 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT2I-BiasBench: A Multi-Metric Framework for Auditing Demographic and Cultural Bias in Text-to-Image Models
Apr 14, 2026Text-to-image (T2I) generative models achieve impressive visual fidelity but inherit and amplify demographic imbalances and cultural biases embedded in training data. We introduce T2I-BiasBench, a unified evaluation framework of thirteen complementary metrics that jointly captures demographic bias, element omission, and cultural collapse in diffusion models - the first framework to address all three dimensions simultaneously. We evaluate three open-source models - Stable Diffusion v1.5, BK-SDM Base, and Koala Lightning - against Gemini 2.5 Flash (RLHF-aligned) as a reference baseline. The benchmark comprises 1,574 generated images across five structured prompt categories. T2I-BiasBench integrates six established metrics with seven additional measures: four newly proposed (Composite Bias Score, Grounded Missing Rate, Implicit Element Missing Rate, Cultural Accuracy Ratio) and three adapted (Hallucination Score, Vendi Score, CLIP Proxy Score). Three key findings emerge: (1) Stable Diffusion v1.5 and BK-SDM exhibit bias amplification (>1.0) in beauty-related prompts; (2) contextual constraints such as surgical PPE substantially attenuate professional-role gender bias (Doctor CBS = 0.06 for SD v1.5); and (3) all models, including RLHF-aligned Gemini, collapse to a narrow set of cultural representations (CAS: 0.54-1.00), confirming that alignment techniques do not resolve cultural coverage gaps. T2I-BiasBench is publicly released to support standardized, fine-grained bias evaluation of generative models. The project page is available at: https://gyanendrachaubey.github.io/T2I-BiasBench/
AdaptNC: Adaptive Nonconformity Scores for Uncertainty-Aware Autonomous Systems in Dynamic Environments
Feb 02, 2026Rigorous uncertainty quantification is essential for the safe deployment of autonomous systems in unconstrained environments. Conformal Prediction (CP) provides a distribution-free framework for this task, yet its standard formulations rely on exchangeability assumptions that are violated by the distribution shifts inherent in real-world robotics. Existing online CP methods maintain target coverage by adaptively scaling the conformal threshold, but typically employ a static nonconformity score function. We show that this fixed geometry leads to highly conservative, volume-inefficient prediction regions when environments undergo structural shifts. To address this, we propose \textbf{AdaptNC}, a framework for the joint online adaptation of both the nonconformity score parameters and the conformal threshold. AdaptNC leverages an adaptive reweighting scheme to optimize score functions, and introduces a replay buffer mechanism to mitigate the coverage instability that occurs during score transitions. We evaluate AdaptNC on diverse robotic benchmarks involving multi-agent policy changes, environmental changes and sensor degradation. Our results demonstrate that AdaptNC significantly reduces prediction region volume compared to state-of-the-art threshold-only baselines while maintaining target coverage levels.
Deep Robust Koopman Learning from Noisy Data
Jan 05, 2026Koopman operator theory has emerged as a leading data-driven approach that relies on a judicious choice of observable functions to realize global linear representations of nonlinear systems in the lifted observable space. However, real-world data is often noisy, making it difficult to obtain an accurate and unbiased approximation of the Koopman operator. The Koopman operator generated from noisy datasets is typically corrupted by noise-induced bias that severely degrades prediction and downstream tracking performance. In order to address this drawback, this paper proposes a novel autoencoder-based neural architecture to jointly learn the appropriate lifting functions and the reduced-bias Koopman operator from noisy data. The architecture initially learns the Koopman basis functions that are consistent for both the forward and backward temporal dynamics of the system. Subsequently, by utilizing the learned forward and backward temporal dynamics, the Koopman operator is synthesized with a reduced bias making the method more robust to noise compared to existing techniques. Theoretical analysis is used to demonstrate significant bias reduction in the presence of training noise. Dynamics prediction and tracking control simulations are conducted for multiple serial manipulator arms, including performance comparisons with leading alternative designs, to demonstrate its robustness under various noise levels. Experimental studies with the Franka FR3 7-DoF manipulator arm are further used to demonstrate the effectiveness of the proposed approach in a practical setting.
