achieves approx. 93% success rate overall with an average of 7.5s programming time. We conduct a pilot study with non-expert users to provide feedback regarding the usability of CoBT.