 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast White-Box Adversarial Streaming Without a Random Oracle
Jun 10, 2024Recently, the question of adversarially robust streaming, where the stream is allowed to depend on the randomness of the streaming algorithm, has gained a lot of attention. In this work, we consider a strong white-box adversarial model (Ajtai et al. PODS 2022), in which the adversary has access to all past random coins and the parameters used by the streaming algorithm. We focus on the sparse recovery problem and extend our result to other tasks such as distinct element estimation and low-rank approximation of matrices and tensors. The main drawback of previous work is that it requires a random oracle, which is especially problematic in the streaming model since the amount of randomness is counted in the space complexity of a streaming algorithm. Also, the previous work suffers from large update time. We construct a near-optimal solution for the sparse recovery problem in white-box adversarial streams, based on the subexponentially secure Learning with Errors assumption. Importantly, our solution does not require a random oracle and has a polylogarithmic per item processing time. We also give results in a related white-box adversarially robust distributed model. Our constructions are based on homomorphic encryption schemes satisfying very mild structural properties that are currently satisfied by most known schemes.
CoBT: Collaborative Programming of Behaviour Trees from One Demonstration for Robot Manipulation
Apr 10, 2024



Mass customization and shorter manufacturing cycles are becoming more important among small and medium-sized companies. However, classical industrial robots struggle to cope with product variation and dynamic environments. In this paper, we present CoBT, a collaborative programming by demonstration framework for generating reactive and modular behavior trees. CoBT relies on a single demonstration and a combination of data-driven machine learning methods with logic-based declarative learning to learn a task, thus eliminating the need for programming expertise or long development times. The proposed framework is experimentally validated on 7 manipulation tasks and we show that CoBT achieves approx. 93% success rate overall with an average of 7.5s programming time. We conduct a pilot study with non-expert users to provide feedback regarding the usability of CoBT.
Barrier Functions Inspired Reward Shaping for Reinforcement Learning
Mar 03, 2024
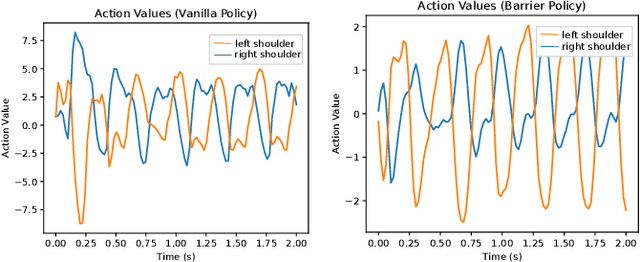


Reinforcement Learning (RL) has progressed from simple control tasks to complex real-world challenges with large state spaces. While RL excels in these tasks, training time remains a limitation. Reward shaping is a popular solution, but existing methods often rely on value functions, which face scalability issues. This paper presents a novel safety-oriented reward-shaping framework inspired by barrier functions, offering simplicity and ease of implementation across various environments and tasks. To evaluate the effectiveness of the proposed reward formulations, we conduct simulation experiments on CartPole, Ant, and Humanoid environments, along with real-world deployment on the Unitree Go1 quadruped robot. Our results demonstrate that our method leads to 1.4-2.8 times faster convergence and as low as 50-60% actuation effort compared to the vanilla reward. In a sim-to-real experiment with the Go1 robot, we demonstrated better control and dynamics of the bot with our reward framework.