 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Reasoning Traces Become Performative: Step-Level Evidence that Chain-of-Thought Is an Imperfect Oversight Channel
May 12, 2026Chain-of-thought (CoT) traces are increasingly used both to improve language model capability and to audit model behavior, implicitly assuming that the visible trace remains synchronized with the computation that determines the answer. We test this assumption with a step-level Detect-Classify-Compare framework built around an answer-commitment proxy that is cross-validated with Patchscopes, tuned-lens probes, and causal direction ablation. Across nine models and seven reasoning benchmarks, latent commitment and explicit answer arrival align on only 61.9% of steps on average. The dominant mismatch pattern is confabulated continuation: 58.0% of detected mismatch events occur after the answer-commitment proxy has already stabilized while the trace continues producing deliberative-looking text, and a vacuousness analysis shows that the committed answer does not change during these steps. In architecture-matched Qwen2.5/DeepSeek-R1-Distill comparisons, the reasoning pipeline changes failure composition more than aggregate alignment, most clearly at 32B where confabulated steps decrease as contradictory states increase. Lower step-level alignment is also associated with larger CoT utility, suggesting that the settings that benefit most from CoT are often the least temporally faithful. Paired truncation and a complementary donor-corruption test further indicate that much post-commitment text is not load-bearing for the final answer. These findings suggest that CoT can remain useful while still being an unreliable report of when the answer was formed.
Persona Non Grata: Single-Method Safety Evaluation Is Incomplete for Persona-Imbued LLMs
Apr 14, 2026Personality imbuing customizes LLM behavior, but safety evaluations almost always study prompt-based personas alone. We show this is incomplete: prompting and activation steering expose *different*, architecture-dependent vulnerability profiles, and testing with only one method can miss a model's dominant failure mode. Across 5,568 judged conditions on four standard models from three architecture families, persona danger rankings under system prompting are preserved across all architectures ($ρ= 0.71$--$0.96$), but activation-steering vulnerability diverges sharply and cannot be predicted from prompt-side rankings: Llama-3.1-8B is substantially more AS-vulnerable, whereas Gemma-3-27B and Qwen3.5 are more vulnerable to prompting. The most striking illustration of this divergence is the *prosocial persona paradox*: on Llama-3.1-8B, P12 (high conscientiousness + high agreeableness) is among the safest personas under prompting yet becomes the highest-ASR activation-steered persona (ASR ~0.818). This is an inversion robust to coefficient ablation and matched-strength calibration, and replicated on DeepSeek-R1-Distill-Qwen-32B. A trait refusal alignment framework, in which conscientiousness is strongly anti-aligned with refusal on Llama-3.1-8B, offers a partial geometric account. Reasoning provides only partial protection: two 32B reasoning models reach 15--18% prompt-side ASR, and activation steering separates them sharply in both baseline susceptibility and persona-specific vulnerability. Heuristic trace diagnostics suggest that the safer model retains stronger policy recall and self-correction behavior, not merely longer reasoning.
IndoorR2X: Indoor Robot-to-Everything Coordination with LLM-Driven Planning
Mar 20, 2026Although robot-to-robot (R2R) communication improves indoor scene understanding beyond what a single robot can achieve, R2R alone cannot overcome partial observability without substantial exploration overhead or scaling team size. In contrast, many indoor environments already include low-cost Internet of Things (IoT) sensors (e.g., cameras) that provide persistent, building-wide context beyond onboard perception. We therefore introduce IndoorR2X, the first benchmark and simulation framework for Large Language Model (LLM)-driven multi-robot task planning with Robot-to-Everything (R2X) perception and communication in indoor environments. IndoorR2X integrates observations from mobile robots and static IoT devices to construct a global semantic state that supports scalable scene understanding, reduces redundant exploration, and enables high-level coordination through LLM-based planning. IndoorR2X provides configurable simulation environments, sensor layouts, robot teams, and task suites to systematically evaluate high-level semantic coordination strategies. Extensive experiments across diverse settings demonstrate that IoT-augmented world modeling improves multi-robot efficiency and reliability, and we highlight key insights and failure modes for advancing LLM-based collaboration between robot teams and indoor IoT sensors.
