 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOffline Policy Evaluation for Manipulation Policies via Discounted Liveness Formulation
May 12, 2026Policy evaluation is a fundamental component of the development and deployment pipeline for robotic policies. In modern manipulation systems, this problem is particularly challenging: rewards are often sparse, task progression of evaluation rollouts are often non-monotonic as the policies exhibit recovery behaviors, and evaluation rollouts are necessarily of finite length. This finite length introduces truncation bias, breaking the infinite-horizon assumptions underlying standard methods relying on Bellman equations/principle of optimality. In this work, we propose a framework for offline policy evaluation from sparse rewards based on a liveness-based Bellman operator. Our formulation interprets policy evaluation as a task-completion problem and yields a conservative fixed-point value function that is robust to finite-horizon truncation. We analyze the theoretical properties of the proposed operator, including contraction guarantees, and show how it encodes task progression while mitigating truncation bias. We evaluate our method on two simulated manipulation tasks using both a Vision-Language-Action model and a diffusion policy, and a cloth folding task using human demonstrations. Empirical results demonstrate that our approach more accurately reflects task progress and substantially reduces truncation bias, outperforming classical baselines such as TD(0) and Monte Carlo policy evaluation.
Neural Backward Reach-Avoid Tubes with MPC Supervision for High-Dimensional Systems: An Application to Safe Spacecraft Docking
May 03, 2026Autonomous spacecraft docking requires control policies that simultaneously ensure collision avoidance and target reachability under coupled, high-dimensional translational-rotational dynamics. Hamilton-Jacobi (HJ) reachability provides formal reach-avoid guarantees, but classical solvers are limited to low-dimensional systems. Learning-based approaches have begun to scale HJ analysis, yet they struggle in reach-avoid settings, especially where goal and failure sets are tightly coupled, as in docking. We propose a learning-based Backward Reach-Avoid Tube (BRAT) framework that addresses this challenge by tightly integrating HJ structure with MPC-based supervision. In the offline phase, we train a neural approximation of the HJ value function using PDE-based losses augmented with curriculum-driven MPC supervision, which provides informative value targets and stabilizes training in regions where purely PDE-based methods fail. In the online phase, the learned value function is deployed through two real-time controllers: (i) a value gradient-driven controller, and (ii) a value-function-augmented terminal MPC that explicitly enforces reachability at the horizon. We evaluate the proposed method on a 6D planar docking problem against grid-based ground truth and then scale to the full 13D system. Across both settings, our approach outperforms existing methods in success rate and computational efficiency.
Cooptimizing Safety and Performance Using Safety Value-Constrained Model Predictive Control
Apr 26, 2026Autonomous systems are increasingly deployed in real-world environments, where they must achieve high performance while maintaining safety under state and input constraints. Although Model Predictive Control (MPC) provides a principled framework for constrained optimal control, guaranteeing safety beyond its finite planning horizon remains a fundamental challenge. In this work, we augment MPC with a safety value function-based terminal constraint that enforces membership in a control-invariant safe set at the end of each planning horizon. This formulation enables real-time synthesis of trajectories that are both high-performing and provably safe. We show that, under an exact safety value function and a feasible initialization, the proposed MPC scheme is recursively feasible, thereby ensuring persistent safety. In contrast to traditional terminal set constructions that rely on local linearizations or conservative approximations, our approach incorporates a reachability-based safety value function for terminal constraints, yielding less conservative and more expressive safety guarantees. We validate the proposed framework through simulation and hardware experiments on a Flexiv Rizon 10s manipulator. Results demonstrate improved constraint satisfaction and robustness compared to standard state-constrained MPC and reactive safety filtering, while maintaining competitive task performance. The full implementation and experiments are available on the project website.