V-OCBF: Learning Safety Filters from Offline Data via Value-Guided Offline Control Barrier Functions
Dec 11, 2025Ensuring safety in autonomous systems requires controllers that satisfy hard, state-wise constraints without relying on online interaction. While existing Safe Offline RL methods typically enforce soft expected-cost constraints, they do not guarantee forward invariance. Conversely, Control Barrier Functions (CBFs) provide rigorous safety guarantees but usually depend on expert-designed barrier functions or full knowledge of the system dynamics. We introduce Value-Guided Offline Control Barrier Functions (V-OCBF), a framework that learns a neural CBF entirely from offline demonstrations. Unlike prior approaches, V-OCBF does not assume access to the dynamics model; instead, it derives a recursive finite-difference barrier update, enabling model-free learning of a barrier that propagates safety information over time. Moreover, V-OCBF incorporates an expectile-based objective that avoids querying the barrier on out-of-distribution actions and restricts updates to the dataset-supported action set. The learned barrier is then used with a Quadratic Program (QP) formulation to synthesize real-time safe control. Across multiple case studies, V-OCBF yields substantially fewer safety violations than baseline methods while maintaining strong task performance, highlighting its scalability for offline synthesis of safety-critical controllers without online interaction or hand-engineered barriers.
Concept Incongruence: An Exploration of Time and Death in Role Playing
May 20, 2025Consider this prompt "Draw a unicorn with two horns". Should large language models (LLMs) recognize that a unicorn has only one horn by definition and ask users for clarifications, or proceed to generate something anyway? We introduce concept incongruence to capture such phenomena where concept boundaries clash with each other, either in user prompts or in model representations, often leading to under-specified or mis-specified behaviors. In this work, we take the first step towards defining and analyzing model behavior under concept incongruence. Focusing on temporal boundaries in the Role-Play setting, we propose three behavioral metrics--abstention rate, conditional accuracy, and answer rate--to quantify model behavior under incongruence due to the role's death. We show that models fail to abstain after death and suffer from an accuracy drop compared to the Non-Role-Play setting. Through probing experiments, we identify two main causes: (i) unreliable encoding of the "death" state across different years, leading to unsatisfactory abstention behavior, and (ii) role playing causes shifts in the model's temporal representations, resulting in accuracy drops. We leverage these insights to improve consistency in the model's abstention and answer behaviors. Our findings suggest that concept incongruence leads to unexpected model behaviors and point to future directions on improving model behavior under concept incongruence.
Neural Control Barrier Functions from Physics Informed Neural Networks
Apr 15, 2025
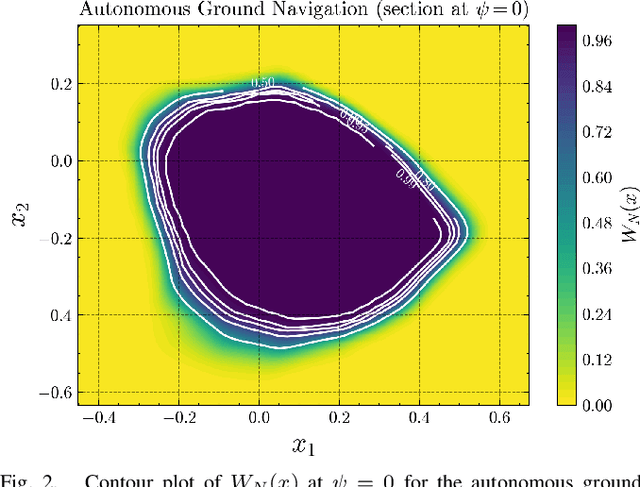

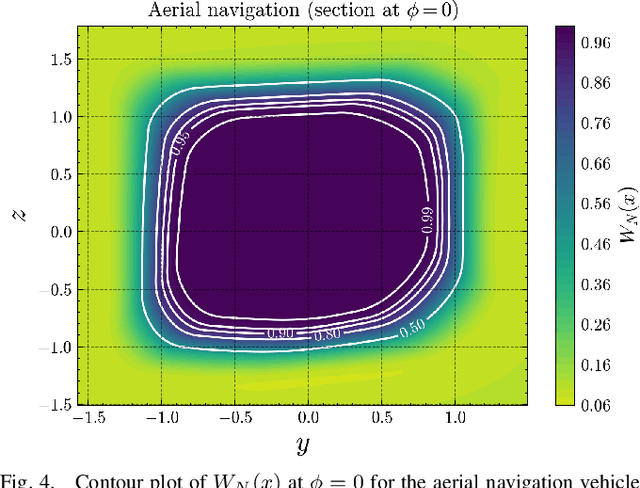
As autonomous systems become increasingly prevalent in daily life, ensuring their safety is paramount. Control Barrier Functions (CBFs) have emerged as an effective tool for guaranteeing safety; however, manually designing them for specific applications remains a significant challenge. With the advent of deep learning techniques, recent research has explored synthesizing CBFs using neural networks-commonly referred to as neural CBFs. This paper introduces a novel class of neural CBFs that leverages a physics-inspired neural network framework by incorporating Zubov's Partial Differential Equation (PDE) within the context of safety. This approach provides a scalable methodology for synthesizing neural CBFs applicable to high-dimensional systems. Furthermore, by utilizing reciprocal CBFs instead of zeroing CBFs, the proposed framework allows for the specification of flexible, user-defined safe regions. To validate the effectiveness of the approach, we present case studies on three different systems: an inverted pendulum, autonomous ground navigation, and aerial navigation in obstacle-laden environments.