L2D2: Robot Learning from 2D Drawings
May 17, 2025Robots should learn new tasks from humans. But how do humans convey what they want the robot to do? Existing methods largely rely on humans physically guiding the robot arm throughout their intended task. Unfortunately -- as we scale up the amount of data -- physical guidance becomes prohibitively burdensome. Not only do humans need to operate robot hardware but also modify the environment (e.g., moving and resetting objects) to provide multiple task examples. In this work we propose L2D2, a sketching interface and imitation learning algorithm where humans can provide demonstrations by drawing the task. L2D2 starts with a single image of the robot arm and its workspace. Using a tablet, users draw and label trajectories on this image to illustrate how the robot should act. To collect new and diverse demonstrations, we no longer need the human to physically reset the workspace; instead, L2D2 leverages vision-language segmentation to autonomously vary object locations and generate synthetic images for the human to draw upon. We recognize that drawing trajectories is not as information-rich as physically demonstrating the task. Drawings are 2-dimensional and do not capture how the robot's actions affect its environment. To address these fundamental challenges the next stage of L2D2 grounds the human's static, 2D drawings in our dynamic, 3D world by leveraging a small set of physical demonstrations. Our experiments and user study suggest that L2D2 enables humans to provide more demonstrations with less time and effort than traditional approaches, and users prefer drawings over physical manipulation. When compared to other drawing-based approaches, we find that L2D2 learns more performant robot policies, requires a smaller dataset, and can generalize to longer-horizon tasks. See our project website: https://collab.me.vt.edu/L2D2/