Boundary Sampling to Learn Predictive Safety Filters via Pontryagin's Maximum Principle
Apr 14, 2026Safety filters provide a practical approach for enforcing safety constraints in autonomous systems. While learning-based tools scale to high-dimensional systems, their performance depends on informative data that includes states likely to lead to constraint violation, which can be difficult to efficiently sample in complex, high-dimensional systems. In this work, we characterize trajectories that barely avoid safety violations using the Pontryagin Maximum Principle. These boundary trajectories are used to guide data collection for learned Hamilton-Jacobi Reachability, concentrating learning efforts near safety-critical states to improve efficiency. The learned Control Barrier Value Function is then used directly for safety filtering. Simulations and experimental validation on a shared-control automotive racing application demonstrate PMP sampling improves learning efficiency, yielding faster convergence, reduced failure rates, and improved safe set reconstruction, with wall times around 3ms.
Robust Verification of Controllers under State Uncertainty via Hamilton-Jacobi Reachability Analysis
Nov 18, 2025As perception-based controllers for autonomous systems become increasingly popular in the real world, it is important that we can formally verify their safety and performance despite perceptual uncertainty. Unfortunately, the verification of such systems remains challenging, largely due to the complexity of the controllers, which are often nonlinear, nonconvex, learning-based, and/or black-box. Prior works propose verification algorithms that are based on approximate reachability methods, but they often restrict the class of controllers and systems that can be handled or result in overly conservative analyses. Hamilton-Jacobi (HJ) reachability analysis is a popular formal verification tool for general nonlinear systems that can compute optimal reachable sets under worst-case system uncertainties; however, its application to perception-based systems is currently underexplored. In this work, we propose RoVer-CoRe, a framework for the Robust Verification of Controllers via HJ Reachability. To the best of our knowledge, RoVer-CoRe is the first HJ reachability-based framework for the verification of perception-based systems under perceptual uncertainty. Our key insight is to concatenate the system controller, observation function, and the state estimation modules to obtain an equivalent closed-loop system that is readily compatible with existing reachability frameworks. Within RoVer-CoRe, we propose novel methods for formal safety verification and robust controller design. We demonstrate the efficacy of the framework in case studies involving aircraft taxiing and NN-based rover navigation. Code is available at the link in the footnote.
Using Vision Language Models as Closed-Loop Symbolic Planners for Robotic Applications: A Control-Theoretic Perspective
Nov 10, 2025Large Language Models (LLMs) and Vision Language Models (VLMs) have been widely used for embodied symbolic planning. Yet, how to effectively use these models for closed-loop symbolic planning remains largely unexplored. Because they operate as black boxes, LLMs and VLMs can produce unpredictable or costly errors, making their use in high-level robotic planning especially challenging. In this work, we investigate how to use VLMs as closed-loop symbolic planners for robotic applications from a control-theoretic perspective. Concretely, we study how the control horizon and warm-starting impact the performance of VLM symbolic planners. We design and conduct controlled experiments to gain insights that are broadly applicable to utilizing VLMs as closed-loop symbolic planners, and we discuss recommendations that can help improve the performance of VLM symbolic planners.
From Words to Safety: Language-Conditioned Safety Filtering for Robot Navigation
Nov 08, 2025As robots become increasingly integrated into open-world, human-centered environments, their ability to interpret natural language instructions and adhere to safety constraints is critical for effective and trustworthy interaction. Existing approaches often focus on mapping language to reward functions instead of safety specifications or address only narrow constraint classes (e.g., obstacle avoidance), limiting their robustness and applicability. We propose a modular framework for language-conditioned safety in robot navigation. Our framework is composed of three core components: (1) a large language model (LLM)-based module that translates free-form instructions into structured safety specifications, (2) a perception module that grounds these specifications by maintaining object-level 3D representations of the environment, and (3) a model predictive control (MPC)-based safety filter that enforces both semantic and geometric constraints in real time. We evaluate the effectiveness of the proposed framework through both simulation studies and hardware experiments, demonstrating that it robustly interprets and enforces diverse language-specified constraints across a wide range of environments and scenarios.