Simple Unsupervised Knowledge Distillation With Space Similarity
Sep 20, 2024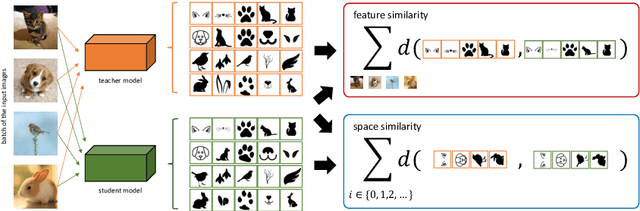
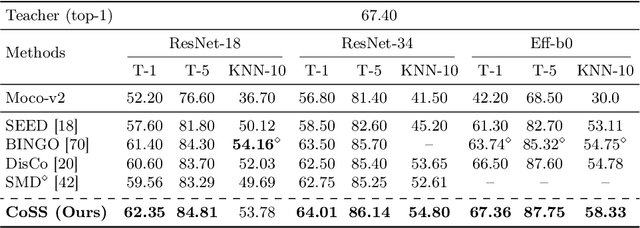

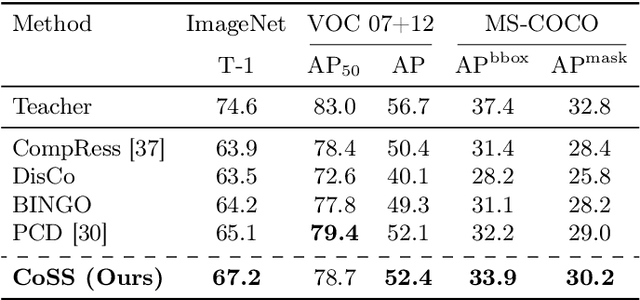
As per recent studies, Self-supervised learning (SSL) does not readily extend to smaller architectures. One direction to mitigate this shortcoming while simultaneously training a smaller network without labels is to adopt unsupervised knowledge distillation (UKD). Existing UKD approaches handcraft preservation worthy inter/intra sample relationships between the teacher and its student. However, this may overlook/ignore other key relationships present in the mapping of a teacher. In this paper, instead of heuristically constructing preservation worthy relationships between samples, we directly motivate the student to model the teacher's embedding manifold. If the mapped manifold is similar, all inter/intra sample relationships are indirectly conserved. We first demonstrate that prior methods cannot preserve teacher's latent manifold due to their sole reliance on $L_2$ normalised embedding features. Subsequently, we propose a simple objective to capture the lost information due to normalisation. Our proposed loss component, termed \textbf{space similarity}, motivates each dimension of a student's feature space to be similar to the corresponding dimension of its teacher. We perform extensive experiments demonstrating strong performance of our proposed approach on various benchmarks.