On the Feasibility of A Mixed-Method Approach for Solving Long Horizon Task-Oriented Dexterous Manipulation
Oct 09, 2024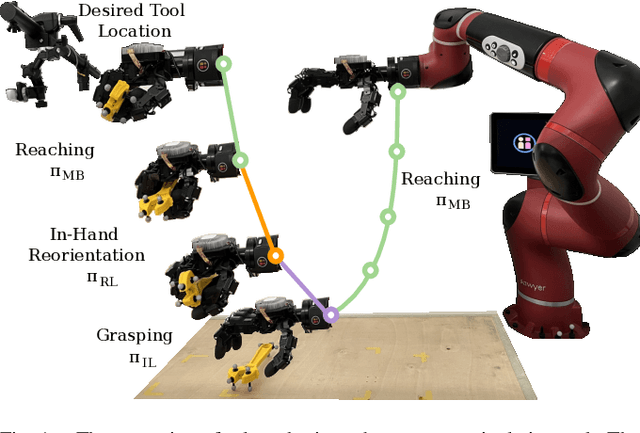
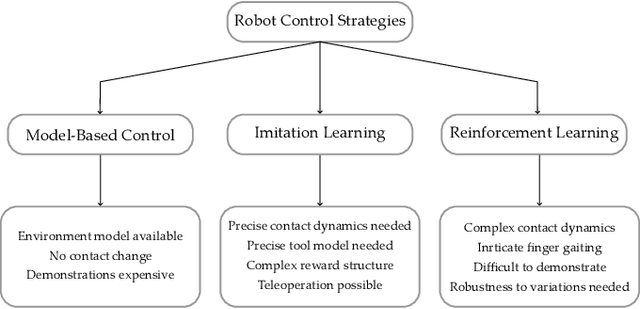
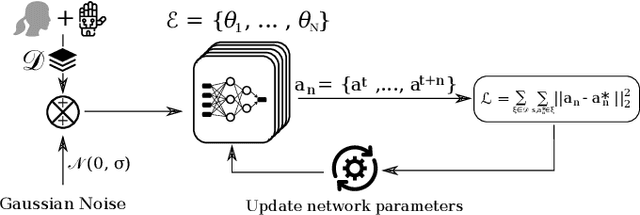
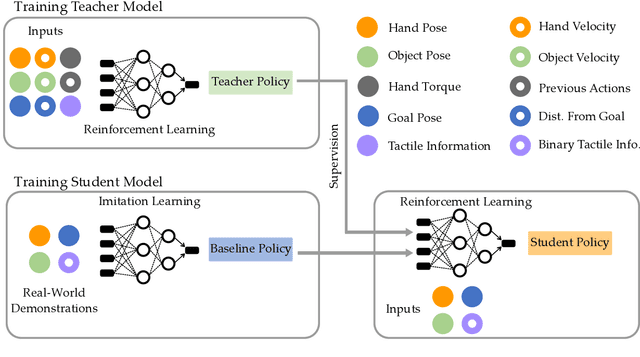
In-hand manipulation of tools using dexterous hands in real-world is an underexplored problem in the literature. In addition to more complex geometry and larger size of the tools compared to more commonly used objects like cubes or cylinders, task oriented in-hand tool manipulation involves many sub-tasks to be performed sequentially. This may involve reaching to the tool, picking it up, reorienting it in hand with or without regrasping to reach to a desired final grasp appropriate for the tool usage, and carrying the tool to the desired pose. Research on long-horizon manipulation using dexterous hands is rather limited and the existing work focus on learning the individual sub-tasks using a method like reinforcement learning (RL) and combine the policies for different subtasks to perform a long horizon task. However, in general a single method may not be the best for all the sub-tasks, and this can be more pronounced when dealing with multi-fingered hands manipulating objects with complex geometry like tools. In this paper, we investigate the use of a mixed-method approach to solve for the long-horizon task of tool usage and we use imitation learning, reinforcement learning and model based control. We also discuss a new RL-based teacher-student framework that combines real world data into offline training. We show that our proposed approach for each subtask outperforms the commonly adopted reinforcement learning approach across different subtasks and in performing the long horizon task in simulation. Finally we show the successful transferability to real world.
