 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Control Barrier Functions from Physics Informed Neural Networks
Apr 15, 2025As autonomous systems become increasingly prevalent in daily life, ensuring their safety is paramount. Control Barrier Functions (CBFs) have emerged as an effective tool for guaranteeing safety; however, manually designing them for specific applications remains a significant challenge. With the advent of deep learning techniques, recent research has explored synthesizing CBFs using neural networks-commonly referred to as neural CBFs. This paper introduces a novel class of neural CBFs that leverages a physics-inspired neural network framework by incorporating Zubov's Partial Differential Equation (PDE) within the context of safety. This approach provides a scalable methodology for synthesizing neural CBFs applicable to high-dimensional systems. Furthermore, by utilizing reciprocal CBFs instead of zeroing CBFs, the proposed framework allows for the specification of flexible, user-defined safe regions. To validate the effectiveness of the approach, we present case studies on three different systems: an inverted pendulum, autonomous ground navigation, and aerial navigation in obstacle-laden environments.
Barrier Functions Inspired Reward Shaping for Reinforcement Learning
Mar 03, 2024
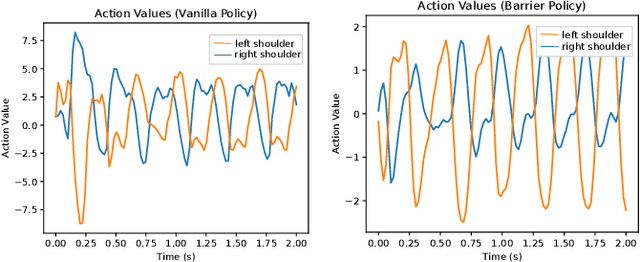


Reinforcement Learning (RL) has progressed from simple control tasks to complex real-world challenges with large state spaces. While RL excels in these tasks, training time remains a limitation. Reward shaping is a popular solution, but existing methods often rely on value functions, which face scalability issues. This paper presents a novel safety-oriented reward-shaping framework inspired by barrier functions, offering simplicity and ease of implementation across various environments and tasks. To evaluate the effectiveness of the proposed reward formulations, we conduct simulation experiments on CartPole, Ant, and Humanoid environments, along with real-world deployment on the Unitree Go1 quadruped robot. Our results demonstrate that our method leads to 1.4-2.8 times faster convergence and as low as 50-60% actuation effort compared to the vanilla reward. In a sim-to-real experiment with the Go1 robot, we demonstrated better control and dynamics of the bot with our reward framework.