FolkTalent: Enhancing Classification and Tagging of Indian Folk Paintings
May 14, 2024



Indian folk paintings have a rich mosaic of symbols, colors, textures, and stories making them an invaluable repository of cultural legacy. The paper presents a novel approach to classifying these paintings into distinct art forms and tagging them with their unique salient features. A custom dataset named FolkTalent, comprising 2279 digital images of paintings across 12 different forms, has been prepared using websites that are direct outlets of Indian folk paintings. Tags covering a wide range of attributes like color, theme, artistic style, and patterns are generated using GPT4, and verified by an expert for each painting. Classification is performed employing the RandomForest ensemble technique on fine-tuned Convolutional Neural Network (CNN) models to classify Indian folk paintings, achieving an accuracy of 91.83%. Tagging is accomplished via the prominent fine-tuned CNN-based backbones with a custom classifier attached to its top to perform multi-label image classification. The generated tags offer a deeper insight into the painting, enabling an enhanced search experience based on theme and visual attributes. The proposed hybrid model sets a new benchmark in folk painting classification and tagging, significantly contributing to cataloging India's folk-art heritage.
AnoGAN for Tabular Data: A Novel Approach to Anomaly Detection
May 05, 2024



Anomaly detection, a critical facet in data analysis, involves identifying patterns that deviate from expected behavior. This research addresses the complexities inherent in anomaly detection, exploring challenges and adapting to sophisticated malicious activities. With applications spanning cybersecurity, healthcare, finance, and surveillance, anomalies often signify critical information or potential threats. Inspired by the success of Anomaly Generative Adversarial Network (AnoGAN) in image domains, our research extends its principles to tabular data. Our contributions include adapting AnoGAN's principles to a new domain and promising advancements in detecting previously undetectable anomalies. This paper delves into the multifaceted nature of anomaly detection, considering the dynamic evolution of normal behavior, context-dependent anomaly definitions, and data-related challenges like noise and imbalances.
Imposing Exact Safety Specifications in Neural Reachable Tubes
Mar 31, 2024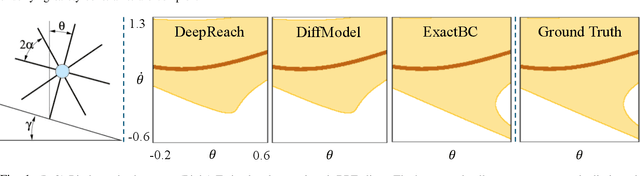
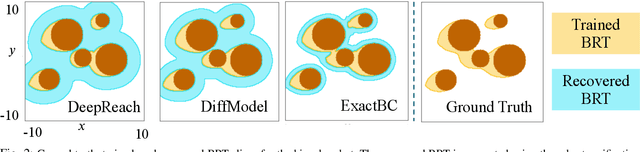
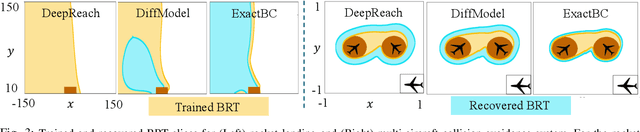

Hamilton-Jacobi (HJ) reachability analysis is a verification tool that provides safety and performance guarantees for autonomous systems. It is widely adopted because of its ability to handle nonlinear dynamical systems with bounded adversarial disturbances and constraints on states and inputs. However, it involves solving a PDE to compute a safety value function, whose computational and memory complexity scales exponentially with the state dimension, making its direct usage in large-scale systems intractable. Recently, a learning-based approach called DeepReach, has been proposed to approximate high-dimensional reachable tubes using neural networks. While DeepReach has been shown to be effective, the accuracy of the learned solution decreases with the increase in system complexity. One of the reasons for this degradation is the inexact imposition of safety constraints during the learning process, which corresponds to the PDE's boundary conditions. Specifically, DeepReach imposes boundary conditions as soft constraints in the loss function, which leaves room for error during the value function learning. Moreover, one needs to carefully adjust the relative contributions from the imposition of boundary conditions and the imposition of the PDE in the loss function. This, in turn, induces errors in the overall learned solution. In this work, we propose a variant of DeepReach that exactly imposes safety constraints during the learning process by restructuring the overall value function as a weighted sum of the boundary condition and neural network output. This eliminates the need for a boundary loss during training, thus bypassing the need for loss adjustment. We demonstrate the efficacy of the proposed approach in significantly improving the accuracy of learned solutions for challenging high-dimensional reachability tasks, such as rocket-landing and multivehicle collision-avoidance problems.