Stable-BC: Controlling Covariate Shift with Stable Behavior Cloning
Aug 12, 2024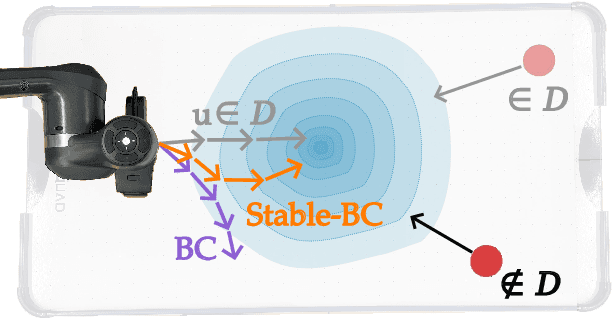
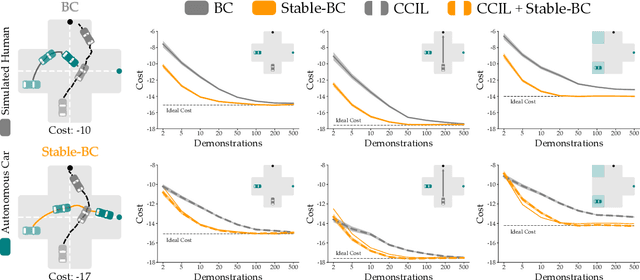
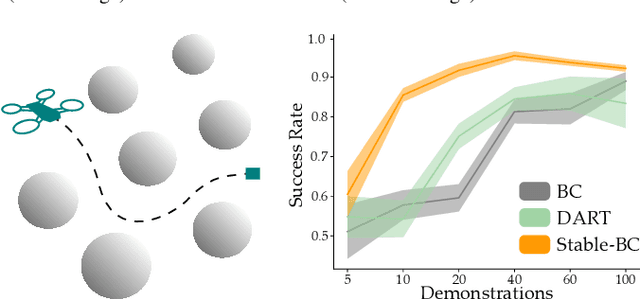
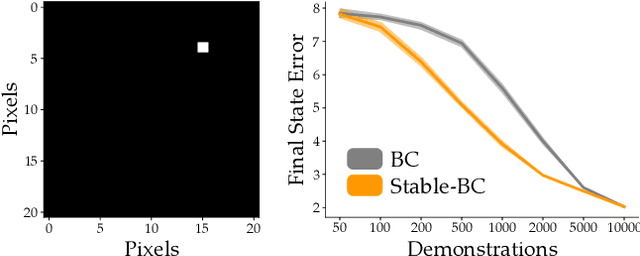
Behavior cloning is a common imitation learning paradigm. Under behavior cloning the robot collects expert demonstrations, and then trains a policy to match the actions taken by the expert. This works well when the robot learner visits states where the expert has already demonstrated the correct action; but inevitably the robot will also encounter new states outside of its training dataset. If the robot learner takes the wrong action at these new states it could move farther from the training data, which in turn leads to increasingly incorrect actions and compounding errors. Existing works try to address this fundamental challenge by augmenting or enhancing the training data. By contrast, in our paper we develop the control theoretic properties of behavior cloned policies. Specifically, we consider the error dynamics between the system's current state and the states in the expert dataset. From the error dynamics we derive model-based and model-free conditions for stability: under these conditions the robot shapes its policy so that its current behavior converges towards example behaviors in the expert dataset. In practice, this results in Stable-BC, an easy to implement extension of standard behavior cloning that is provably robust to covariate shift. We demonstrate the effectiveness of our algorithm in simulations with interactive, nonlinear, and visual environments. We also conduct experiments where a robot arm uses Stable-BC to play air hockey. See our website here: https://collab.me.vt.edu/Stable-BC/