MADR: MPC-guided Adversarial DeepReach
Oct 21, 2025Hamilton-Jacobi (HJ) Reachability offers a framework for generating safe value functions and policies in the face of adversarial disturbance, but is limited by the curse of dimensionality. Physics-informed deep learning is able to overcome this infeasibility, but itself suffers from slow and inaccurate convergence, primarily due to weak PDE gradients and the complexity of self-supervised learning. A few works, recently, have demonstrated that enriching the self-supervision process with regular supervision (based on the nature of the optimal control problem), greatly accelerates convergence and solution quality, however, these have been limited to single player problems and simple games. In this work, we introduce MADR: MPC-guided Adversarial DeepReach, a general framework to robustly approximate the two-player, zero-sum differential game value function. In doing so, MADR yields the corresponding optimal strategies for both players in zero-sum games as well as safe policies for worst-case robustness. We test MADR on a multitude of high-dimensional simulated and real robotic agents with varying dynamics and games, finding that our approach significantly out-performs state-of-the-art baselines in simulation and produces impressive results in hardware.
Safety Evaluation of Motion Plans Using Trajectory Predictors as Forward Reachable Set Estimators
Jul 30, 2025

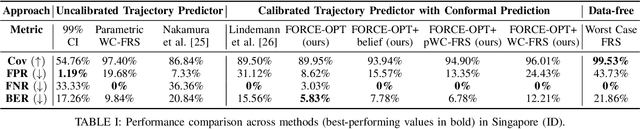

The advent of end-to-end autonomy stacks - often lacking interpretable intermediate modules - has placed an increased burden on ensuring that the final output, i.e., the motion plan, is safe in order to validate the safety of the entire stack. This requires a safety monitor that is both complete (able to detect all unsafe plans) and sound (does not flag safe plans). In this work, we propose a principled safety monitor that leverages modern multi-modal trajectory predictors to approximate forward reachable sets (FRS) of surrounding agents. By formulating a convex program, we efficiently extract these data-driven FRSs directly from the predicted state distributions, conditioned on scene context such as lane topology and agent history. To ensure completeness, we leverage conformal prediction to calibrate the FRS and guarantee coverage of ground-truth trajectories with high probability. To preserve soundness in out-of-distribution (OOD) scenarios or under predictor failure, we introduce a Bayesian filter that dynamically adjusts the FRS conservativeness based on the predictor's observed performance. We then assess the safety of the ego vehicle's motion plan by checking for intersections with these calibrated FRSs, ensuring the plan remains collision-free under plausible future behaviors of others. Extensive experiments on the nuScenes dataset show our approach significantly improves soundness while maintaining completeness, offering a practical and reliable safety monitor for learned autonomy stacks.
Enhancing Robot Safety via MLLM-Based Semantic Interpretation of Failure Data
Jun 06, 2025As robotic systems become increasingly integrated into real-world environments, ranging from autonomous vehicles to household assistants, they inevitably encounter diverse and unstructured scenarios that lead to failures. While such failures pose safety and reliability challenges, they also provide rich perceptual data for improving future performance. However, manually analyzing large-scale failure datasets is impractical. In this work, we present a method for automatically organizing large-scale robotic failure data into semantically meaningful clusters, enabling scalable learning from failure without human supervision. Our approach leverages the reasoning capabilities of Multimodal Large Language Models (MLLMs), trained on internet-scale data, to infer high-level failure causes from raw perceptual trajectories and discover interpretable structure within uncurated failure logs. These semantic clusters reveal latent patterns and hypothesized causes of failure, enabling scalable learning from experience. We demonstrate that the discovered failure modes can guide targeted data collection for policy refinement, accelerating iterative improvement in agent policies and overall safety. Additionally, we show that these semantic clusters can be employed for online failure detection, offering a lightweight yet powerful safeguard for real-time adaptation. We demonstrate that this framework enhances robot learning and robustness by transforming real-world failures into actionable and interpretable signals for adaptation.