Combining and Decoupling Rigid and Soft Grippers to Enhance Robotic Manipulation
Apr 21, 2024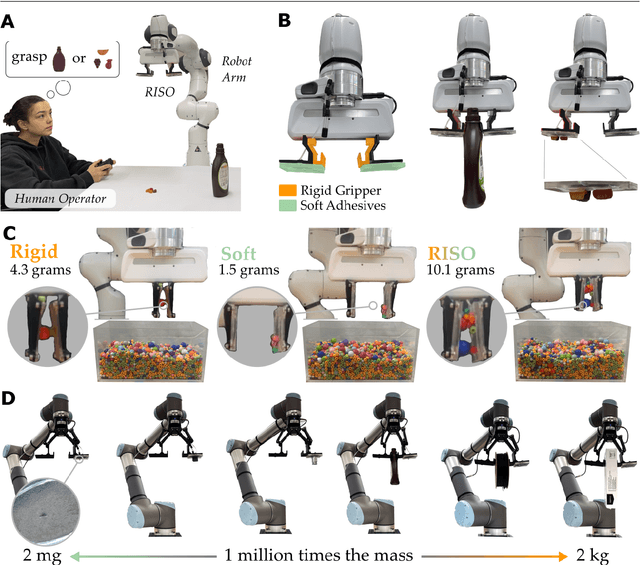
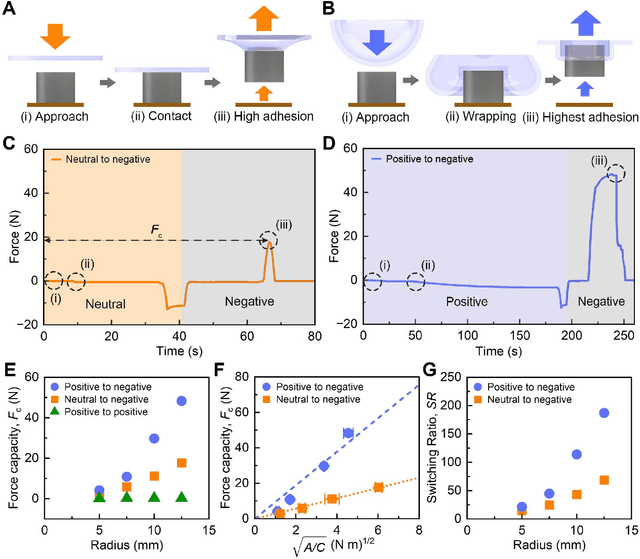
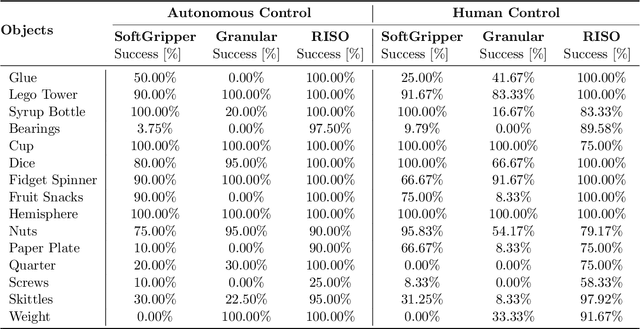
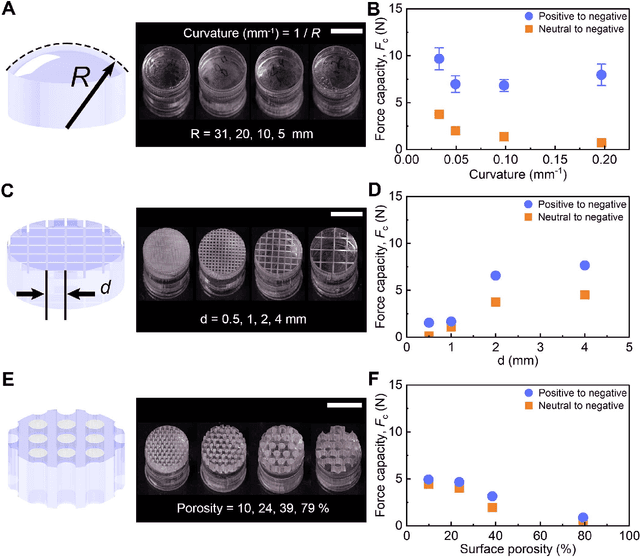
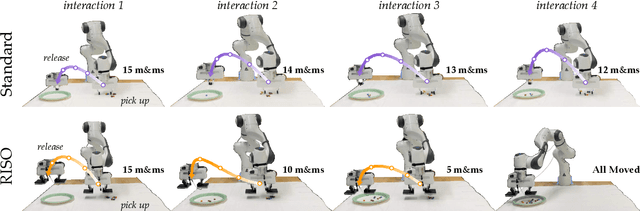
For robot arms to perform everyday tasks in unstructured environments, these robots must be able to manipulate a diverse range of objects. Today's robots often grasp objects with either soft grippers or rigid end-effectors. However, purely rigid or purely soft grippers have fundamental limitations: soft grippers struggle with irregular, heavy objects, while rigid grippers often cannot grasp small, numerous items. In this paper we therefore introduce RISOs, a mechanics and controls approach for unifying traditional RIgid end-effectors with a novel class of SOft adhesives. When grasping an object, RISOs can use either the rigid end-effector (pinching the item between non-deformable fingers) and/or the soft materials (attaching and releasing items with switchable adhesives). This enhances manipulation capabilities by combining and decoupling rigid and soft mechanisms. With RISOs robots can perform grasps along a spectrum from fully rigid, to fully soft, to rigid-soft, enabling real time object manipulation across a 1 million times range in weight (from 2 mg to 2 kg). To develop RISOs we first model and characterize the soft switchable adhesives. We then mount sheets of these soft adhesives on the surfaces of rigid end-effectors, and develop control strategies that make it easier for robot arms and human operators to utilize RISOs. The resulting RISO grippers were able to pick-up, carry, and release a larger set of objects than existing grippers, and participants also preferred using RISO. Overall, our experimental and user study results suggest that RISOs provide an exceptional gripper range in both capacity and object diversity. See videos of our user studies here: https://youtu.be/du085R0gPFI
Waypoint-Based Reinforcement Learning for Robot Manipulation Tasks
Mar 20, 2024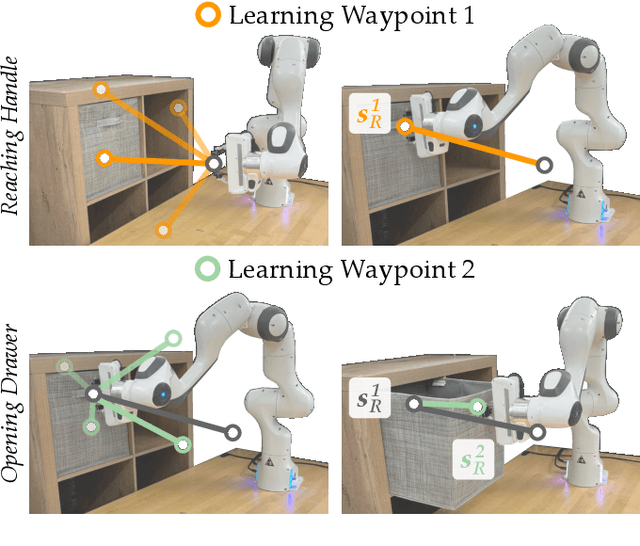
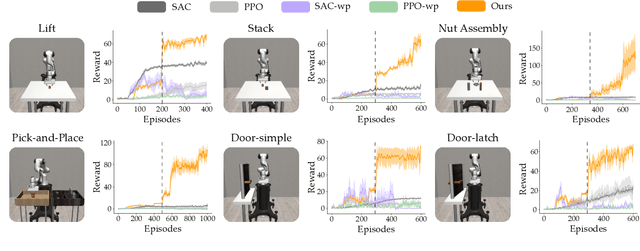
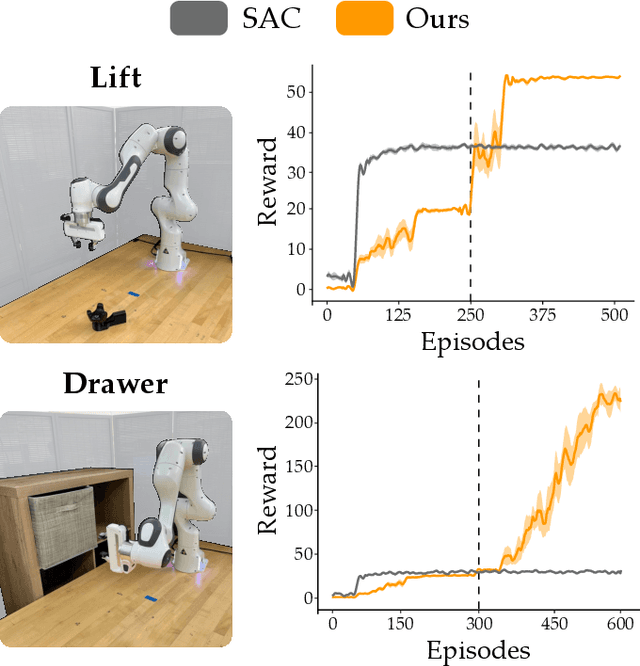
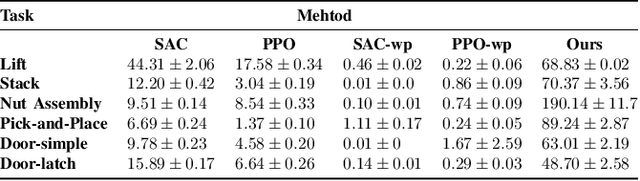
Robot arms should be able to learn new tasks. One framework here is reinforcement learning, where the robot is given a reward function that encodes the task, and the robot autonomously learns actions to maximize its reward. Existing approaches to reinforcement learning often frame this problem as a Markov decision process, and learn a policy (or a hierarchy of policies) to complete the task. These policies reason over hundreds of fine-grained actions that the robot arm needs to take: e.g., moving slightly to the right or rotating the end-effector a few degrees. But the manipulation tasks that we want robots to perform can often be broken down into a small number of high-level motions: e.g., reaching an object or turning a handle. In this paper we therefore propose a waypoint-based approach for model-free reinforcement learning. Instead of learning a low-level policy, the robot now learns a trajectory of waypoints, and then interpolates between those waypoints using existing controllers. Our key novelty is framing this waypoint-based setting as a sequence of multi-armed bandits: each bandit problem corresponds to one waypoint along the robot's motion. We theoretically show that an ideal solution to this reformulation has lower regret bounds than standard frameworks. We also introduce an approximate posterior sampling solution that builds the robot's motion one waypoint at a time. Results across benchmark simulations and two real-world experiments suggest that this proposed approach learns new tasks more quickly than state-of-the-art baselines. See videos here: https://youtu.be/MMEd-lYfq4Y
StROL: Stabilized and Robust Online Learning from Humans
Aug 19, 2023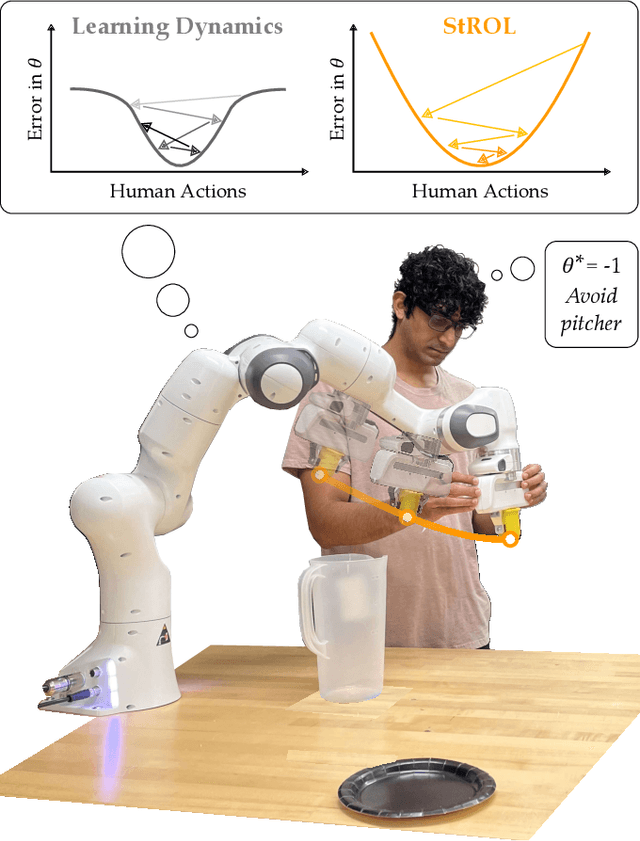
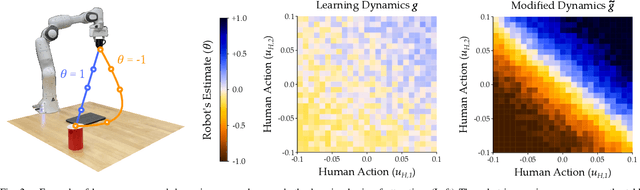
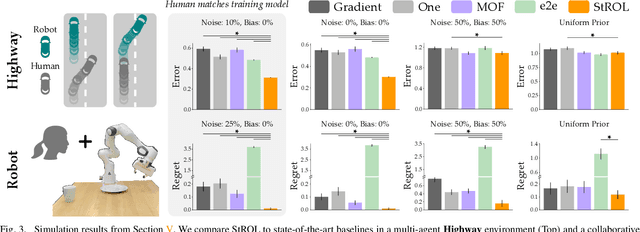
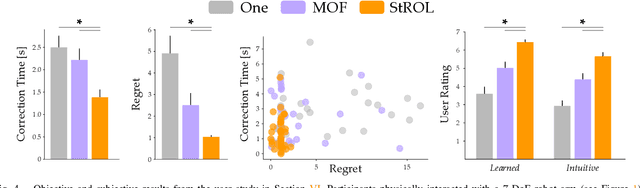
Today's robots can learn the human's reward function online, during the current interaction. This real-time learning requires fast but approximate learning rules; when the human's behavior is noisy or suboptimal, today's approximations can result in unstable robot learning. Accordingly, in this paper we seek to enhance the robustness and convergence properties of gradient descent learning rules when inferring the human's reward parameters. We model the robot's learning algorithm as a dynamical system over the human preference parameters, where the human's true (but unknown) preferences are the equilibrium point. This enables us to perform Lyapunov stability analysis to derive the conditions under which the robot's learning dynamics converge. Our proposed algorithm (StROL) takes advantage of these stability conditions offline to modify the original learning dynamics: we introduce a corrective term that expands the basins of attraction around likely human rewards. In practice, our modified learning rule can correctly infer what the human is trying to convey, even when the human is noisy, biased, and suboptimal. Across simulations and a user study we find that StROL results in a more accurate estimate and less regret than state-of-the-art approaches for online reward learning. See videos here: https://youtu.be/uDGpkvJnY8g
RISO: Combining Rigid Grippers with Soft Switchable Adhesives
Oct 27, 2022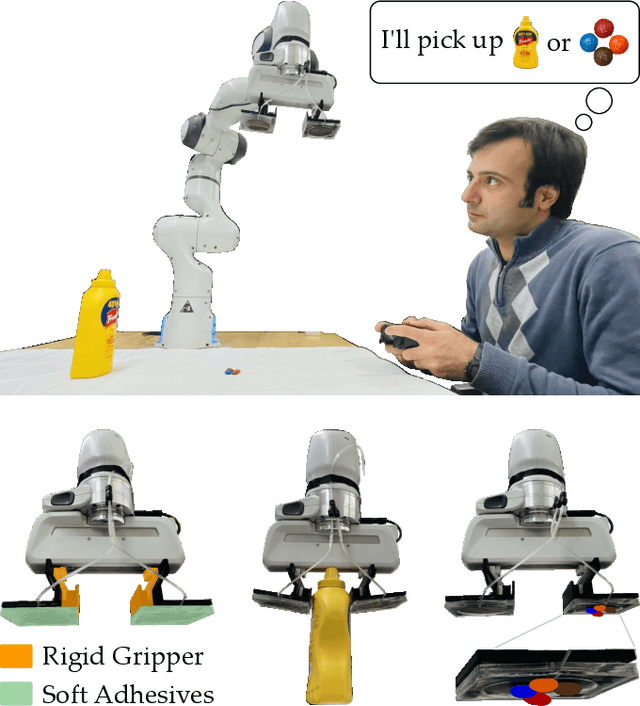
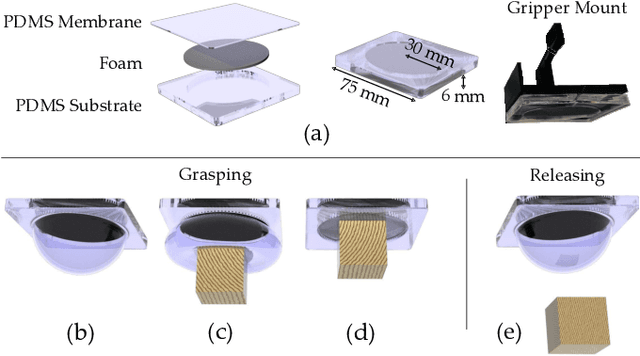
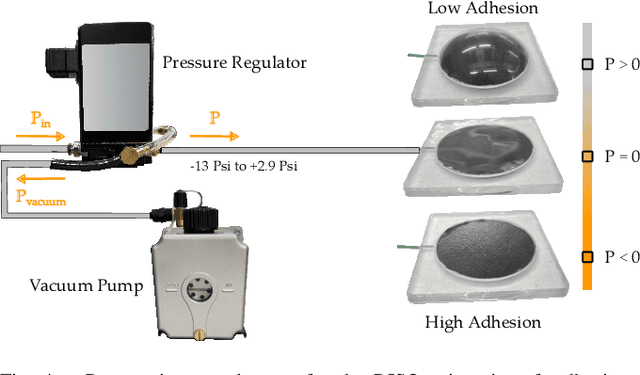
Robot arms that assist humans should be able to pick up, move, and release everyday objects. Today's assistive robot arms use rigid grippers to pinch items between fingers; while these rigid grippers are well suited for large and heavy objects, they often struggle to grasp small, numerous, or delicate items (such as foods). Soft grippers cover the opposite end of the spectrum; these grippers use adhesives or change shape to wrap around small and irregular items, but cannot exert the large forces needed to manipulate heavy objects. In this paper we introduce RIgid-SOft (RISO) grippers that combine switchable soft adhesives with standard rigid mechanisms to enable a diverse range of robotic grasping. We develop RISO grippers by leveraging a novel class of soft materials that change adhesion force in real-time through pneumatically controlled shape and rigidity tuning. By mounting these soft adhesives on the bottom of rigid fingers, we create a gripper that can interact with objects using either purely rigid grasps (pinching the object) or purely soft grasps (adhering to the object). This increased capability requires additional decision making, and we therefore formulate a shared control approach that partially automates the motion of the robot arm. In practice, this controller aligns the RISO gripper while inferring which object the human wants to grasp and how the human wants to grasp that item. Our user study demonstrates that RISO grippers can pick up, move, and release household items from existing datasets, and that the system performs grasps more successfully and efficiently when sharing control between the human and robot. See videos here: https://youtu.be/5uLUkBYcnwg